 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source ML-Based Full-Stack Optimization Framework for Machine Learning Accelerators
Aug 23, 2023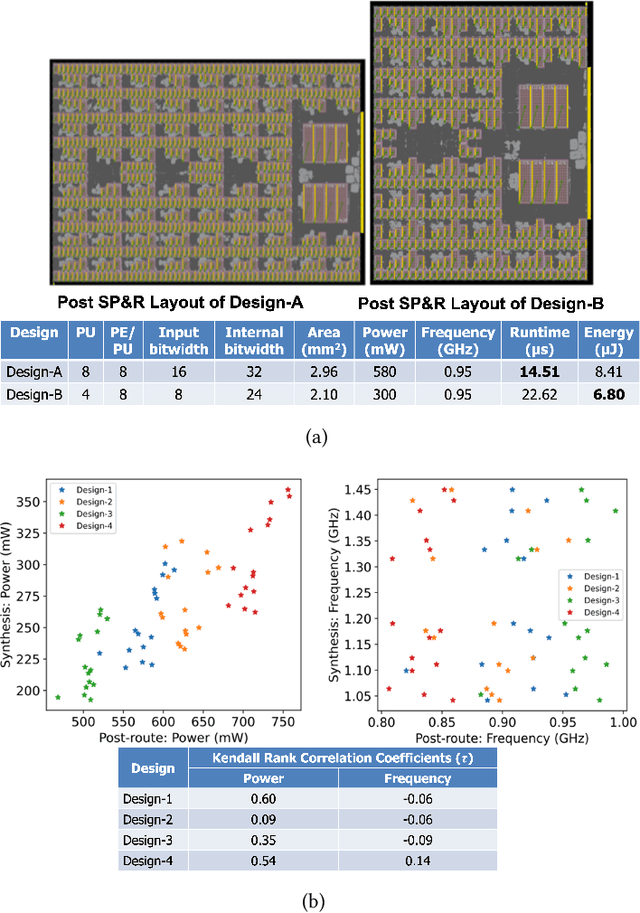
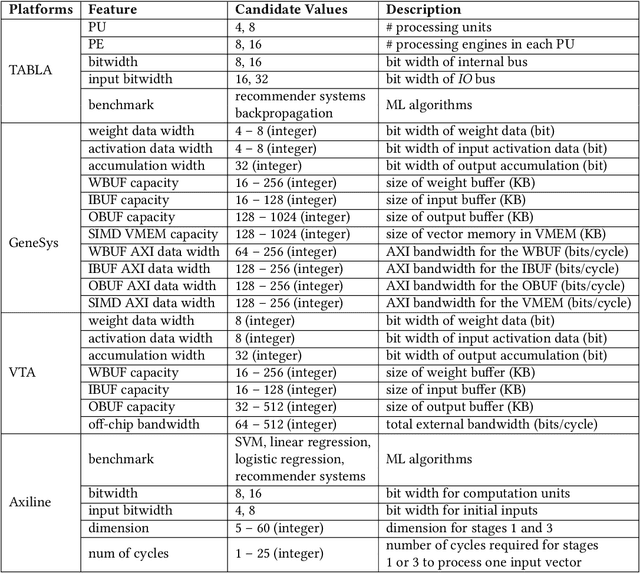
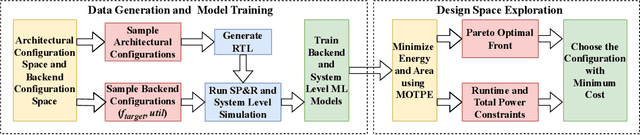
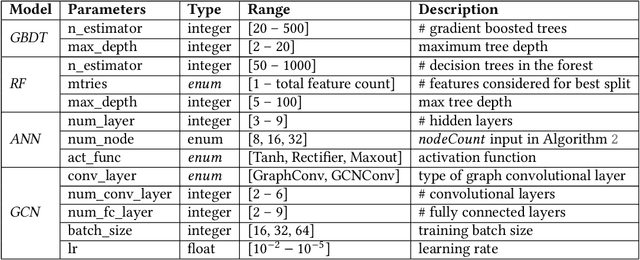
Parameterizable machine learning (ML) accelerators are the product of recent breakthroughs in ML. To fully enable their design space exploration (DSE), we propose a physical-design-driven, learning-based prediction framework for hardware-accelerated deep neural network (DNN) and non-DNN ML algorithms. It adopts a unified approach that combines backend power, performance, and area (PPA) analysis with frontend performance simulation, thereby achieving a realistic estimation of both backend PPA and system metrics such as runtime and energy. In addition, our framework includes a fully automated DSE technique, which optimizes backend and system metrics through an automated search of architectural and backend parameters. Experimental studies show that our approach consistently predicts backend PPA and system metrics with an average 7% or less prediction error for the ASIC implementation of two deep learning accelerator platforms, VTA and VeriGOOD-ML, in both a commercial 12 nm process and a research-oriented 45 nm process.
Performance Analysis of DNN Inference/Training with Convolution and non-Convolution Operations
Jun 29, 2023Today's performance analysis frameworks for deep learning accelerators suffer from two significant limitations. First, although modern convolutional neural network (CNNs) consist of many types of layers other than convolution, especially during training, these frameworks largely focus on convolution layers only. Second, these frameworks are generally targeted towards inference, and lack support for training operations. This work proposes a novel performance analysis framework, SimDIT, for general ASIC-based systolic hardware accelerator platforms. The modeling effort of SimDIT comprehensively covers convolution and non-convolution operations of both CNN inference and training on a highly parameterizable hardware substrate. SimDIT is integrated with a backend silicon implementation flow and provides detailed end-to-end performance statistics (i.e., data access cost, cycle counts, energy, and power) for executing CNN inference and training workloads. SimDIT-enabled performance analysis reveals that on a 64X64 processing array, non-convolution operations constitute 59.5% of total runtime for ResNet-50 training workload. In addition, by optimally distributing available off-chip DRAM bandwidth and on-chip SRAM resources, SimDIT achieves 18X performance improvement over a generic static resource allocation for ResNet-50 inference.