 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORFS-agent: Tool-Using Agents for Chip Design Optimization
Jun 10, 2025Machine learning has been widely used to optimize complex engineering workflows across numerous domains. In the context of integrated circuit design, modern flows (e.g., going from a register-transfer level netlist to physical layouts) involve extensive configuration via thousands of parameters, and small changes to these parameters can have large downstream impacts on desired outcomes - namely design performance, power, and area. Recent advances in Large Language Models (LLMs) offer new opportunities for learning and reasoning within such high-dimensional optimization tasks. In this work, we introduce ORFS-agent, an LLM-based iterative optimization agent that automates parameter tuning in an open-source hardware design flow. ORFS-agent adaptively explores parameter configurations, demonstrating clear improvements over standard Bayesian optimization approaches in terms of resource efficiency and final design metrics. Our empirical evaluations on two different technology nodes and a range of circuit benchmarks indicate that ORFS-agent can improve both routed wirelength and effective clock period by over 13%, all while using 40% fewer optimization iterations. Moreover, by following natural language objectives to trade off certain metrics for others, ORFS-agent demonstrates a flexible and interpretable framework for multi-objective optimization. Crucially, RFS-agent is modular and model-agnostic, and can be plugged in to any frontier LLM without any further fine-tuning.
An Open-Source ML-Based Full-Stack Optimization Framework for Machine Learning Accelerators
Aug 23, 2023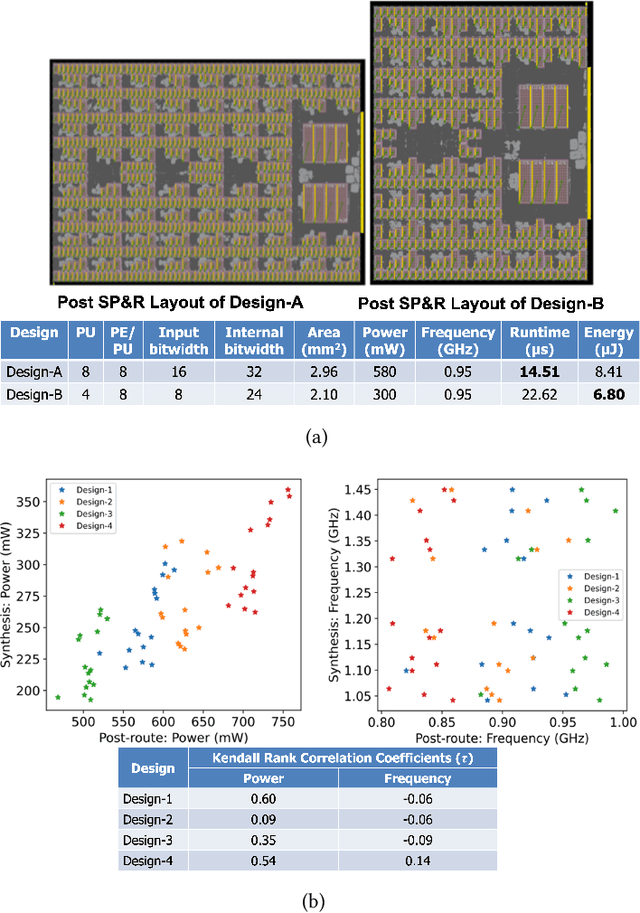
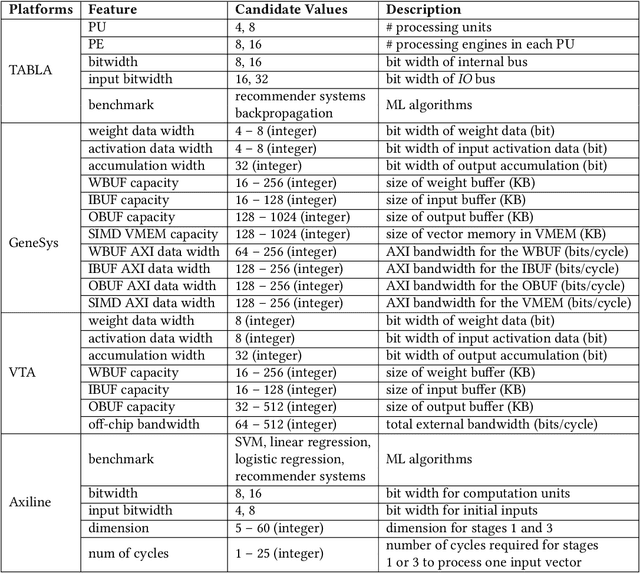
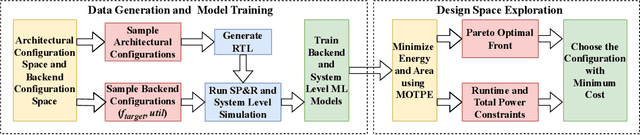
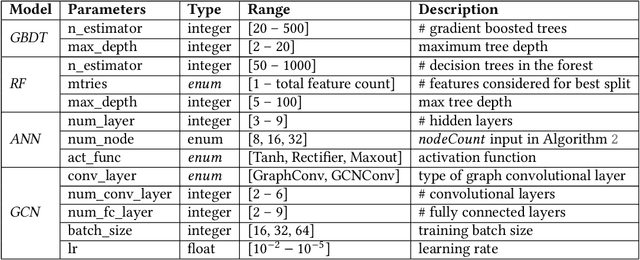
Parameterizable machine learning (ML) accelerators are the product of recent breakthroughs in ML. To fully enable their design space exploration (DSE), we propose a physical-design-driven, learning-based prediction framework for hardware-accelerated deep neural network (DNN) and non-DNN ML algorithms. It adopts a unified approach that combines backend power, performance, and area (PPA) analysis with frontend performance simulation, thereby achieving a realistic estimation of both backend PPA and system metrics such as runtime and energy. In addition, our framework includes a fully automated DSE technique, which optimizes backend and system metrics through an automated search of architectural and backend parameters. Experimental studies show that our approach consistently predicts backend PPA and system metrics with an average 7% or less prediction error for the ASIC implementation of two deep learning accelerator platforms, VTA and VeriGOOD-ML, in both a commercial 12 nm process and a research-oriented 45 nm process.
Assessment of Reinforcement Learning for Macro Placement
Feb 21, 2023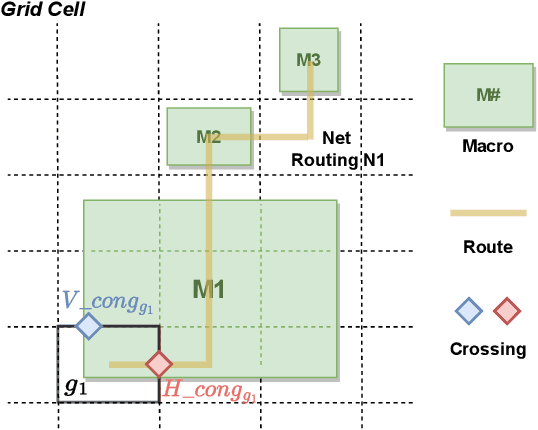
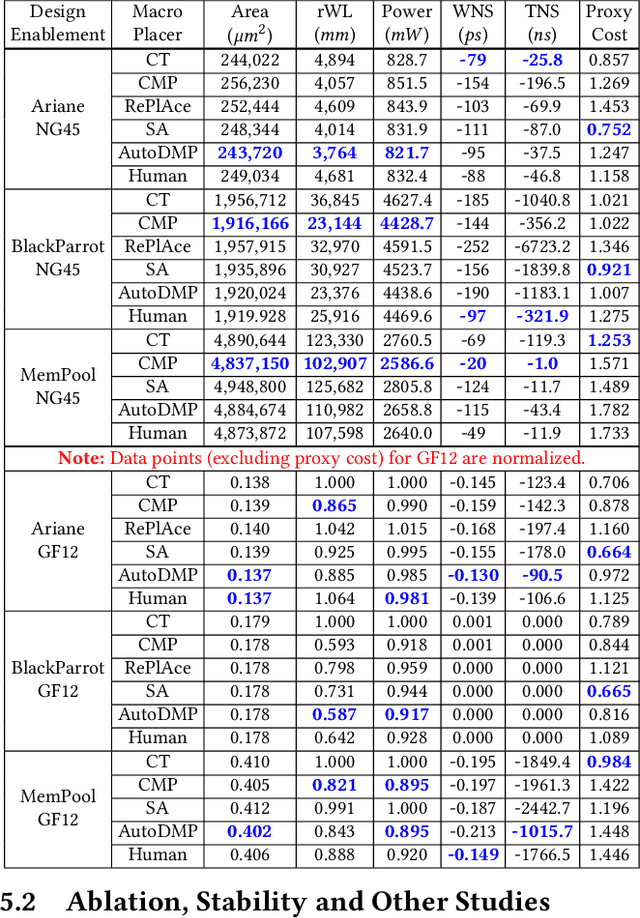
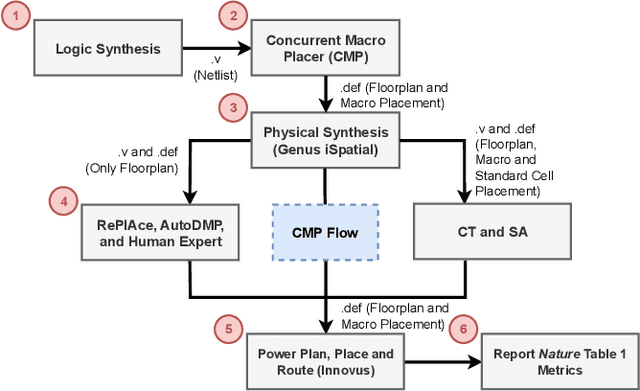
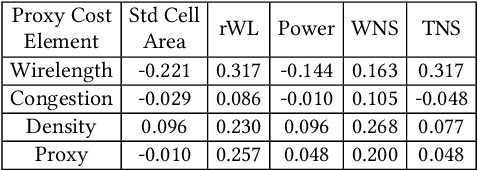
We provide open, transparent implementation and assessment of Google Brain's deep reinforcement learning approach to macro placement and its Circuit Training (CT) implementation in GitHub. We implement in open source key "blackbox" elements of CT, and clarify discrepancies between CT and Nature paper. New testcases on open enablements are developed and released. We assess CT alongside multiple alternative macro placers, with all evaluation flows and related scripts public in GitHub. Our experiments also encompass academic mixed-size placement benchmarks, as well as ablation and stability studies. We comment on the impact of Nature and CT, as well as directions for future research.