 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source ML-Based Full-Stack Optimization Framework for Machine Learning Accelerators
Aug 23, 2023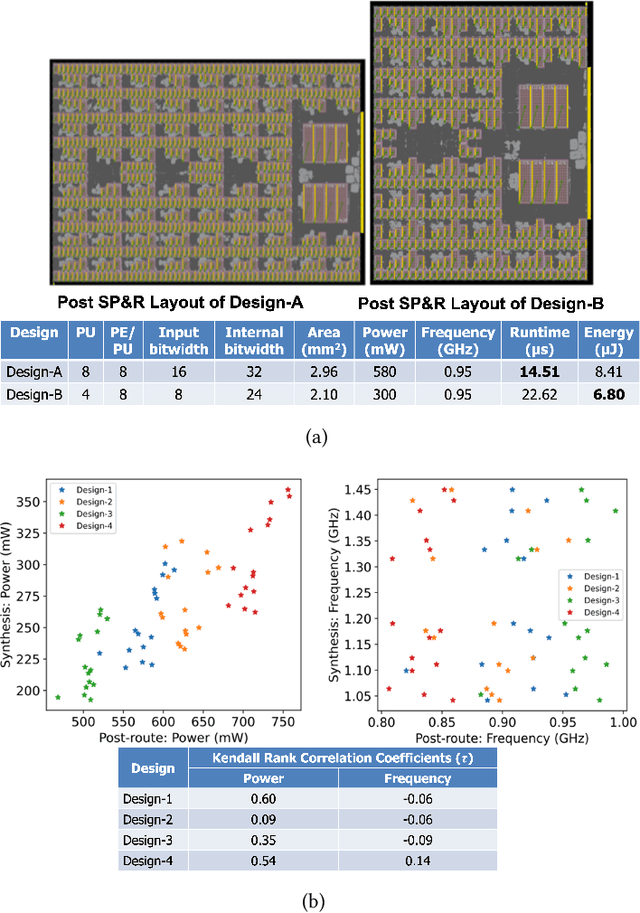
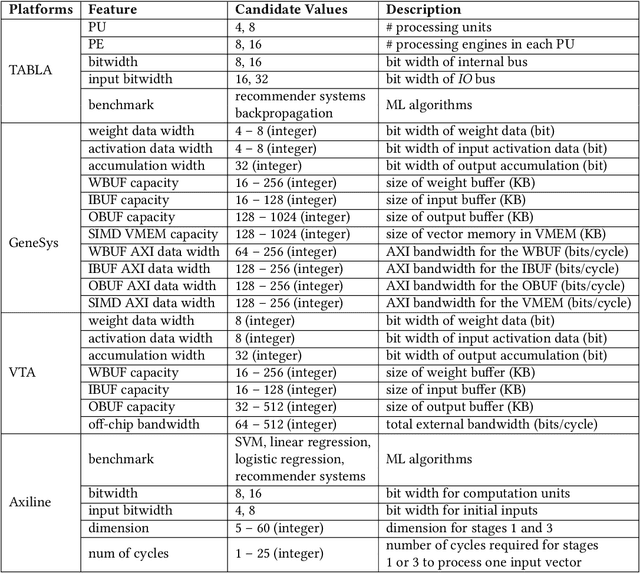
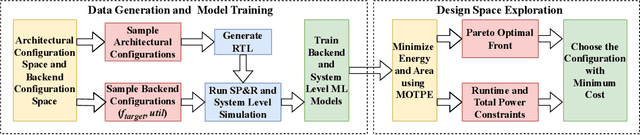
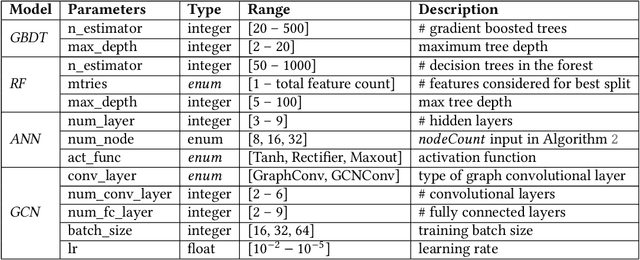
Parameterizable machine learning (ML) accelerators are the product of recent breakthroughs in ML. To fully enable their design space exploration (DSE), we propose a physical-design-driven, learning-based prediction framework for hardware-accelerated deep neural network (DNN) and non-DNN ML algorithms. It adopts a unified approach that combines backend power, performance, and area (PPA) analysis with frontend performance simulation, thereby achieving a realistic estimation of both backend PPA and system metrics such as runtime and energy. In addition, our framework includes a fully automated DSE technique, which optimizes backend and system metrics through an automated search of architectural and backend parameters. Experimental studies show that our approach consistently predicts backend PPA and system metrics with an average 7% or less prediction error for the ASIC implementation of two deep learning accelerator platforms, VTA and VeriGOOD-ML, in both a commercial 12 nm process and a research-oriented 45 nm process.
In-RDBMS Hardware Acceleration of Advanced Analytics
Sep 18, 2018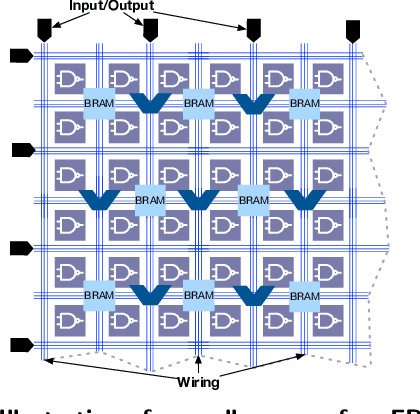
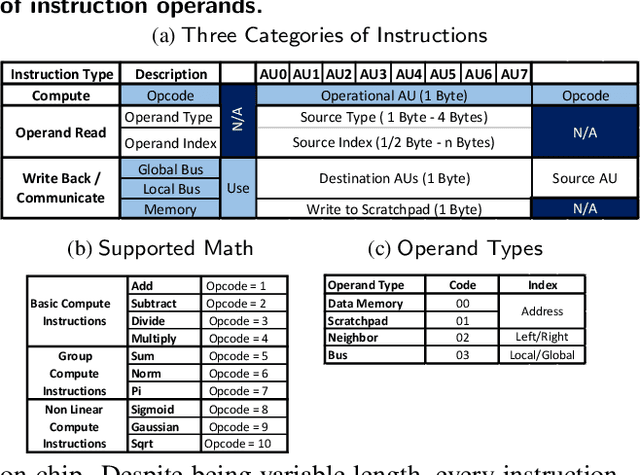
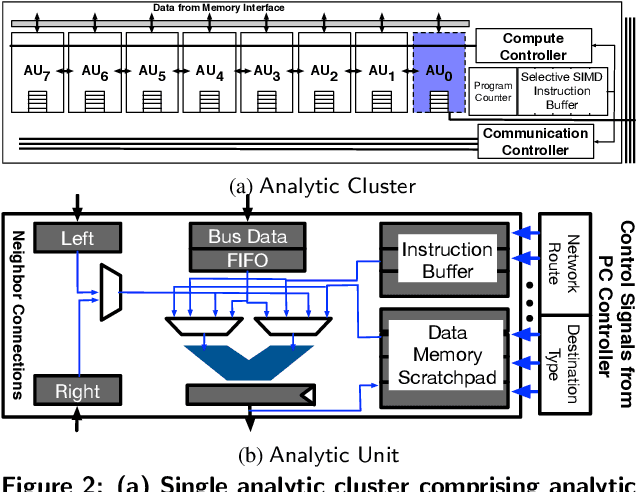

The data revolution is fueled by advances in machine learning, databases, and hardware design. Programmable accelerators are making their way into each of these areas independently. As such, there is a void of solutions that enables hardware acceleration at the intersection of these disjoint fields. This paper sets out to be the initial step towards a unifying solution for in-Database Acceleration of Advanced Analytics (DAnA). Deploying specialized hardware, such as FPGAs, for in-database analytics currently requires hand-designing the hardware and manually routing the data. Instead, DAnA automatically maps a high-level specification of advanced analytics queries to an FPGA accelerator. The accelerator implementation is generated for a User Defined Function (UDF), expressed as a part of an SQL query using a Python-embedded Domain-Specific Language (DSL). To realize an efficient in-database integration, DAnA accelerators contain a novel hardware structure, Striders, that directly interface with the buffer pool of the database. Striders extract, cleanse, and process the training data tuples that are consumed by a multi-threaded FPGA engine that executes the analytics algorithm. We integrate DAnA with PostgreSQL to generate hardware accelerators for a range of real-world and synthetic datasets running diverse ML algorithms. Results show that DAnA-enhanced PostgreSQL provides, on average, 8.3x end-to-end speedup for real datasets, with a maximum of 28.2x. Moreover, DAnA-enhanced PostgreSQL is, on average, 4.0x faster than the multi-threaded Apache MADLib running on Greenplum. DAnA provides these benefits while hiding the complexity of hardware design from data scientists and allowing them to express the algorithm in =30-60 lines of Python.
Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
May 30, 2018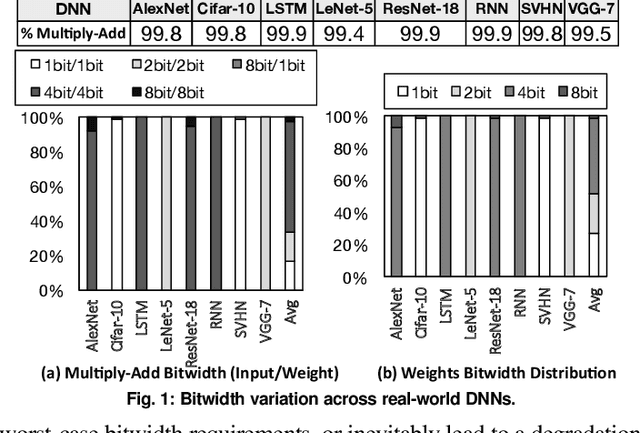
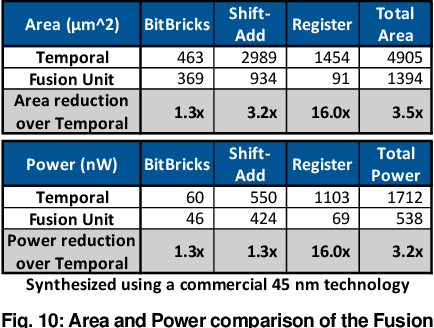
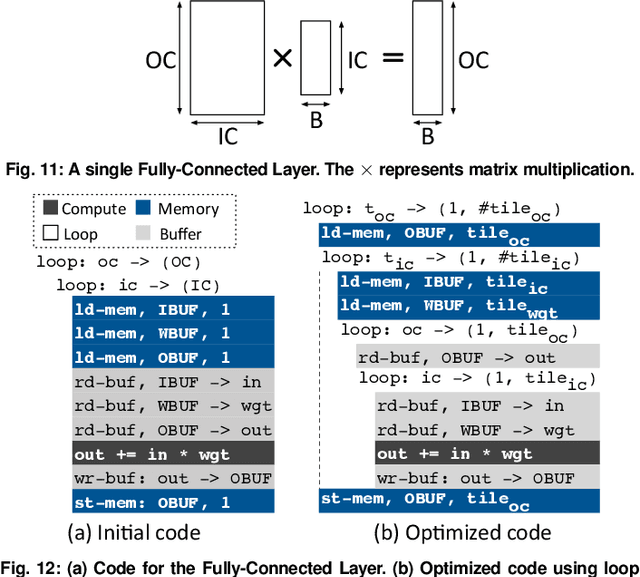
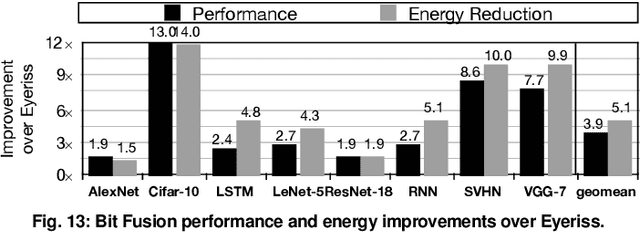
Fully realizing the potential of acceleration for Deep Neural Networks (DNNs) requires understanding and leveraging algorithmic properties. This paper builds upon the algorithmic insight that bitwidth of operations in DNNs can be reduced without compromising their classification accuracy. However, to prevent accuracy loss, the bitwidth varies significantly across DNNs and it may even be adjusted for each layer. Thus, a fixed-bitwidth accelerator would either offer limited benefits to accommodate the worst-case bitwidth requirements, or lead to a degradation in final accuracy. To alleviate these deficiencies, this work introduces dynamic bit-level fusion/decomposition as a new dimension in the design of DNN accelerators. We explore this dimension by designing Bit Fusion, a bit-flexible accelerator, that constitutes an array of bit-level processing elements that dynamically fuse to match the bitwidth of individual DNN layers. This flexibility in the architecture enables minimizing the computation and the communication at the finest granularity possible with no loss in accuracy. We evaluate the benefits of BitFusion using eight real-world feed-forward and recurrent DNNs. The proposed microarchitecture is implemented in Verilog and synthesized in 45 nm technology. Using the synthesis results and cycle accurate simulation, we compare the benefits of Bit Fusion to two state-of-the-art DNN accelerators, Eyeriss and Stripes. In the same area, frequency, and process technology, BitFusion offers 3.9x speedup and 5.1x energy savings over Eyeriss. Compared to Stripes, BitFusion provides 2.6x speedup and 3.9x energy reduction at 45 nm node when BitFusion area and frequency are set to those of Stripes. Scaling to GPU technology node of 16 nm, BitFusion almost matches the performance of a 250-Watt Titan Xp, which uses 8-bit vector instructions, while BitFusion merely consumes 895 milliwatts of power.