 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Spectrum Sensing in Cognitive and Intelligent Wireless Networks: An Artificial Intelligence Perspective
Feb 10, 2026Artificial intelligence (AI) has become a key enabler for next-generation wireless communication systems, offering powerful tools to cope with the increasing complexity, dynamics, and heterogeneity of modern wireless environments. To illustrate the role and impact of AI in wireless communications, this paper takes collaborative spectrum sensing (CSS) in cognitive and intelligent wireless networks as a representative application and surveys recent advances from an AI perspective. We first introduce the fundamentals of CSS, including the general framework, classical detector design, and fusion strategies. Then, we present an overview of the state-of-the-art research on AI-driven CSS, classified into three categories: discriminative deep learning (DL) models, generative DL models, and deep reinforcement learning (DRL). Furthermore, we explore semantic communication (SemCom) as a promising solution for CSS, in which task-oriented representations are exchanged to reduce reporting overhead while preserving decision-critical information. Finally, we discuss limitations, open challenges, and future research directions at the intersection of AI and wireless communication.
HGFormer: A Hierarchical Graph Transformer Framework for Two-Stage Colonel Blotto Games via Reinforcement Learning
Jun 10, 2025Two-stage Colonel Blotto game represents a typical adversarial resource allocation problem, in which two opposing agents sequentially allocate resources in a network topology across two phases: an initial resource deployment followed by multiple rounds of dynamic reallocation adjustments. The sequential dependency between game stages and the complex constraints imposed by the graph topology make it difficult for traditional approaches to attain a globally optimal strategy. To address these challenges, we propose a hierarchical graph Transformer framework called HGformer. By incorporating an enhanced graph Transformer encoder with structural biases and a two-agent hierarchical decision model, our approach enables efficient policy generation in large-scale adversarial environments. Moreover, we design a layer-by-layer feedback reinforcement learning algorithm that feeds the long-term returns from lower-level decisions back into the optimization of the higher-level strategy, thus bridging the coordination gap between the two decision-making stages. Experimental results demonstrate that, compared to existing hierarchical decision-making or graph neural network methods, HGformer significantly improves resource allocation efficiency and adversarial payoff, achieving superior overall performance in complex dynamic game scenarios.
An Automated Reinforcement Learning Reward Design Framework with Large Language Model for Cooperative Platoon Coordination
Apr 28, 2025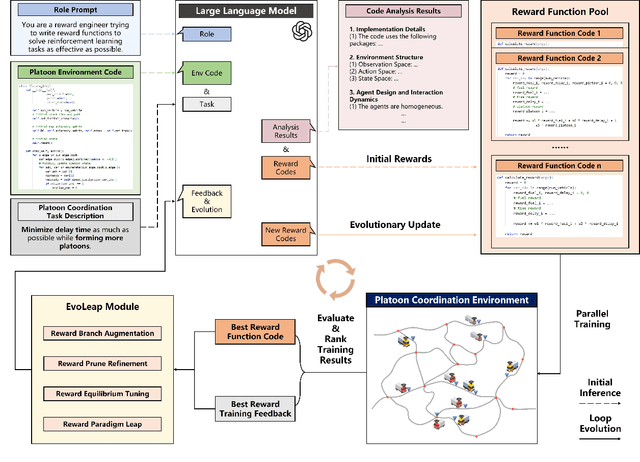

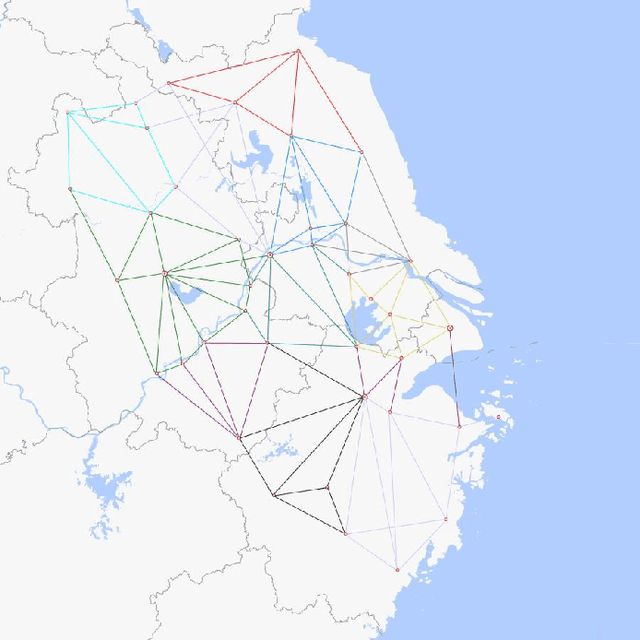
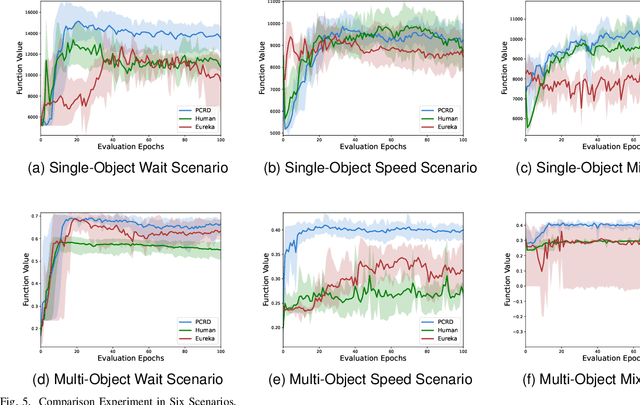
Reinforcement Learning (RL) has demonstrated excellent decision-making potential in platoon coordination problems. However, due to the variability of coordination goals, the complexity of the decision problem, and the time-consumption of trial-and-error in manual design, finding a well performance reward function to guide RL training to solve complex platoon coordination problems remains challenging. In this paper, we formally define the Platoon Coordination Reward Design Problem (PCRDP), extending the RL-based cooperative platoon coordination problem to incorporate automated reward function generation. To address PCRDP, we propose a Large Language Model (LLM)-based Platoon coordination Reward Design (PCRD) framework, which systematically automates reward function discovery through LLM-driven initialization and iterative optimization. In this method, LLM first initializes reward functions based on environment code and task requirements with an Analysis and Initial Reward (AIR) module, and then iteratively optimizes them based on training feedback with an evolutionary module. The AIR module guides LLM to deepen their understanding of code and tasks through a chain of thought, effectively mitigating hallucination risks in code generation. The evolutionary module fine-tunes and reconstructs the reward function, achieving a balance between exploration diversity and convergence stability for training. To validate our approach, we establish six challenging coordination scenarios with varying complexity levels within the Yangtze River Delta transportation network simulation. Comparative experimental results demonstrate that RL agents utilizing PCRD-generated reward functions consistently outperform human-engineered reward functions, achieving an average of 10\% higher performance metrics in all scenarios.
A Local Information Aggregation based Multi-Agent Reinforcement Learning for Robot Swarm Dynamic Task Allocation
Nov 29, 2024



In this paper, we explore how to optimize task allocation for robot swarms in dynamic environments, emphasizing the necessity of formulating robust, flexible, and scalable strategies for robot cooperation. We introduce a novel framework using a decentralized partially observable Markov decision process (Dec_POMDP), specifically designed for distributed robot swarm networks. At the core of our methodology is the Local Information Aggregation Multi-Agent Deep Deterministic Policy Gradient (LIA_MADDPG) algorithm, which merges centralized training with distributed execution (CTDE). During the centralized training phase, a local information aggregation (LIA) module is meticulously designed to gather critical data from neighboring robots, enhancing decision-making efficiency. In the distributed execution phase, a strategy improvement method is proposed to dynamically adjust task allocation based on changing and partially observable environmental conditions. Our empirical evaluations show that the LIA module can be seamlessly integrated into various CTDE-based MARL methods, significantly enhancing their performance. Additionally, by comparing LIA_MADDPG with six conventional reinforcement learning algorithms and a heuristic algorithm, we demonstrate its superior scalability, rapid adaptation to environmental changes, and ability to maintain both stability and convergence speed. These results underscore LIA_MADDPG's outstanding performance and its potential to significantly improve dynamic task allocation in robot swarms through enhanced local collaboration and adaptive strategy execution.
A Semi-decentralized and Variational-Equilibrium-Based Trajectory Planner for Connected and Autonomous Vehicles
Oct 20, 2024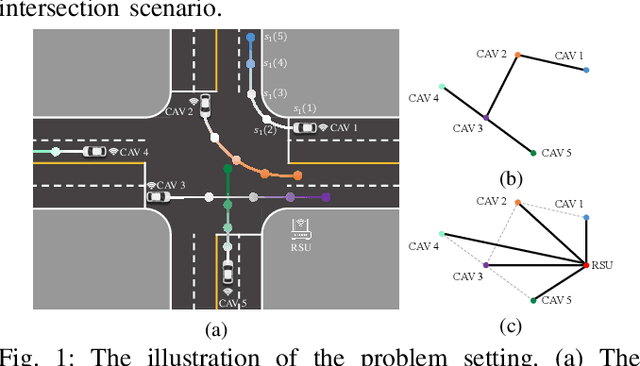
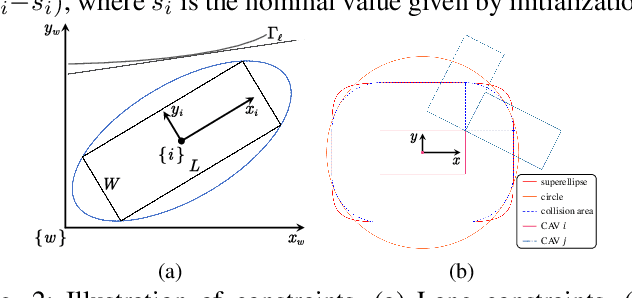
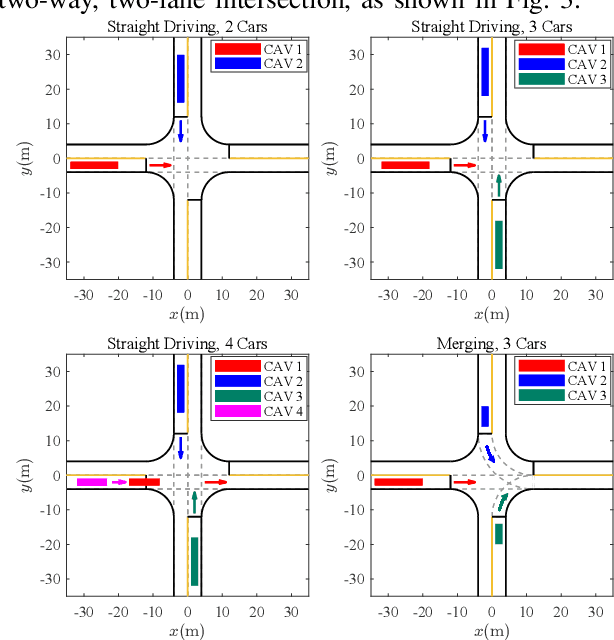
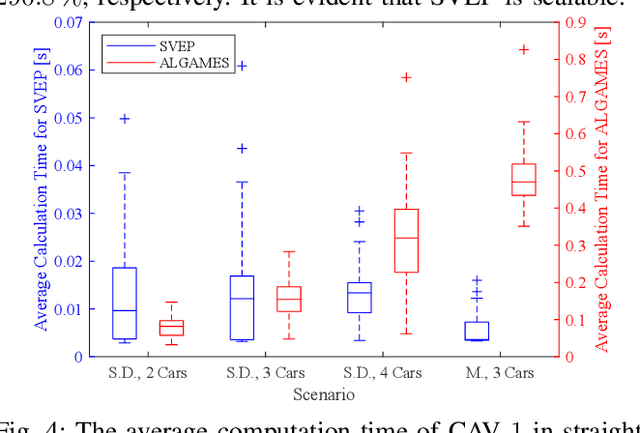
This paper designs a novel trajectory planning approach to resolve the computational efficiency and safety problems in uncoordinated methods by exploiting vehicle-to-everything (V2X) technology. The trajectory planning for connected and autonomous vehicles (CAVs) is formulated as a game with coupled safety constraints. We then define interaction-fair trajectories and prove that they correspond to the variational equilibrium (VE) of this game. We propose a semi-decentralized planner for the vehicles to seek VE-based fair trajectories, which can significantly improve computational efficiency through parallel computing among CAVs and enhance the safety of planned trajectories by ensuring equilibrium concordance among CAVs. Finally, experimental results show the advantages of the approach, including fast computation speed, high scalability, equilibrium concordance, and safety.
Multi-Vehicle Trajectory Planning at V2I-enabled Intersections based on Correlated Equilibrium
Jun 08, 2024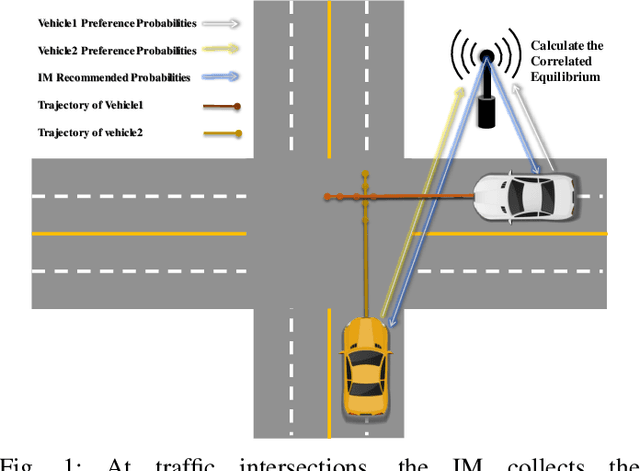
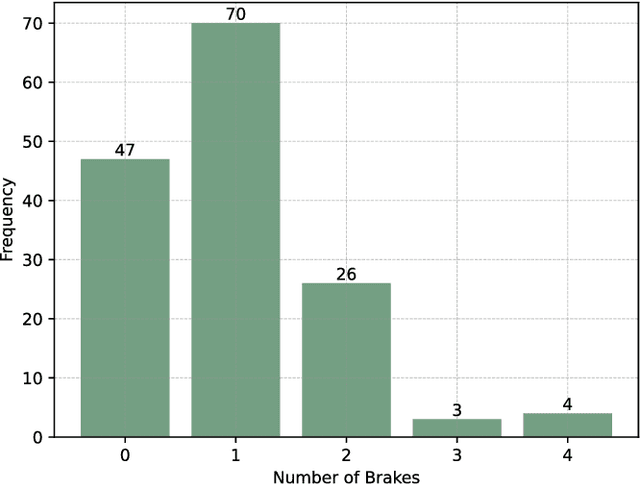

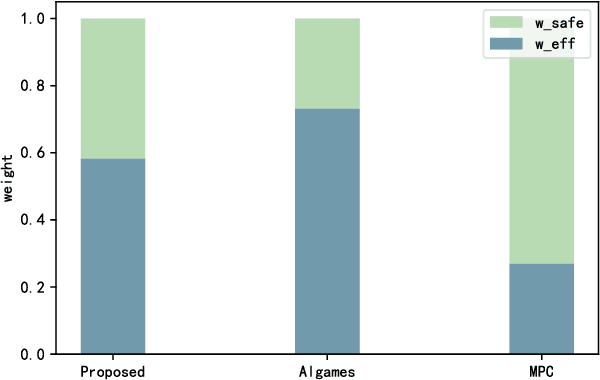
Generating trajectories that ensure both vehicle safety and improve traffic efficiency remains a challenging task at intersections. Many existing works utilize Nash equilibrium (NE) for the trajectory planning at intersections. However, NE-based planning can hardly guarantee that all vehicles are in the same equilibrium, leading to a risk of collision. In this work, we propose a framework for trajectory planning based on Correlated Equilibrium (CE) when V2I communication is also enabled. The recommendation with CE allows all vehicles to reach a safe and consensual equilibrium and meanwhile keeps the rationality as NE-based methods that no vehicle has the incentive to deviate. The Intersection Manager (IM) first collects the trajectory library and the personal preference probabilities over the library from each vehicle in a low-resolution spatial-temporal grid map. Then, the IM optimizes the recommendation probability distribution for each vehicle's trajectory by minimizing overall collision probability under the CE constraint. Finally, each vehicle samples a trajectory of the low-resolution map to construct a safety corridor and derive a smooth trajectory with a local refinement optimization. We conduct comparative experiments at a crossroad intersection involving two and four vehicles, validating the effectiveness of our method in balancing vehicle safety and traffic efficiency.
Distributed Pose-graph Optimization with Multi-level Partitioning for Collaborative SLAM
Jan 10, 2024



The back-end module of Distributed Collaborative Simultaneous Localization and Mapping (DCSLAM) requires solving a nonlinear Pose Graph Optimization (PGO) under a distributed setting, also known as SE(d)-synchronization. Most existing distributed graph optimization algorithms employ a simple sequential partitioning scheme, which may result in unbalanced subgraph dimensions due to the different geographic locations of each robot, and hence imposes extra communication load. Moreover, the performance of current Riemannian optimization algorithms can be further accelerated. In this letter, we propose a novel distributed pose graph optimization algorithm combining multi-level partitioning with an accelerated Riemannian optimization method. Firstly, we employ the multi-level graph partitioning algorithm to preprocess the naive pose graph to formulate a balanced optimization problem. In addition, inspired by the accelerated coordinate descent method, we devise an Improved Riemannian Block Coordinate Descent (IRBCD) algorithm and the critical point obtained is globally optimal. Finally, we evaluate the effects of four common graph partitioning approaches on the correlation of the inter-subgraphs, and discover that the Highest scheme has the best partitioning performance. Also, we implement simulations to quantitatively demonstrate that our proposed algorithm outperforms the state-of-the-art distributed pose graph optimization protocols.
Integrated Distributed Semantic Communication and Over-the-air Computation for Cooperative Spectrum Sensing
Nov 08, 2023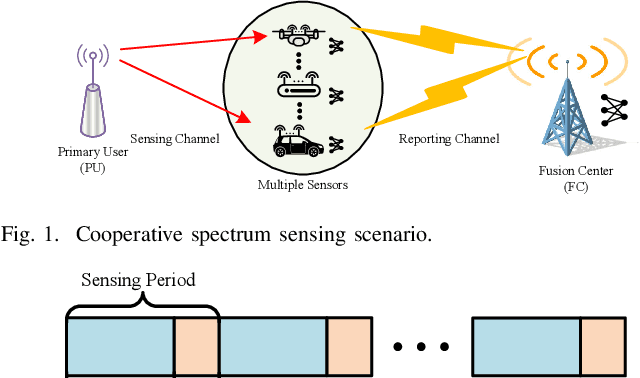
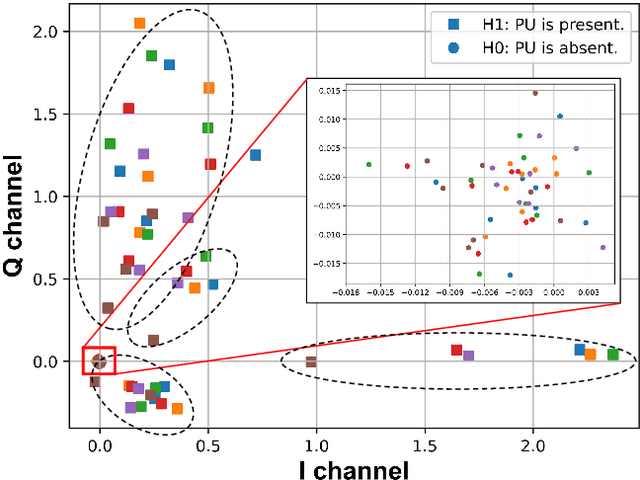
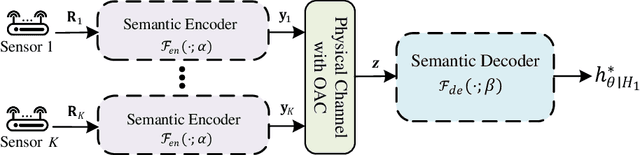
Cooperative spectrum sensing (CSS) is a promising approach to improve the detection of primary users (PUs) using multiple sensors. However, there are several challenges for existing combination methods, i.e., performance degradation and ceiling effect for hard-decision fusion (HDF), as well as significant uploading latency and non-robustness to noise in the reporting channel for soft-data fusion (SDF). To address these issues, in this paper, we propose a novel framework for CSS that integrates communication and computation, namely ICC. Specifically, distributed semantic communication (DSC) jointly optimizes multiple sensors and the fusion center to minimize the transmitted data without degrading detection performance. Moreover, over-the-air computation (AirComp) is utilized to further reduce spectrum occupation in the reporting channel, taking advantage of the characteristics of the wireless channel to enable data aggregation. Under the ICC framework, a particular system, namely ICC-CSS, is designed and implemented, which is theoretically proved to be equivalent to the optimal estimator-correlator (E-C) detector with equal gain SDF when the PU signal samples are independent and identically distributed. Extensive simulations verify the superiority of ICC-CSS compared with various conventional CSS schemes in terms of detection performance, robustness to SNR variations in both the sensing and reporting channels, as well as scalability with respect to the number of samples and sensors.
Deep Learning-Empowered Semantic Communication Systems with a Shared Knowledge Base
Nov 06, 2023Deep learning-empowered semantic communication is regarded as a promising candidate for future 6G networks. Although existing semantic communication systems have achieved superior performance compared to traditional methods, the end-to-end architecture adopted by most semantic communication systems is regarded as a black box, leading to the lack of explainability. To tackle this issue, in this paper, a novel semantic communication system with a shared knowledge base is proposed for text transmissions. Specifically, a textual knowledge base constructed by inherently readable sentences is introduced into our system. With the aid of the shared knowledge base, the proposed system integrates the message and corresponding knowledge from the shared knowledge base to obtain the residual information, which enables the system to transmit fewer symbols without semantic performance degradation. In order to make the proposed system more reliable, the semantic self-information and the source entropy are mathematically defined based on the knowledge base. Furthermore, the knowledge base construction algorithm is developed based on a similarity-comparison method, in which a pre-configured threshold can be leveraged to control the size of the knowledge base. Moreover, the simulation results have demonstrated that the proposed approach outperforms existing baseline methods in terms of transmitted data size and sentence similarity.
CValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility
Jul 19, 2023



With the rapid evolution of large language models (LLMs), there is a growing concern that they may pose risks or have negative social impacts. Therefore, evaluation of human values alignment is becoming increasingly important. Previous work mainly focuses on assessing the performance of LLMs on certain knowledge and reasoning abilities, while neglecting the alignment to human values, especially in a Chinese context. In this paper, we present CValues, the first Chinese human values evaluation benchmark to measure the alignment ability of LLMs in terms of both safety and responsibility criteria. As a result, we have manually collected adversarial safety prompts across 10 scenarios and induced responsibility prompts from 8 domains by professional experts. To provide a comprehensive values evaluation of Chinese LLMs, we not only conduct human evaluation for reliable comparison, but also construct multi-choice prompts for automatic evaluation. Our findings suggest that while most Chinese LLMs perform well in terms of safety, there is considerable room for improvement in terms of responsibility. Moreover, both the automatic and human evaluation are important for assessing the human values alignment in different aspects. The benchmark and code is available on ModelScope and Github.