 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated QoR improvement in OpenROAD with coding agents
Jan 09, 2026EDA development and innovation has been constrained by scarcity of expert engineering resources. While leading LLMs have demonstrated excellent performance in coding and scientific reasoning tasks, their capacity to advance EDA technology itself has been largely untested. We present AuDoPEDA, an autonomous, repository-grounded coding system built atop OpenAI models and a Codex-class agent that reads OpenROAD, proposes research directions, expands them into implementation steps, and submits executable diffs. Our contributions include (i) a closed-loop LLM framework for EDA code changes; (ii) a task suite and evaluation protocol on OpenROAD for PPA-oriented improvements; and (iii) end-to-end demonstrations with minimal human oversight. Experiments in OpenROAD achieve routed wirelength reductions of up to 5.9%, and effective clock period reductions of up to 10.0%.
ORFS-agent: Tool-Using Agents for Chip Design Optimization
Jun 10, 2025Machine learning has been widely used to optimize complex engineering workflows across numerous domains. In the context of integrated circuit design, modern flows (e.g., going from a register-transfer level netlist to physical layouts) involve extensive configuration via thousands of parameters, and small changes to these parameters can have large downstream impacts on desired outcomes - namely design performance, power, and area. Recent advances in Large Language Models (LLMs) offer new opportunities for learning and reasoning within such high-dimensional optimization tasks. In this work, we introduce ORFS-agent, an LLM-based iterative optimization agent that automates parameter tuning in an open-source hardware design flow. ORFS-agent adaptively explores parameter configurations, demonstrating clear improvements over standard Bayesian optimization approaches in terms of resource efficiency and final design metrics. Our empirical evaluations on two different technology nodes and a range of circuit benchmarks indicate that ORFS-agent can improve both routed wirelength and effective clock period by over 13%, all while using 40% fewer optimization iterations. Moreover, by following natural language objectives to trade off certain metrics for others, ORFS-agent demonstrates a flexible and interpretable framework for multi-objective optimization. Crucially, RFS-agent is modular and model-agnostic, and can be plugged in to any frontier LLM without any further fine-tuning.
NN-Steiner: A Mixed Neural-algorithmic Approach for the Rectilinear Steiner Minimum Tree Problem
Dec 19, 2023Recent years have witnessed rapid advances in the use of neural networks to solve combinatorial optimization problems. Nevertheless, designing the "right" neural model that can effectively handle a given optimization problem can be challenging, and often there is no theoretical understanding or justification of the resulting neural model. In this paper, we focus on the rectilinear Steiner minimum tree (RSMT) problem, which is of critical importance in IC layout design and as a result has attracted numerous heuristic approaches in the VLSI literature. Our contributions are two-fold. On the methodology front, we propose NN-Steiner, which is a novel mixed neural-algorithmic framework for computing RSMTs that leverages the celebrated PTAS algorithmic framework of Arora to solve this problem (and other geometric optimization problems). Our NN-Steiner replaces key algorithmic components within Arora's PTAS by suitable neural components. In particular, NN-Steiner only needs four neural network (NN) components that are called repeatedly within an algorithmic framework. Crucially, each of the four NN components is only of bounded size independent of input size, and thus easy to train. Furthermore, as the NN component is learning a generic algorithmic step, once learned, the resulting mixed neural-algorithmic framework generalizes to much larger instances not seen in training. Our NN-Steiner, to our best knowledge, is the first neural architecture of bounded size that has capacity to approximately solve RSMT (and variants). On the empirical front, we show how NN-Steiner can be implemented and demonstrate the effectiveness of our resulting approach, especially in terms of generalization, by comparing with state-of-the-art methods (both neural and non-neural based).
An Open-Source ML-Based Full-Stack Optimization Framework for Machine Learning Accelerators
Aug 23, 2023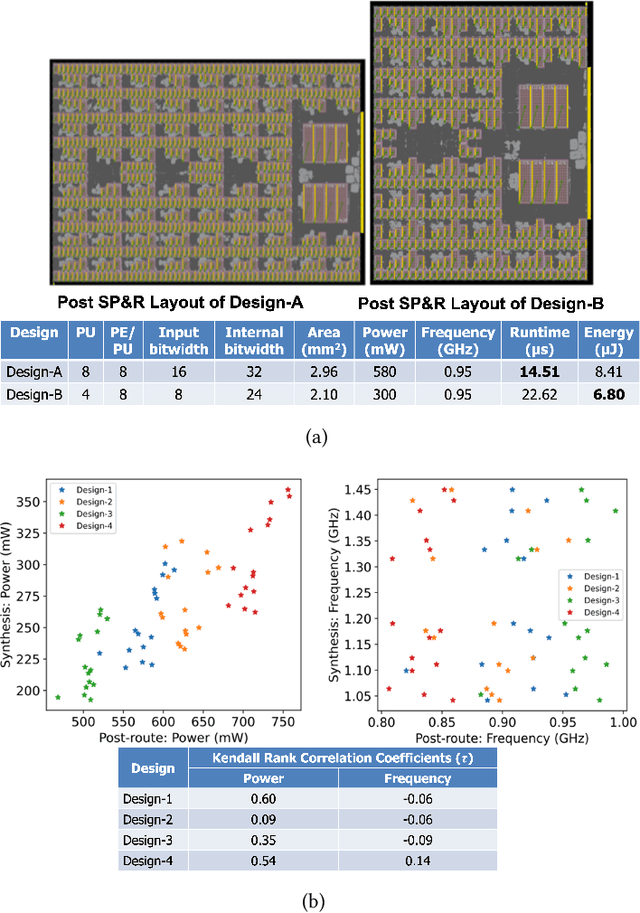
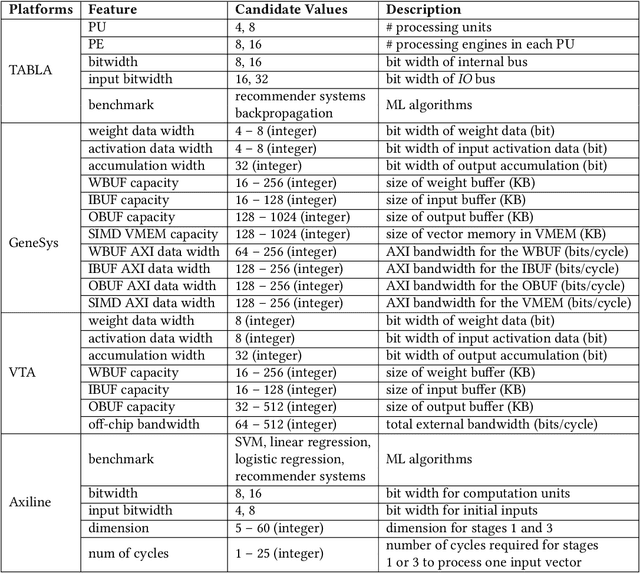
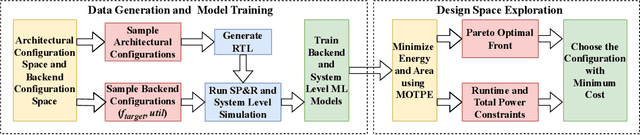
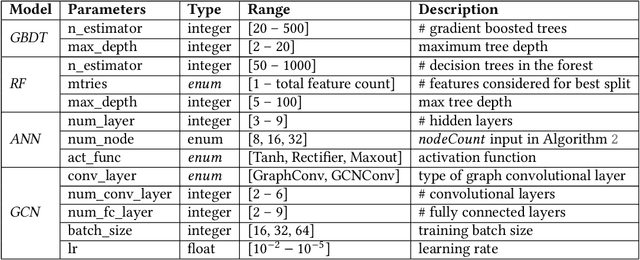
Parameterizable machine learning (ML) accelerators are the product of recent breakthroughs in ML. To fully enable their design space exploration (DSE), we propose a physical-design-driven, learning-based prediction framework for hardware-accelerated deep neural network (DNN) and non-DNN ML algorithms. It adopts a unified approach that combines backend power, performance, and area (PPA) analysis with frontend performance simulation, thereby achieving a realistic estimation of both backend PPA and system metrics such as runtime and energy. In addition, our framework includes a fully automated DSE technique, which optimizes backend and system metrics through an automated search of architectural and backend parameters. Experimental studies show that our approach consistently predicts backend PPA and system metrics with an average 7% or less prediction error for the ASIC implementation of two deep learning accelerator platforms, VTA and VeriGOOD-ML, in both a commercial 12 nm process and a research-oriented 45 nm process.
Performance Analysis of DNN Inference/Training with Convolution and non-Convolution Operations
Jun 29, 2023Today's performance analysis frameworks for deep learning accelerators suffer from two significant limitations. First, although modern convolutional neural network (CNNs) consist of many types of layers other than convolution, especially during training, these frameworks largely focus on convolution layers only. Second, these frameworks are generally targeted towards inference, and lack support for training operations. This work proposes a novel performance analysis framework, SimDIT, for general ASIC-based systolic hardware accelerator platforms. The modeling effort of SimDIT comprehensively covers convolution and non-convolution operations of both CNN inference and training on a highly parameterizable hardware substrate. SimDIT is integrated with a backend silicon implementation flow and provides detailed end-to-end performance statistics (i.e., data access cost, cycle counts, energy, and power) for executing CNN inference and training workloads. SimDIT-enabled performance analysis reveals that on a 64X64 processing array, non-convolution operations constitute 59.5% of total runtime for ResNet-50 training workload. In addition, by optimally distributing available off-chip DRAM bandwidth and on-chip SRAM resources, SimDIT achieves 18X performance improvement over a generic static resource allocation for ResNet-50 inference.
K-SpecPart: A Supervised Spectral Framework for Multi-Way Hypergraph Partitioning Solution Improvement
May 07, 2023
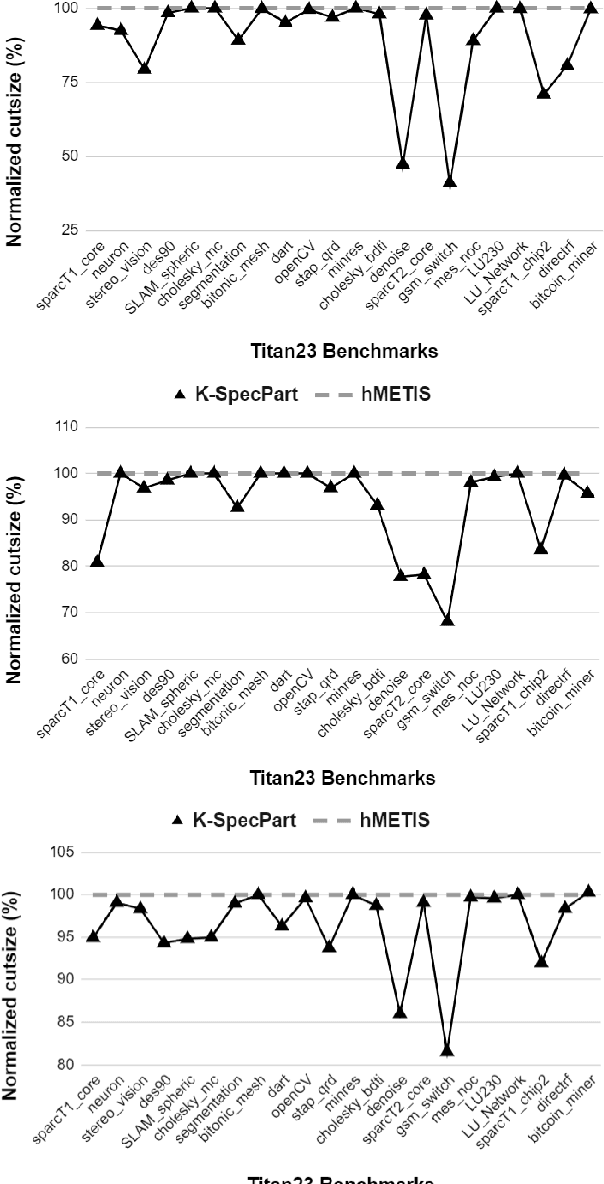
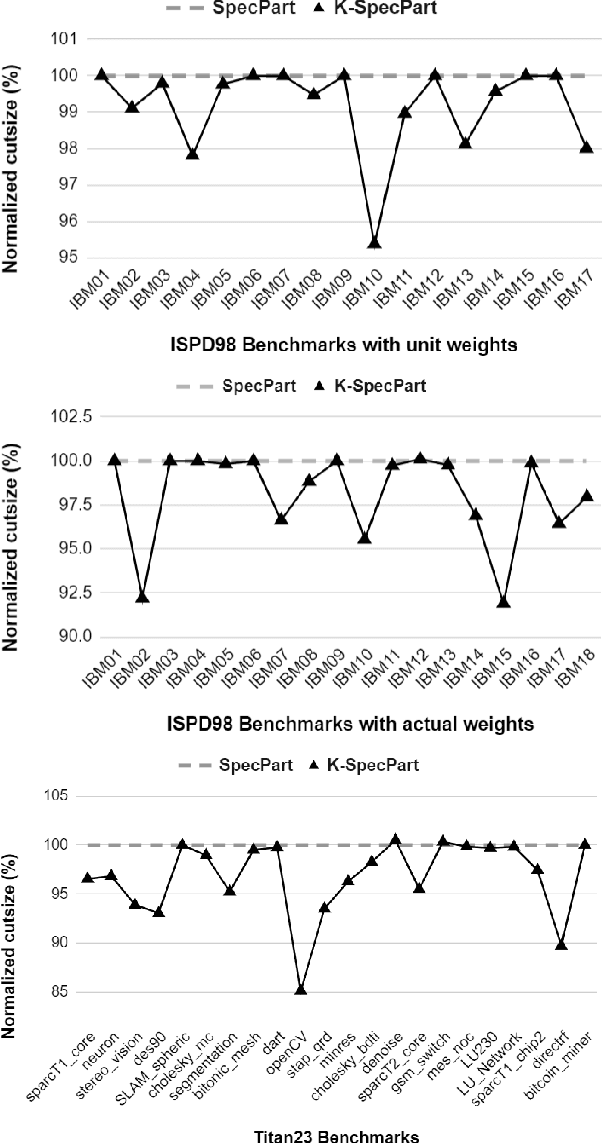
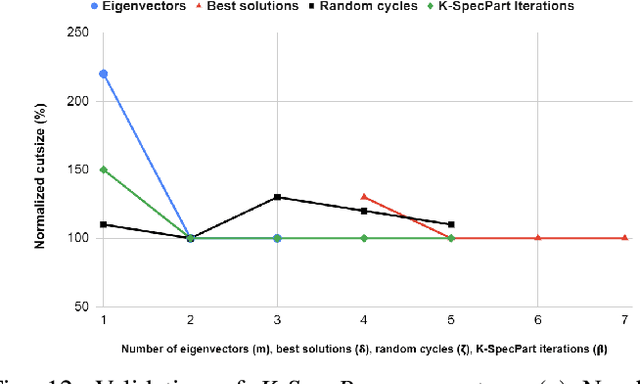
State-of-the-art hypergraph partitioners follow the multilevel paradigm, constructing multiple levels of coarser hypergraphs to drive cutsize refinement. These partitioners face limitations: (i) coarsening processes depend on local neighborhood structure, ignoring global hypergraph structure; (ii) refinement heuristics risk entrapment in local minima. We introduce K-SpecPart, a supervised spectral framework addressing these limitations by solving a generalized eigenvalue problem, capturing balanced partitioning objectives and global hypergraph structure in a low-dimensional vertex embedding while leveraging high-quality multilevel partitioning solutions as hints. In multi-way partitioning, K-SpecPart derives multiple bipartitioning solutions from a multi-way hint partitioning solution. It integrates these solutions into the generalized eigenvalue problem to compute eigenvectors, creating a large-dimensional embedding. Linear Discriminant Analysis (LDA) is used to transform this into a lower-dimensional embedding. K-SpecPart constructs a family of trees from the vertex embedding and partitions them using a tree-sweeping algorithm. We extend SpecPart's tree partitioning algorithm for multi-way partitioning. The multiple tree-based partitioning solutions are overlaid, followed by lifting to a clustered hypergraph where an integer linear programming (ILP) partitioning problem is solved. Empirical studies show K-SpecPart's benefits. For bipartitioning, K-SpecPart outperforms SpecPart with improvements up to 30%. For multi-way partitioning, K-SpecPart surpasses hMETIS and KaHyPar, with improvements up to 20% in some cases.
Assessment of Reinforcement Learning for Macro Placement
Feb 21, 2023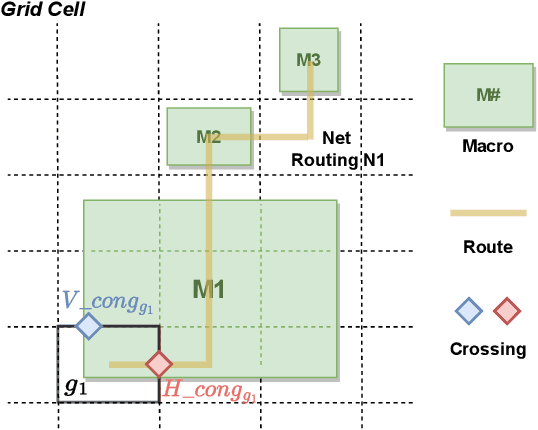
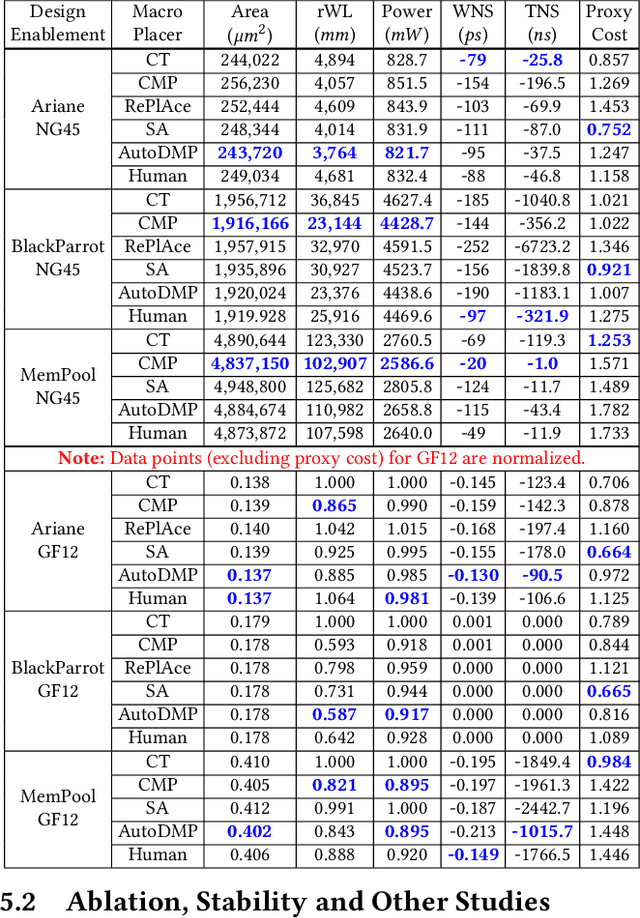
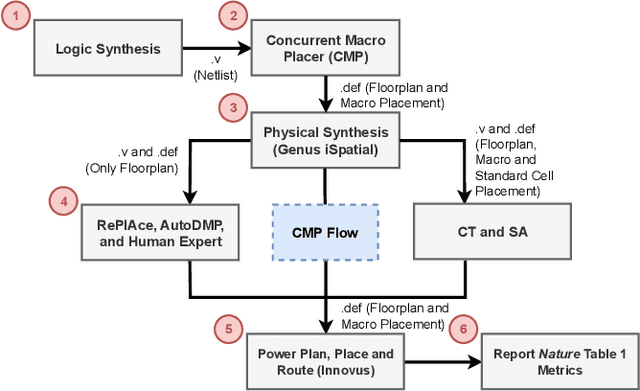
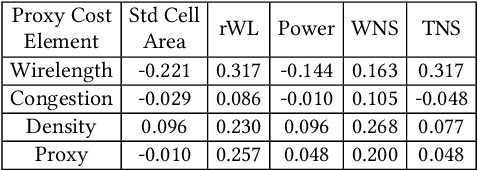
We provide open, transparent implementation and assessment of Google Brain's deep reinforcement learning approach to macro placement and its Circuit Training (CT) implementation in GitHub. We implement in open source key "blackbox" elements of CT, and clarify discrepancies between CT and Nature paper. New testcases on open enablements are developed and released. We assess CT alongside multiple alternative macro placers, with all evaluation flows and related scripts public in GitHub. Our experiments also encompass academic mixed-size placement benchmarks, as well as ablation and stability studies. We comment on the impact of Nature and CT, as well as directions for future research.