 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
In vivo 3D ultrasound computed tomography of musculoskeletal tissues with generative neural physics
Aug 17, 2025Ultrasound computed tomography (USCT) is a radiation-free, high-resolution modality but remains limited for musculoskeletal imaging due to conventional ray-based reconstructions that neglect strong scattering. We propose a generative neural physics framework that couples generative networks with physics-informed neural simulation for fast, high-fidelity 3D USCT. By learning a compact surrogate of ultrasonic wave propagation from only dozens of cross-modality images, our method merges the accuracy of wave modeling with the efficiency and stability of deep learning. This enables accurate quantitative imaging of in vivo musculoskeletal tissues, producing spatial maps of acoustic properties beyond reflection-mode images. On synthetic and in vivo data (breast, arm, leg), we reconstruct 3D maps of tissue parameters in under ten minutes, with sensitivity to biomechanical properties in muscle and bone and resolution comparable to MRI. By overcoming computational bottlenecks in strongly scattering regimes, this approach advances USCT toward routine clinical assessment of musculoskeletal disease.
HGFormer: A Hierarchical Graph Transformer Framework for Two-Stage Colonel Blotto Games via Reinforcement Learning
Jun 10, 2025Two-stage Colonel Blotto game represents a typical adversarial resource allocation problem, in which two opposing agents sequentially allocate resources in a network topology across two phases: an initial resource deployment followed by multiple rounds of dynamic reallocation adjustments. The sequential dependency between game stages and the complex constraints imposed by the graph topology make it difficult for traditional approaches to attain a globally optimal strategy. To address these challenges, we propose a hierarchical graph Transformer framework called HGformer. By incorporating an enhanced graph Transformer encoder with structural biases and a two-agent hierarchical decision model, our approach enables efficient policy generation in large-scale adversarial environments. Moreover, we design a layer-by-layer feedback reinforcement learning algorithm that feeds the long-term returns from lower-level decisions back into the optimization of the higher-level strategy, thus bridging the coordination gap between the two decision-making stages. Experimental results demonstrate that, compared to existing hierarchical decision-making or graph neural network methods, HGformer significantly improves resource allocation efficiency and adversarial payoff, achieving superior overall performance in complex dynamic game scenarios.
A Local Information Aggregation based Multi-Agent Reinforcement Learning for Robot Swarm Dynamic Task Allocation
Nov 29, 2024



In this paper, we explore how to optimize task allocation for robot swarms in dynamic environments, emphasizing the necessity of formulating robust, flexible, and scalable strategies for robot cooperation. We introduce a novel framework using a decentralized partially observable Markov decision process (Dec_POMDP), specifically designed for distributed robot swarm networks. At the core of our methodology is the Local Information Aggregation Multi-Agent Deep Deterministic Policy Gradient (LIA_MADDPG) algorithm, which merges centralized training with distributed execution (CTDE). During the centralized training phase, a local information aggregation (LIA) module is meticulously designed to gather critical data from neighboring robots, enhancing decision-making efficiency. In the distributed execution phase, a strategy improvement method is proposed to dynamically adjust task allocation based on changing and partially observable environmental conditions. Our empirical evaluations show that the LIA module can be seamlessly integrated into various CTDE-based MARL methods, significantly enhancing their performance. Additionally, by comparing LIA_MADDPG with six conventional reinforcement learning algorithms and a heuristic algorithm, we demonstrate its superior scalability, rapid adaptation to environmental changes, and ability to maintain both stability and convergence speed. These results underscore LIA_MADDPG's outstanding performance and its potential to significantly improve dynamic task allocation in robot swarms through enhanced local collaboration and adaptive strategy execution.
EnviroExam: Benchmarking Environmental Science Knowledge of Large Language Models
May 18, 2024In the field of environmental science, it is crucial to have robust evaluation metrics for large language models to ensure their efficacy and accuracy. We propose EnviroExam, a comprehensive evaluation method designed to assess the knowledge of large language models in the field of environmental science. EnviroExam is based on the curricula of top international universities, covering undergraduate, master's, and doctoral courses, and includes 936 questions across 42 core courses. By conducting 0-shot and 5-shot tests on 31 open-source large language models, EnviroExam reveals the performance differences among these models in the domain of environmental science and provides detailed evaluation standards. The results show that 61.3% of the models passed the 5-shot tests, while 48.39% passed the 0-shot tests. By introducing the coefficient of variation as an indicator, we evaluate the performance of mainstream open-source large language models in environmental science from multiple perspectives, providing effective criteria for selecting and fine-tuning language models in this field. Future research will involve constructing more domain-specific test sets using specialized environmental science textbooks to further enhance the accuracy and specificity of the evaluation.
Experimental demonstration of magnetic tunnel junction-based computational random-access memory
Dec 21, 2023Conventional computing paradigm struggles to fulfill the rapidly growing demands from emerging applications, especially those for machine intelligence, because much of the power and energy is consumed by constant data transfers between logic and memory modules. A new paradigm, called "computational random-access memory (CRAM)" has emerged to address this fundamental limitation. CRAM performs logic operations directly using the memory cells themselves, without having the data ever leave the memory. The energy and performance benefits of CRAM for both conventional and emerging applications have been well established by prior numerical studies. However, there lacks an experimental demonstration and study of CRAM to evaluate its computation accuracy, which is a realistic and application-critical metrics for its technological feasibility and competitiveness. In this work, a CRAM array based on magnetic tunnel junctions (MTJs) is experimentally demonstrated. First, basic memory operations as well as 2-, 3-, and 5-input logic operations are studied. Then, a 1-bit full adder with two different designs is demonstrated. Based on the experimental results, a suite of modeling has been developed to characterize the accuracy of CRAM computation. Further analysis of scalar addition, multiplication, and matrix multiplication shows promising results. These results are then applied to a complete application: a neural network based handwritten digit classifier, as an example to show the connection between the application performance and further MTJ development. The classifier achieved almost-perfect classification accuracy, with reasonable projections of future MTJ development. With the confirmation of MTJ-based CRAM's accuracy, there is a strong case that this technology will have a significant impact on power- and energy-demanding applications of machine intelligence.
Neighborhood-Enhanced and Time-Aware Model for Session-based Recommendation
Oct 01, 2019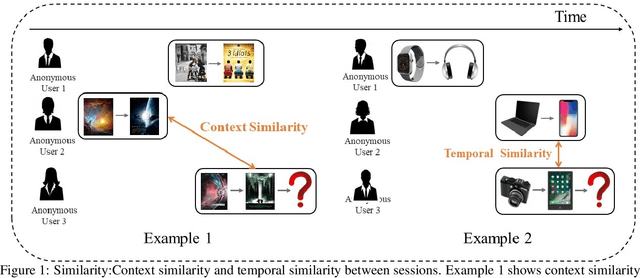
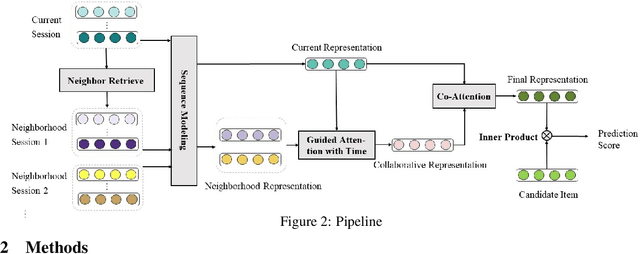
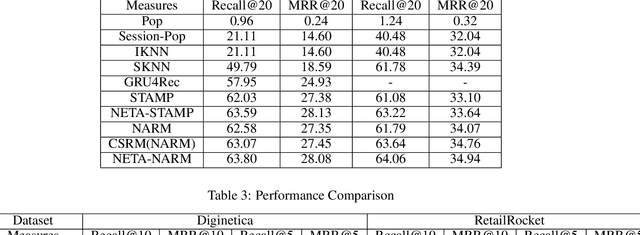
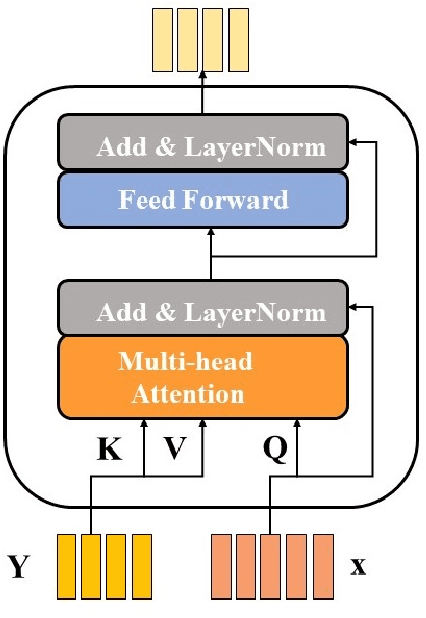
Session based recommendation has become one of the research hotpots in the field of recommendation systems due to its highly practical value.Previous deep learning methods mostly focus on the sequential characteristics within the current session,and neglect the context similarity and temporal similarity between sessions which contain abundant collaborative information.In this paper,we propose a novel neural networks framework,namely Neighborhood Enhanced and Time Aware Recommendation Machine(NETA) for session based recommendation. Firstly,we introduce an efficient neighborhood retrieve mechanism to find out similar sessions which includes collaborative information.Then we design a guided attention with time-aware mechanism to extract collaborative representation from neighborhood sessions.Especially,temporal recency between sessions is considered separately.Finally, we design a simple co-attention mechanism to determine the importance of complementary collaborative representation when predicting the next item.Extensive experiments conducted on two real-world datasets demonstrate the effectiveness of our proposed model.
LEARN: Learned Experts' Assessment-based Reconstruction Network for Sparse-data CT
Feb 10, 2018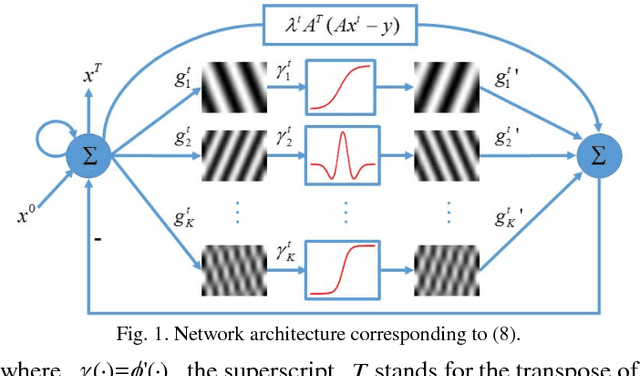
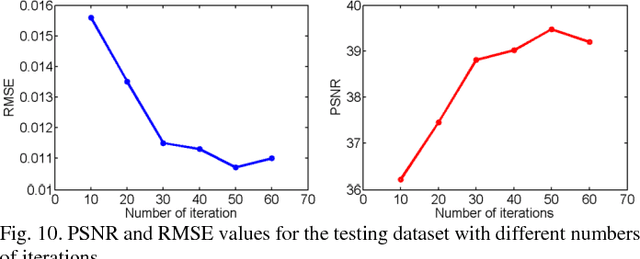
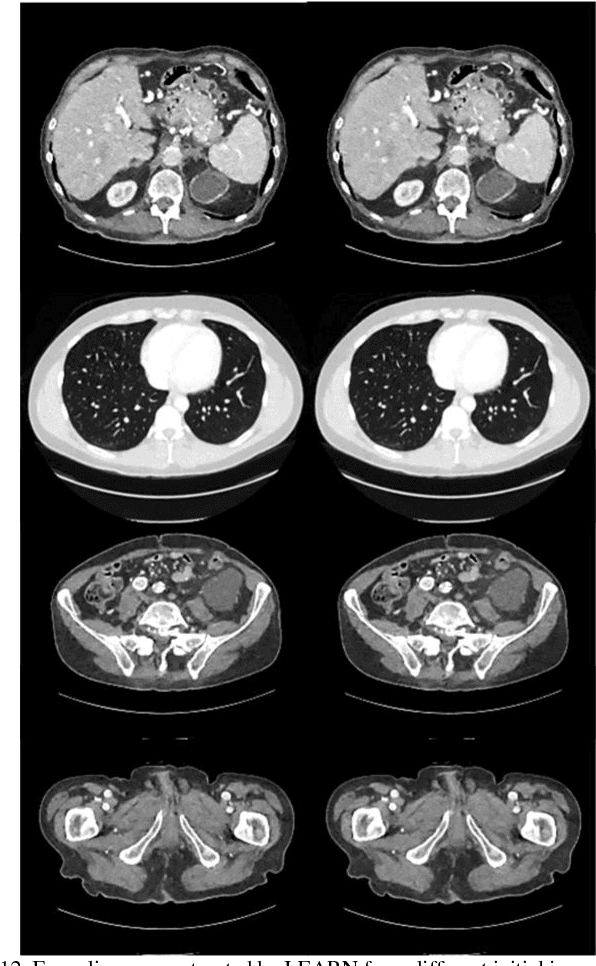
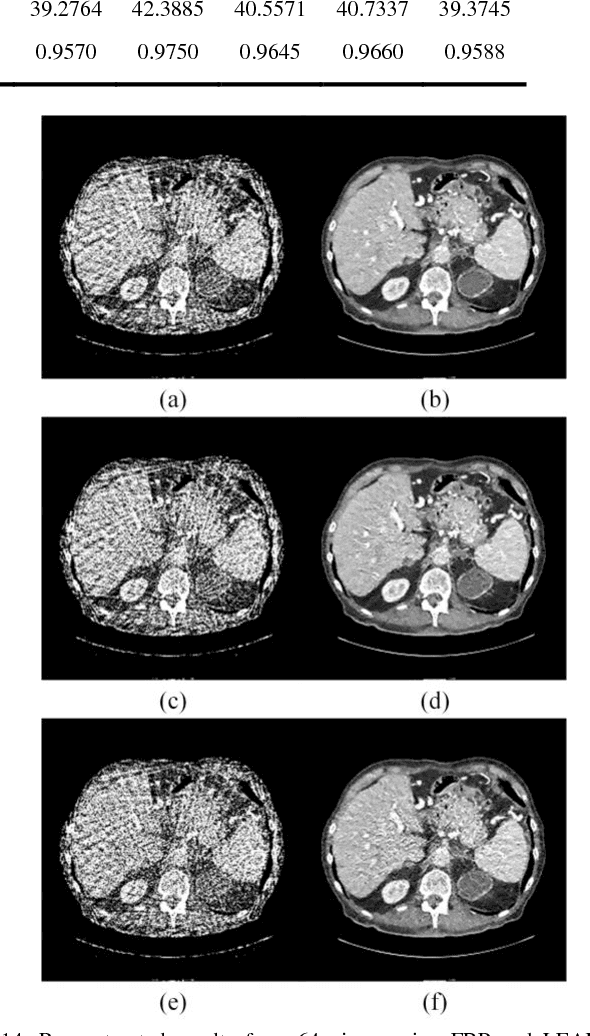
Compressive sensing (CS) has proved effective for tomographic reconstruction from sparsely collected data or under-sampled measurements, which are practically important for few-view CT, tomosynthesis, interior tomography, and so on. To perform sparse-data CT, the iterative reconstruction commonly use regularizers in the CS framework. Currently, how to choose the parameters adaptively for regularization is a major open problem. In this paper, inspired by the idea of machine learning especially deep learning, we unfold a state-of-the-art "fields of experts" based iterative reconstruction scheme up to a number of iterations for data-driven training, construct a Learned Experts' Assessment-based Reconstruction Network ("LEARN") for sparse-data CT, and demonstrate the feasibility and merits of our LEARN network. The experimental results with our proposed LEARN network produces a competitive performance with the well-known Mayo Clinic Low-Dose Challenge Dataset relative to several state-of-the-art methods, in terms of artifact reduction, feature preservation, and computational speed. This is consistent to our insight that because all the regularization terms and parameters used in the iterative reconstruction are now learned from the training data, our LEARN network utilizes application-oriented knowledge more effectively and recovers underlying images more favorably than competing algorithms. Also, the number of layers in the LEARN network is only 12, reducing the computational complexity of typical iterative algorithms by orders of magnitude.