 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayeringDiff: Layered Image Synthesis via Generation, then Disassembly with Generative Knowledge
Jan 02, 2025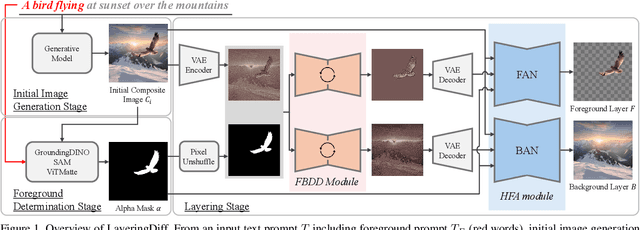

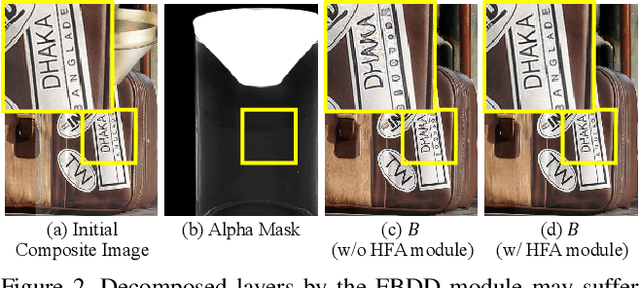

Layers have become indispensable tools for professional artists, allowing them to build a hierarchical structure that enables independent control over individual visual elements. In this paper, we propose LayeringDiff, a novel pipeline for the synthesis of layered images, which begins by generating a composite image using an off-the-shelf image generative model, followed by disassembling the image into its constituent foreground and background layers. By extracting layers from a composite image, rather than generating them from scratch, LayeringDiff bypasses the need for large-scale training to develop generative capabilities for individual layers. Furthermore, by utilizing a pretrained off-the-shelf generative model, our method can produce diverse contents and object scales in synthesized layers. For effective layer decomposition, we adapt a large-scale pretrained generative prior to estimate foreground and background layers. We also propose high-frequency alignment modules to refine the fine-details of the estimated layers. Our comprehensive experiments demonstrate that our approach effectively synthesizes layered images and supports various practical applications.
CoVA: Exploiting Compressed-Domain Analysis to Accelerate Video Analytics
Jul 02, 2022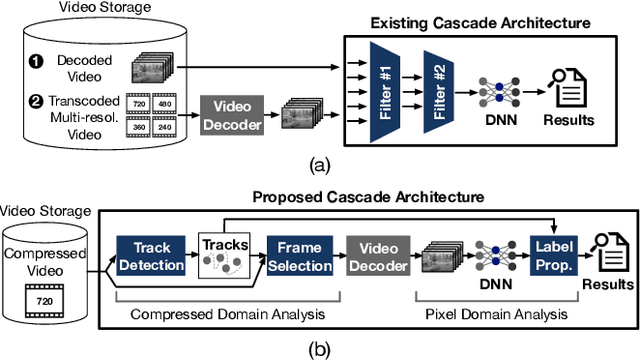
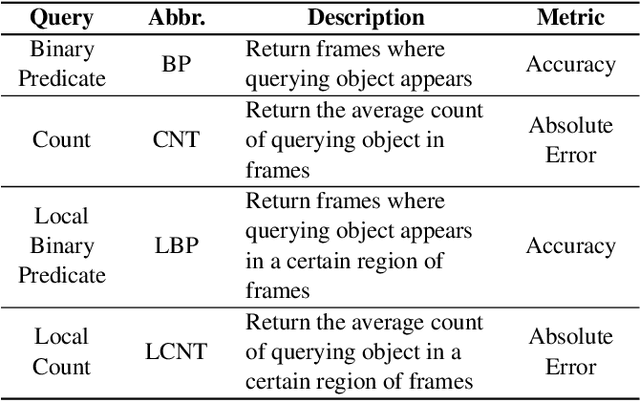
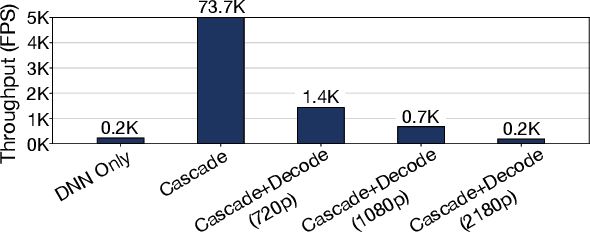

Modern retrospective analytics systems leverage cascade architecture to mitigate bottleneck for computing deep neural networks (DNNs). However, the existing cascades suffer two limitations: (1) decoding bottleneck is either neglected or circumvented, paying significant compute and storage cost for pre-processing; and (2) the systems are specialized for temporal queries and lack spatial query support. This paper presents CoVA, a novel cascade architecture that splits the cascade computation between compressed domain and pixel domain to address the decoding bottleneck, supporting both temporal and spatial queries. CoVA cascades analysis into three major stages where the first two stages are performed in compressed domain while the last one in pixel domain. First, CoVA detects occurrences of moving objects (called blobs) over a set of compressed frames (called tracks). Then, using the track results, CoVA prudently selects a minimal set of frames to obtain the label information and only decode them to compute the full DNNs, alleviating the decoding bottleneck. Lastly, CoVA associates tracks with labels to produce the final analysis results on which users can process both temporal and spatial queries. Our experiments demonstrate that CoVA offers 4.8x throughput improvement over modern cascade systems, while imposing modest accuracy loss.