 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtractive summarization on a CMOS Ising machine
Jan 16, 2026Extractive summarization (ES) aims to generate a concise summary by selecting a subset of sentences from a document while maximizing relevance and minimizing redundancy. Although modern ES systems achieve high accuracy using powerful neural models, their deployment typically relies on CPU or GPU infrastructures that are energy-intensive and poorly suited for real-time inference in resource-constrained environments. In this work, we explore the feasibility of implementing McDonald-style extractive summarization on a low-power CMOS coupled oscillator-based Ising machine (COBI) that supports integer-valued, all-to-all spin couplings. We first propose a hardware-aware Ising formulation that reduces the scale imbalance between local fields and coupling terms, thereby improving robustness to coefficient quantization: this method can be applied to any problem formulation that requires k of n variables to be chosen. We then develop a complete ES pipeline including (i) stochastic rounding and iterative refinement to compensate for precision loss, and (ii) a decomposition strategy that partitions a large ES problem into smaller Ising subproblems that can be efficiently solved on COBI and later combined. Experimental results on the CNN/DailyMail dataset show that our pipeline can produce high-quality summaries using only integer-coupled Ising hardware with limited precision. COBI achieves 3-4.5x runtime speedups compared to a brute-force method, which is comparable to software Tabu search, and two to three orders of magnitude reductions in energy, while maintaining competitive summary quality. These results highlight the potential of deploying CMOS Ising solvers for real-time, low-energy text summarization on edge devices.
IR-Aware ECO Timing Optimization Using Reinforcement Learning
Feb 12, 2024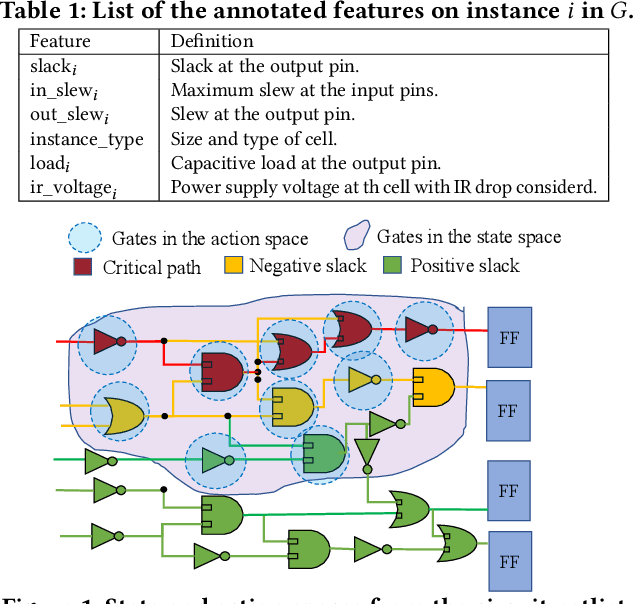
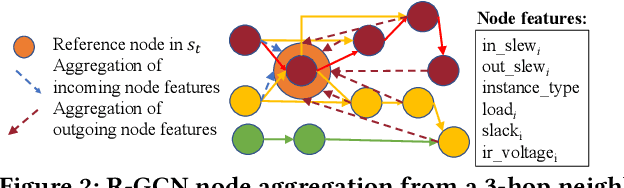
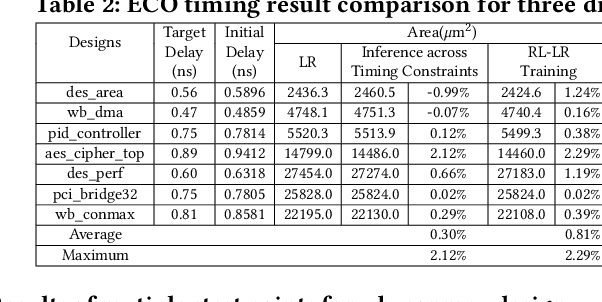
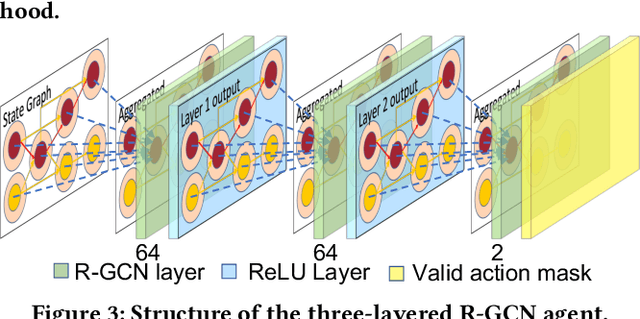
Engineering change orders (ECOs) in late stages make minimal design fixes to recover from timing shifts due to excessive IR drops. This paper integrates IR-drop-aware timing analysis and ECO timing optimization using reinforcement learning (RL). The method operates after physical design and power grid synthesis, and rectifies IR-drop-induced timing degradation through gate sizing. It incorporates the Lagrangian relaxation (LR) technique into a novel RL framework, which trains a relational graph convolutional network (R-GCN) agent to sequentially size gates to fix timing violations. The R-GCN agent outperforms a classical LR-only algorithm: in an open 45nm technology, it (a) moves the Pareto front of the delay-area tradeoff curve to the left and (b) saves runtime over the classical method by running fast inference using trained models at iso-quality. The RL model is transferable across timing specifications, and transferable to unseen designs with zero-shot learning or fine tuning.
Experimental demonstration of magnetic tunnel junction-based computational random-access memory
Dec 21, 2023Conventional computing paradigm struggles to fulfill the rapidly growing demands from emerging applications, especially those for machine intelligence, because much of the power and energy is consumed by constant data transfers between logic and memory modules. A new paradigm, called "computational random-access memory (CRAM)" has emerged to address this fundamental limitation. CRAM performs logic operations directly using the memory cells themselves, without having the data ever leave the memory. The energy and performance benefits of CRAM for both conventional and emerging applications have been well established by prior numerical studies. However, there lacks an experimental demonstration and study of CRAM to evaluate its computation accuracy, which is a realistic and application-critical metrics for its technological feasibility and competitiveness. In this work, a CRAM array based on magnetic tunnel junctions (MTJs) is experimentally demonstrated. First, basic memory operations as well as 2-, 3-, and 5-input logic operations are studied. Then, a 1-bit full adder with two different designs is demonstrated. Based on the experimental results, a suite of modeling has been developed to characterize the accuracy of CRAM computation. Further analysis of scalar addition, multiplication, and matrix multiplication shows promising results. These results are then applied to a complete application: a neural network based handwritten digit classifier, as an example to show the connection between the application performance and further MTJ development. The classifier achieved almost-perfect classification accuracy, with reasonable projections of future MTJ development. With the confirmation of MTJ-based CRAM's accuracy, there is a strong case that this technology will have a significant impact on power- and energy-demanding applications of machine intelligence.
Performance Analysis of DNN Inference/Training with Convolution and non-Convolution Operations
Jun 29, 2023Today's performance analysis frameworks for deep learning accelerators suffer from two significant limitations. First, although modern convolutional neural network (CNNs) consist of many types of layers other than convolution, especially during training, these frameworks largely focus on convolution layers only. Second, these frameworks are generally targeted towards inference, and lack support for training operations. This work proposes a novel performance analysis framework, SimDIT, for general ASIC-based systolic hardware accelerator platforms. The modeling effort of SimDIT comprehensively covers convolution and non-convolution operations of both CNN inference and training on a highly parameterizable hardware substrate. SimDIT is integrated with a backend silicon implementation flow and provides detailed end-to-end performance statistics (i.e., data access cost, cycle counts, energy, and power) for executing CNN inference and training workloads. SimDIT-enabled performance analysis reveals that on a 64X64 processing array, non-convolution operations constitute 59.5% of total runtime for ResNet-50 training workload. In addition, by optimally distributing available off-chip DRAM bandwidth and on-chip SRAM resources, SimDIT achieves 18X performance improvement over a generic static resource allocation for ResNet-50 inference.
Encoder-Decoder Networks for Analyzing Thermal and Power Delivery Networks
Oct 27, 2021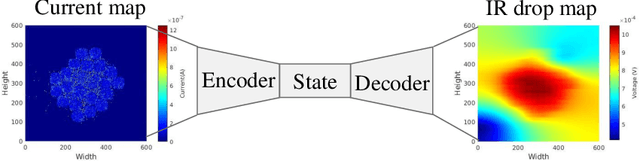
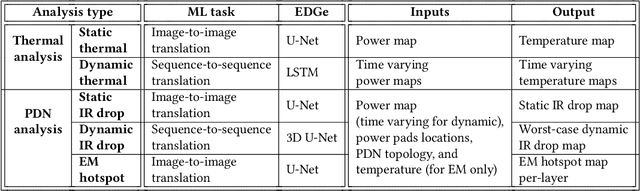
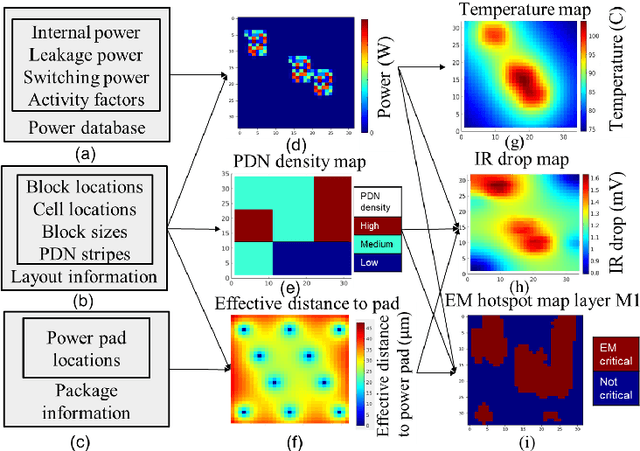
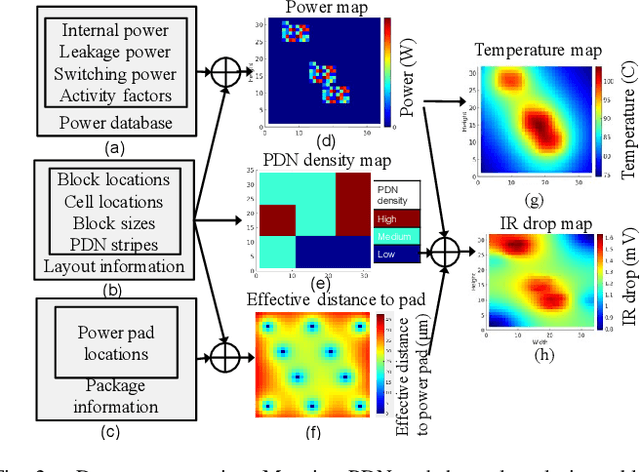
Power delivery network (PDN) analysis and thermal analysis are computationally expensive tasks that are essential for successful IC design. Algorithmically, both these analyses have similar computational structure and complexity as they involve the solution to a partial differential equation of the same form. This paper converts these analyses into image-to-image and sequence-to-sequence translation tasks, which allows leveraging a class of machine learning models with an encoder-decoder-based generative (EDGe) architecture to address the time-intensive nature of these tasks. For PDN analysis, we propose two networks: (i) IREDGe: a full-chip static and dynamic IR drop predictor and (ii) EMEDGe: electromigration (EM) hotspot classifier based on input power, power grid distribution, and power pad distribution patterns. For thermal analysis, we propose ThermEDGe, a full-chip static and dynamic temperature estimator based on input power distribution patterns for thermal analysis. These networks are transferable across designs synthesized within the same technology and packing solution. The networks predict on-chip IR drop, EM hotspot locations, and temperature in milliseconds with negligibly small errors against commercial tools requiring several hours.
OpeNPDN: A Neural-network-based Framework for Power Delivery Network Synthesis
Oct 27, 2021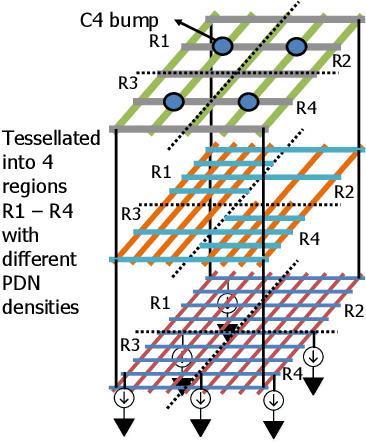
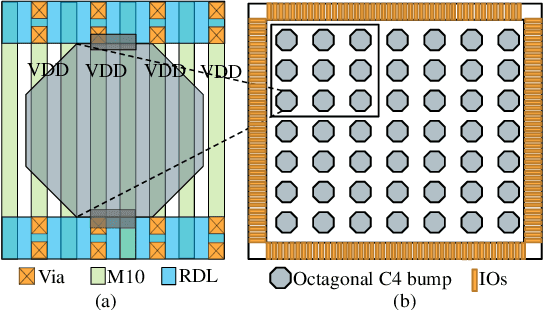
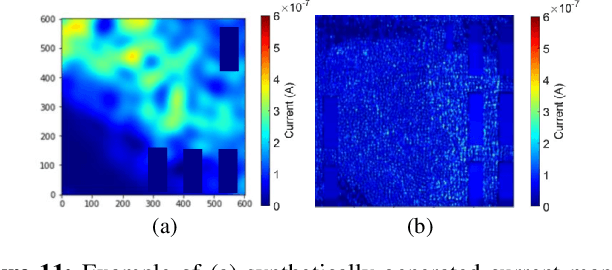
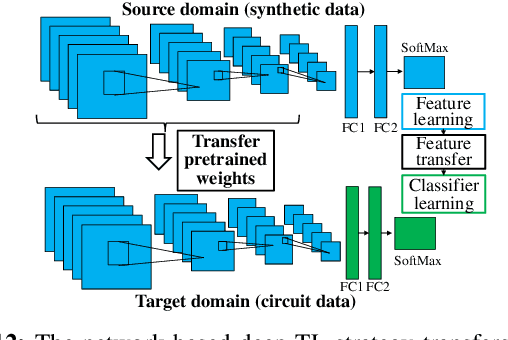
Power delivery network (PDN) design is a nontrivial, time-intensive, and iterative task. Correct PDN design must account for considerations related to power bumps, currents, blockages, and signal congestion distribution patterns. This work proposes a machine learning-based methodology that employs a set of predefined PDN templates. At the floorplan stage, coarse estimates of current, congestion, macro/blockages, and C4 bump distributions are used to synthesize a grid for early design. At the placement stage, the grid is incrementally refined based on more accurate and fine-grained distributions of current and congestion. At each stage, a convolutional neural network (CNN) selects an appropriate PDN template for each region on the chip, building a safe-by-construction PDN that meets IR drop and electromigration (EM) specifications. The CNN is initially trained using a large synthetically-created dataset, following which transfer learning is leveraged to bridge the gap between real-circuit data (with a limited dataset size) and synthetically-generated data. On average, the optimization of the PDN frees thousands of routing tracks in congestion-critical regions, when compared to a globally uniform PDN, while staying within the IR drop and EM limits.
GNNIE: GNN Inference Engine with Load-balancing and Graph-Specific Caching
May 21, 2021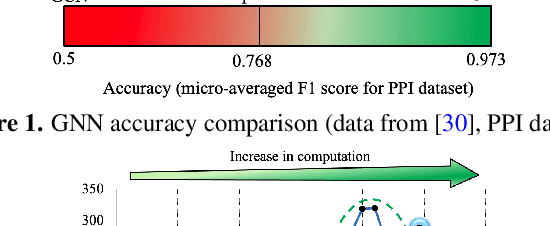

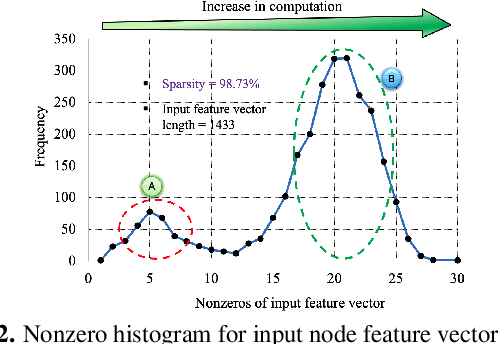
Analysis engines based on Graph Neural Networks (GNNs) are vital for many real-world problems that model relationships using large graphs. Challenges for a GNN hardware platform include the ability to (a) host a variety of GNNs, (b) handle high sparsity in input node feature vectors and the graph adjacency matrix and the accompanying random memory access patterns, and (c) maintain load-balanced computation in the face of uneven workloads induced by high sparsity and power-law vertex degree distributions in real datasets. The proposes GNNIE, an accelerator designed to run a broad range of GNNs. It tackles workload imbalance by (i) splitting node feature operands into blocks, (ii) reordering and redistributing computations, and (iii) using a flexible MAC architecture with low communication overheads among the processing elements. In addition, it adopts a graph partitioning scheme and a graph-specific caching policy that efficiently uses off-chip memory bandwidth that is well suited to the characteristics of real-world graphs. Random memory access effects are mitigated by partitioning and degree-aware caching to enable the reuse of high-degree vertices. GNNIE achieves average speedups of over 8890x over a CPU and 295x over a GPU over multiple datasets on graph attention networks (GATs), graph convolutional networks (GCNs), GraphSAGE, GINConv, and DiffPool, Compared to prior approaches, GNNIE achieves an average speedup of 9.74x over HyGCN for GCN, GraphSAGE, and GINConv; HyGCN cannot implement GATs. GNNIE achieves an average speedup of 2.28x over AWB-GCN (which runs only GCNs), despite using 3.4x fewer processing units.
A general approach for identifying hierarchical symmetry constraints for analog circuit layout
Sep 30, 2020

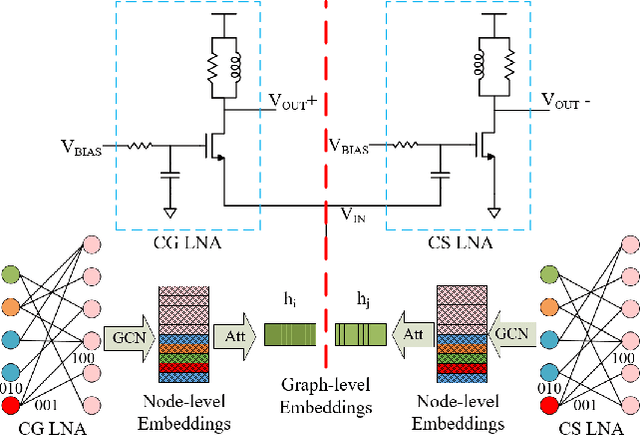
Analog layout synthesis requires some elements in the circuit netlist to be matched and placed symmetrically. However, the set of symmetries is very circuit-specific and a versatile algorithm, applicable to a broad variety of circuits, has been elusive. This paper presents a general methodology for the automated generation of symmetry constraints, and applies these constraints to guide automated layout synthesis. While prior approaches were restricted to identifying simple symmetries, the proposed method operates hierarchically and uses graph-based algorithms to extract multiple axes of symmetry within a circuit. An important ingredient of the algorithm is its ability to identify arrays of repeated structures. In some circuits, the repeated structures are not perfect replicas and can only be found through approximate graph matching. A fast graph neural network based methodology is developed for this purpose, based on evaluating the graph edit distance. The utility of this algorithm is demonstrated on a variety of circuits, including operational amplifiers, data converters, equalizers, and low-noise amplifiers.
Thermal and IR Drop Analysis Using Convolutional Encoder-Decoder Networks
Sep 18, 2020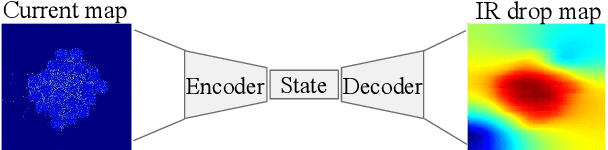
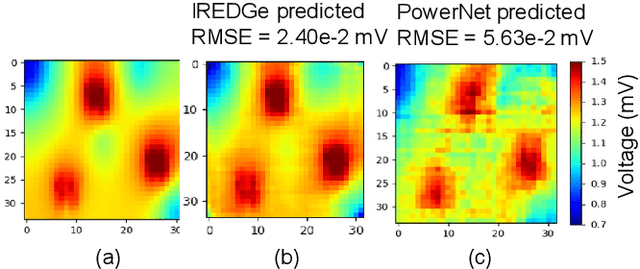
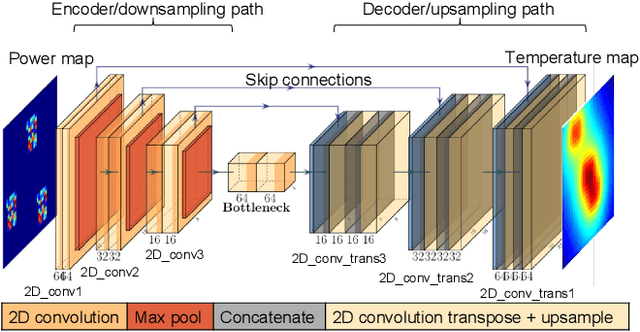
Computationally expensive temperature and power grid analyses are required during the design cycle to guide IC design. This paper employs encoder-decoder based generative (EDGe) networks to map these analyses to fast and accurate image-to-image and sequence-to-sequence translation tasks. The network takes a power map as input and outputs the corresponding temperature or IR drop map. We propose two networks: (i) ThermEDGe: a static and dynamic full-chip temperature estimator and (ii) IREDGe: a full-chip static IR drop predictor based on input power, power grid distribution, and power pad distribution patterns. The models are design-independent and must be trained just once for a particular technology and packaging solution. ThermEDGe and IREDGe are demonstrated to rapidly predict the on-chip temperature and IR drop contours in milliseconds (in contrast with commercial tools that require several hours or more) and provide an average error of 0.6% and 0.008% respectively.