 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation? A Comparative Study on the Cross-Lingual Transfer of Composite Harms
Feb 08, 2026Most safety evaluations of large language models (LLMs) remain anchored in English. Translation is often used as a shortcut to probe multilingual behavior, but it rarely captures the full picture, especially when harmful intent or structure morphs across languages. Some types of harm survive translation almost intact, while others distort or disappear. To study this effect, we introduce CompositeHarm, a translation-based benchmark designed to examine how safety alignment holds up as both syntax and semantics shift. It combines two complementary English datasets, AttaQ, which targets structured adversarial attacks, and MMSafetyBench, which covers contextual, real-world harms, and extends them into six languages: English, Hindi, Assamese, Marathi, Kannada, and Gujarati. Using three large models, we find that attack success rates rise sharply in Indic languages, especially under adversarial syntax, while contextual harms transfer more moderately. To ensure scalability and energy efficiency, our study adopts lightweight inference strategies inspired by edge-AI design principles, reducing redundant evaluation passes while preserving cross-lingual fidelity. This design makes large-scale multilingual safety testing both computationally feasible and environmentally conscious. Overall, our results show that translated benchmarks are a necessary first step, but not a sufficient one, toward building grounded, resource-aware, language-adaptive safety systems.
Pay for Hints, Not Answers: LLM Shepherding for Cost-Efficient Inference
Jan 29, 2026Large Language Models (LLMs) deliver state-of-the-art performance on complex reasoning tasks, but their inference costs limit deployment at scale. Small Language Models (SLMs) offer dramatic cost savings yet lag substantially in accuracy. Existing approaches - routing and cascading - treat the LLM as an all-or-nothing resource: either the query bypasses the LLM entirely, or the LLM generates a complete response at full cost. We introduce LLM Shepherding, a framework that requests only a short prefix (a hint) from the LLM and provides it to SLM. This simple mechanism is surprisingly effective for math and coding tasks: even hints comprising 10-30% of the full LLM response improve SLM accuracy significantly. Shepherding generalizes both routing and cascading, and it achieves lower cost under oracle decision-making. We develop a two-stage predictor that jointly determines whether a hint is needed and how many tokens to request. On the widely-used mathematical reasoning (GSM8K, CNK12) and code generation (HumanEval, MBPP) benchmarks, Shepherding reduces costs by 42-94% relative to LLM-only inference. Compared to state-of-the-art routing and cascading baselines, shepherding delivers up to 2.8x cost reduction while matching accuracy. To our knowledge, this is the first work to exploit token-level budget control for SLM-LLM collaboration.
Neo: Real-Time On-Device 3D Gaussian Splatting with Reuse-and-Update Sorting Acceleration
Nov 17, 2025



3D Gaussian Splatting (3DGS) rendering in real-time on resource-constrained devices is essential for delivering immersive augmented and virtual reality (AR/VR) experiences. However, existing solutions struggle to achieve high frame rates, especially for high-resolution rendering. Our analysis identifies the sorting stage in the 3DGS rendering pipeline as the major bottleneck due to its high memory bandwidth demand. This paper presents Neo, which introduces a reuse-and-update sorting algorithm that exploits temporal redundancy in Gaussian ordering across consecutive frames, and devises a hardware accelerator optimized for this algorithm. By efficiently tracking and updating Gaussian depth ordering instead of re-sorting from scratch, Neo significantly reduces redundant computations and memory bandwidth pressure. Experimental results show that Neo achieves up to 10.0x and 5.6x higher throughput than state-of-the-art edge GPU and ASIC solution, respectively, while reducing DRAM traffic by 94.5% and 81.3%. These improvements make high-quality and low-latency on-device 3D rendering more practical.
DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics
Mar 21, 2024Deep neural network (DNN) video analytics is crucial for autonomous systems such as self-driving vehicles, unmanned aerial vehicles (UAVs), and security robots. However, real-world deployment faces challenges due to their limited computational resources and battery power. To tackle these challenges, continuous learning exploits a lightweight "student" model at deployment (inference), leverages a larger "teacher" model for labeling sampled data (labeling), and continuously retrains the student model to adapt to changing scenarios (retraining). This paper highlights the limitations in state-of-the-art continuous learning systems: (1) they focus on computations for retraining, while overlooking the compute needs for inference and labeling, (2) they rely on power-hungry GPUs, unsuitable for battery-operated autonomous systems, and (3) they are located on a remote centralized server, intended for multi-tenant scenarios, again unsuitable for autonomous systems due to privacy, network availability, and latency concerns. We propose a hardware-algorithm co-designed solution for continuous learning, DaCapo, that enables autonomous systems to perform concurrent executions of inference, labeling, and training in a performant and energy-efficient manner. DaCapo comprises (1) a spatially-partitionable and precision-flexible accelerator enabling parallel execution of kernels on sub-accelerators at their respective precisions, and (2) a spatiotemporal resource allocation algorithm that strategically navigates the resource-accuracy tradeoff space, facilitating optimal decisions for resource allocation to achieve maximal accuracy. Our evaluation shows that DaCapo achieves 6.5% and 5.5% higher accuracy than a state-of-the-art GPU-based continuous learning systems, Ekya and EOMU, respectively, while consuming 254x less power.
CoVA: Exploiting Compressed-Domain Analysis to Accelerate Video Analytics
Jul 02, 2022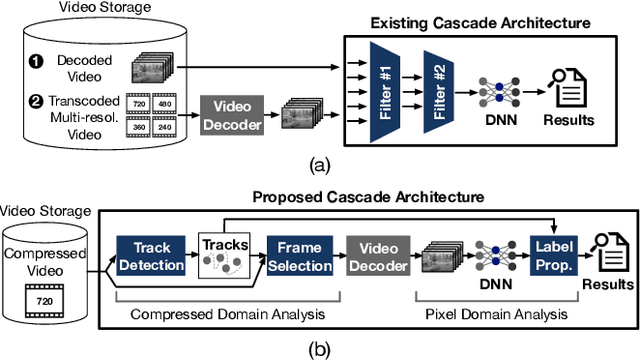
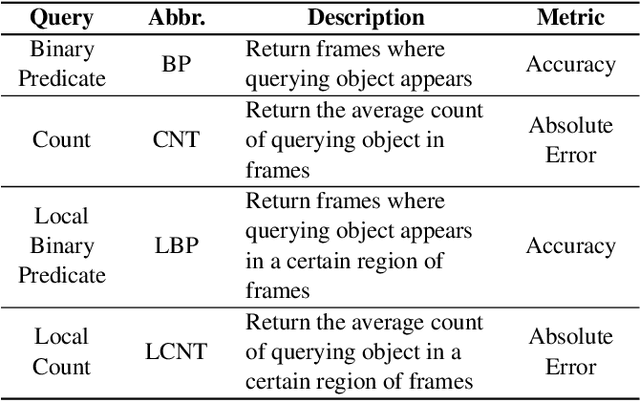
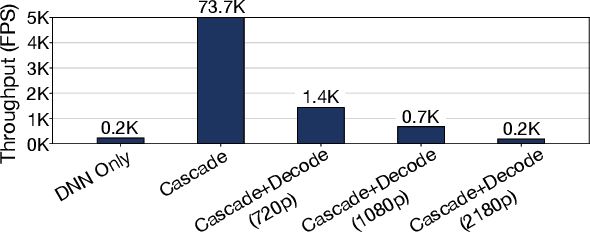

Modern retrospective analytics systems leverage cascade architecture to mitigate bottleneck for computing deep neural networks (DNNs). However, the existing cascades suffer two limitations: (1) decoding bottleneck is either neglected or circumvented, paying significant compute and storage cost for pre-processing; and (2) the systems are specialized for temporal queries and lack spatial query support. This paper presents CoVA, a novel cascade architecture that splits the cascade computation between compressed domain and pixel domain to address the decoding bottleneck, supporting both temporal and spatial queries. CoVA cascades analysis into three major stages where the first two stages are performed in compressed domain while the last one in pixel domain. First, CoVA detects occurrences of moving objects (called blobs) over a set of compressed frames (called tracks). Then, using the track results, CoVA prudently selects a minimal set of frames to obtain the label information and only decode them to compute the full DNNs, alleviating the decoding bottleneck. Lastly, CoVA associates tracks with labels to produce the final analysis results on which users can process both temporal and spatial queries. Our experiments demonstrate that CoVA offers 4.8x throughput improvement over modern cascade systems, while imposing modest accuracy loss.
Bit-Parallel Vector Composability for Neural Acceleration
Apr 11, 2020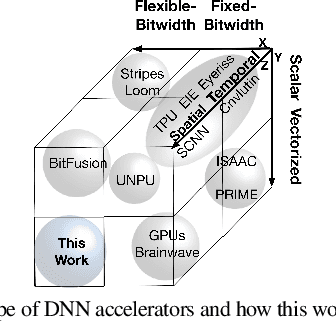
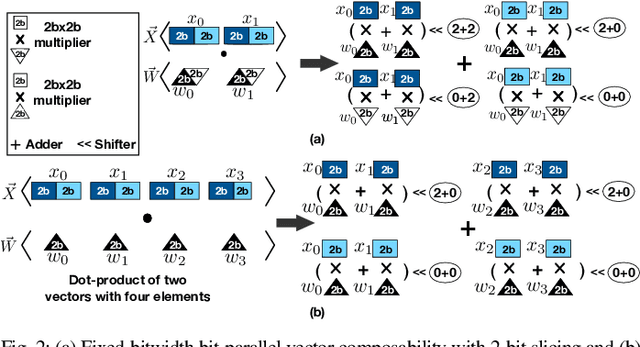
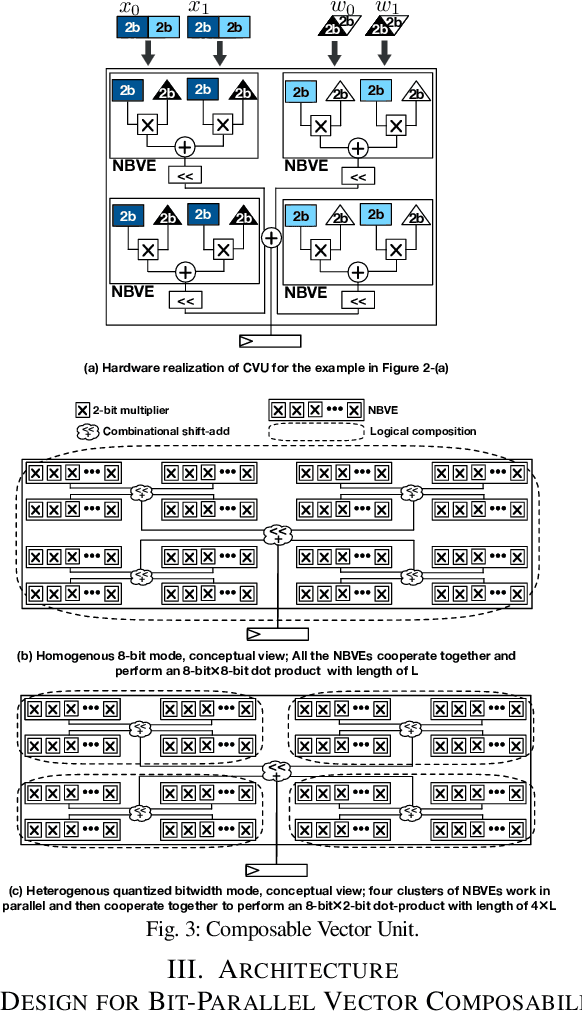
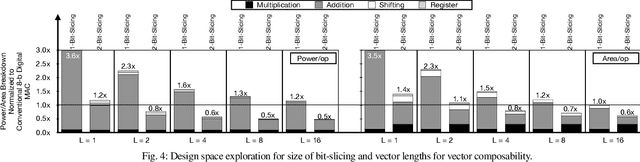
Conventional neural accelerators rely on isolated self-sufficient functional units that perform an atomic operation while communicating the results through an operand delivery-aggregation logic. Each single unit processes all the bits of their operands atomically and produce all the bits of the results in isolation. This paper explores a different design style, where each unit is only responsible for a slice of the bit-level operations to interleave and combine the benefits of bit-level parallelism with the abundant data-level parallelism in deep neural networks. A dynamic collection of these units cooperate at runtime to generate bits of the results, collectively. Such cooperation requires extracting new grouping between the bits, which is only possible if the operands and operations are vectorizable. The abundance of Data Level Parallelism and mostly repeated execution patterns, provides a unique opportunity to define and leverage this new dimension of Bit-Parallel Vector Composability. This design intersperses bit parallelism within data-level parallelism and dynamically interweaves the two together. As such, the building block of our neural accelerator is a Composable Vector Unit that is a collection of Narrower-Bitwidth Vector Engines, which are dynamically composed or decomposed at the bit granularity. Using six diverse CNN and LSTM deep networks, we evaluate this design style across four design points: with and without algorithmic bitwidth heterogeneity and with and without availability of a high-bandwidth off-chip memory. Across these four design points, Bit-Parallel Vector Composability brings (1.4x to 3.5x) speedup and (1.1x to 2.7x) energy reduction. We also comprehensively compare our design style to the Nvidia RTX 2080 TI GPU, which also supports INT-4 execution. The benefits range between 28.0x and 33.7x improvement in Performance-per-Watt.
Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
May 30, 2018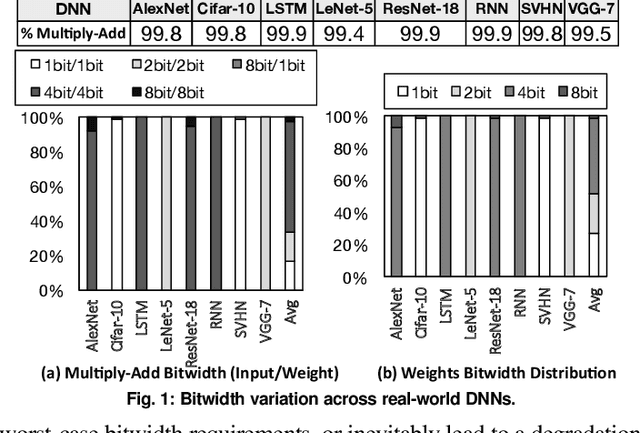
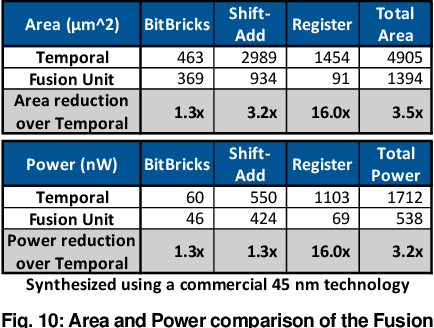
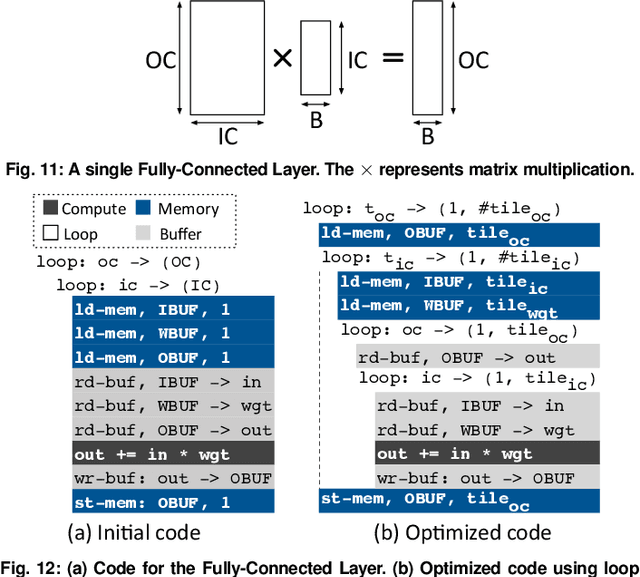
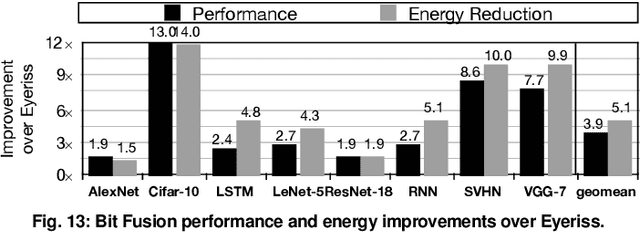
Fully realizing the potential of acceleration for Deep Neural Networks (DNNs) requires understanding and leveraging algorithmic properties. This paper builds upon the algorithmic insight that bitwidth of operations in DNNs can be reduced without compromising their classification accuracy. However, to prevent accuracy loss, the bitwidth varies significantly across DNNs and it may even be adjusted for each layer. Thus, a fixed-bitwidth accelerator would either offer limited benefits to accommodate the worst-case bitwidth requirements, or lead to a degradation in final accuracy. To alleviate these deficiencies, this work introduces dynamic bit-level fusion/decomposition as a new dimension in the design of DNN accelerators. We explore this dimension by designing Bit Fusion, a bit-flexible accelerator, that constitutes an array of bit-level processing elements that dynamically fuse to match the bitwidth of individual DNN layers. This flexibility in the architecture enables minimizing the computation and the communication at the finest granularity possible with no loss in accuracy. We evaluate the benefits of BitFusion using eight real-world feed-forward and recurrent DNNs. The proposed microarchitecture is implemented in Verilog and synthesized in 45 nm technology. Using the synthesis results and cycle accurate simulation, we compare the benefits of Bit Fusion to two state-of-the-art DNN accelerators, Eyeriss and Stripes. In the same area, frequency, and process technology, BitFusion offers 3.9x speedup and 5.1x energy savings over Eyeriss. Compared to Stripes, BitFusion provides 2.6x speedup and 3.9x energy reduction at 45 nm node when BitFusion area and frequency are set to those of Stripes. Scaling to GPU technology node of 16 nm, BitFusion almost matches the performance of a 250-Watt Titan Xp, which uses 8-bit vector instructions, while BitFusion merely consumes 895 milliwatts of power.