 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source ML-Based Full-Stack Optimization Framework for Machine Learning Accelerators
Aug 23, 2023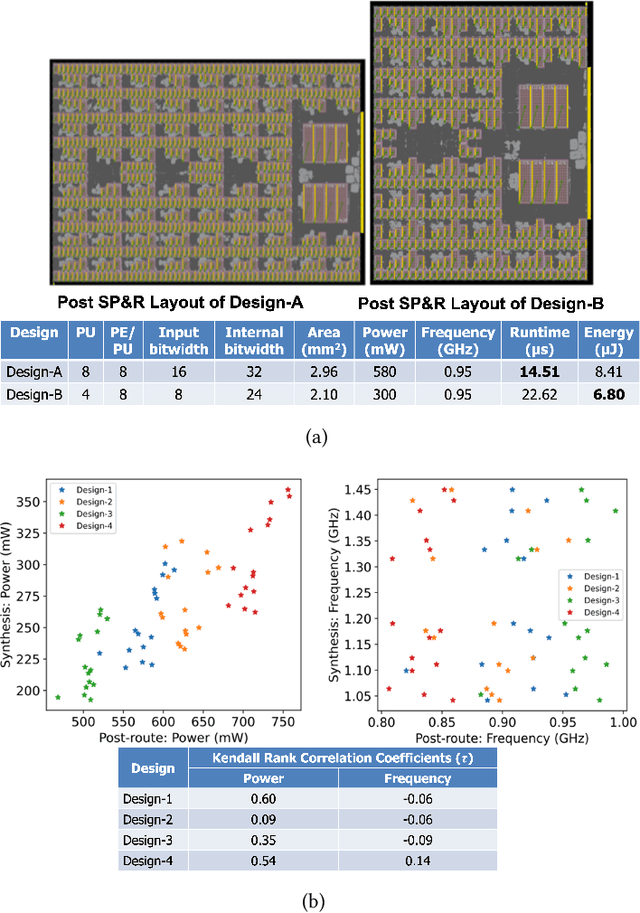
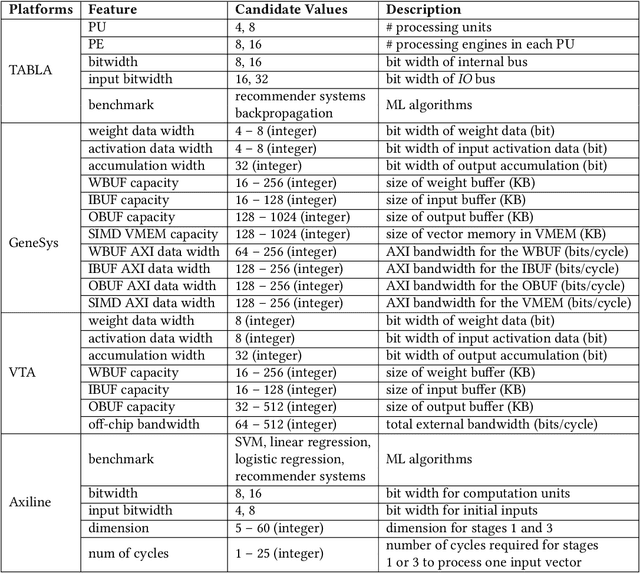
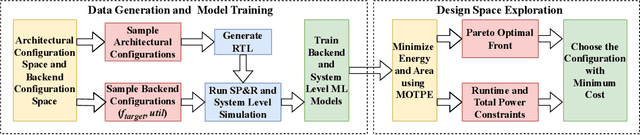
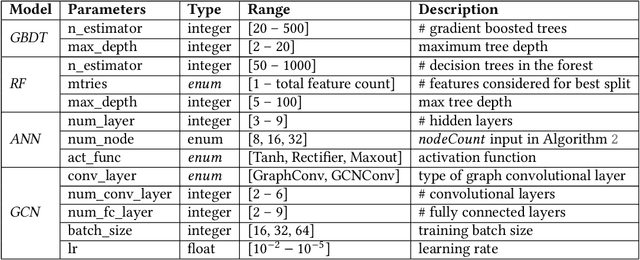
Parameterizable machine learning (ML) accelerators are the product of recent breakthroughs in ML. To fully enable their design space exploration (DSE), we propose a physical-design-driven, learning-based prediction framework for hardware-accelerated deep neural network (DNN) and non-DNN ML algorithms. It adopts a unified approach that combines backend power, performance, and area (PPA) analysis with frontend performance simulation, thereby achieving a realistic estimation of both backend PPA and system metrics such as runtime and energy. In addition, our framework includes a fully automated DSE technique, which optimizes backend and system metrics through an automated search of architectural and backend parameters. Experimental studies show that our approach consistently predicts backend PPA and system metrics with an average 7% or less prediction error for the ASIC implementation of two deep learning accelerator platforms, VTA and VeriGOOD-ML, in both a commercial 12 nm process and a research-oriented 45 nm process.
Performance Analysis of DNN Inference/Training with Convolution and non-Convolution Operations
Jun 29, 2023Today's performance analysis frameworks for deep learning accelerators suffer from two significant limitations. First, although modern convolutional neural network (CNNs) consist of many types of layers other than convolution, especially during training, these frameworks largely focus on convolution layers only. Second, these frameworks are generally targeted towards inference, and lack support for training operations. This work proposes a novel performance analysis framework, SimDIT, for general ASIC-based systolic hardware accelerator platforms. The modeling effort of SimDIT comprehensively covers convolution and non-convolution operations of both CNN inference and training on a highly parameterizable hardware substrate. SimDIT is integrated with a backend silicon implementation flow and provides detailed end-to-end performance statistics (i.e., data access cost, cycle counts, energy, and power) for executing CNN inference and training workloads. SimDIT-enabled performance analysis reveals that on a 64X64 processing array, non-convolution operations constitute 59.5% of total runtime for ResNet-50 training workload. In addition, by optimally distributing available off-chip DRAM bandwidth and on-chip SRAM resources, SimDIT achieves 18X performance improvement over a generic static resource allocation for ResNet-50 inference.
Accelerating Attention through Gradient-Based Learned Runtime Pruning
Apr 15, 2022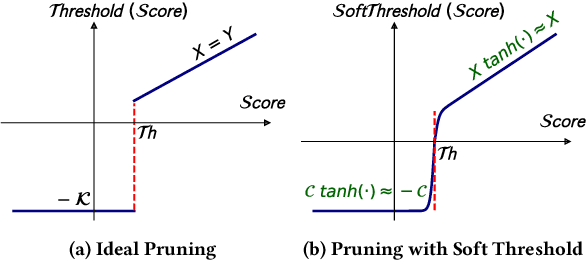



Self-attention is a key enabler of state-of-art accuracy for various transformer-based Natural Language Processing models. This attention mechanism calculates a correlation score for each word with respect to the other words in a sentence. Commonly, only a small subset of words highly correlates with the word under attention, which is only determined at runtime. As such, a significant amount of computation is inconsequential due to low attention scores and can potentially be pruned. The main challenge is finding the threshold for the scores below which subsequent computation will be inconsequential. Although such a threshold is discrete, this paper formulates its search through a soft differentiable regularizer integrated into the loss function of the training. This formulation piggy backs on the back-propagation training to analytically co-optimize the threshold and the weights simultaneously, striking a formally optimal balance between accuracy and computation pruning. To best utilize this mathematical innovation, we devise a bit-serial architecture, dubbed LeOPArd, for transformer language models with bit-level early termination microarchitectural mechanism. We evaluate our design across 43 back-end tasks for MemN2N, BERT, ALBERT, GPT-2, and Vision transformer models. Post-layout results show that, on average, LeOPArd yields 1.9x and 3.9x speedup and energy reduction, respectively, while keeping the average accuracy virtually intact (<0.2% degradation)
Bit-Parallel Vector Composability for Neural Acceleration
Apr 11, 2020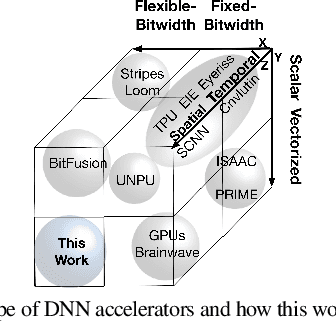
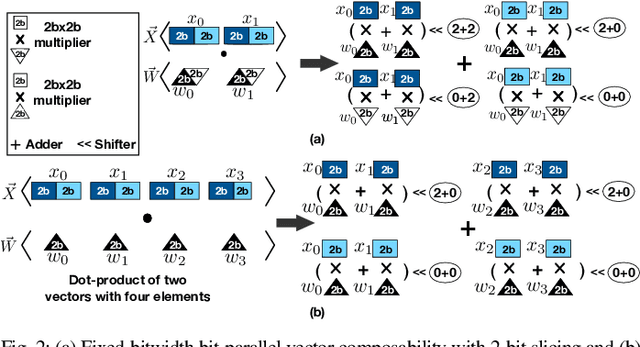
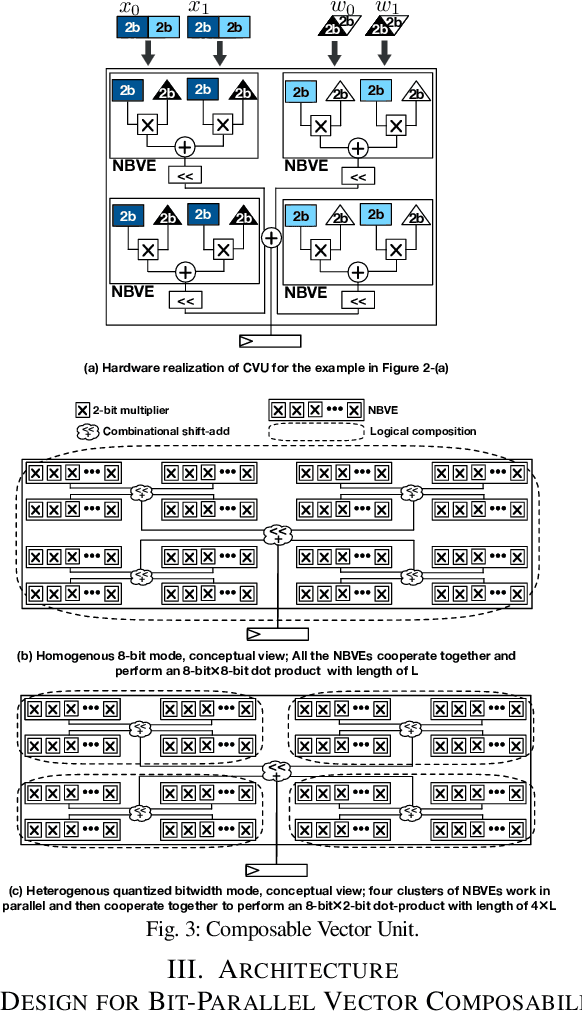
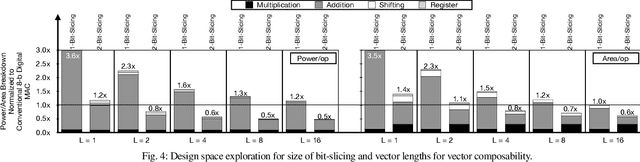
Conventional neural accelerators rely on isolated self-sufficient functional units that perform an atomic operation while communicating the results through an operand delivery-aggregation logic. Each single unit processes all the bits of their operands atomically and produce all the bits of the results in isolation. This paper explores a different design style, where each unit is only responsible for a slice of the bit-level operations to interleave and combine the benefits of bit-level parallelism with the abundant data-level parallelism in deep neural networks. A dynamic collection of these units cooperate at runtime to generate bits of the results, collectively. Such cooperation requires extracting new grouping between the bits, which is only possible if the operands and operations are vectorizable. The abundance of Data Level Parallelism and mostly repeated execution patterns, provides a unique opportunity to define and leverage this new dimension of Bit-Parallel Vector Composability. This design intersperses bit parallelism within data-level parallelism and dynamically interweaves the two together. As such, the building block of our neural accelerator is a Composable Vector Unit that is a collection of Narrower-Bitwidth Vector Engines, which are dynamically composed or decomposed at the bit granularity. Using six diverse CNN and LSTM deep networks, we evaluate this design style across four design points: with and without algorithmic bitwidth heterogeneity and with and without availability of a high-bandwidth off-chip memory. Across these four design points, Bit-Parallel Vector Composability brings (1.4x to 3.5x) speedup and (1.1x to 2.7x) energy reduction. We also comprehensively compare our design style to the Nvidia RTX 2080 TI GPU, which also supports INT-4 execution. The benefits range between 28.0x and 33.7x improvement in Performance-per-Watt.