 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionMAC: Deformation-Free Fashion Image Generation with Fine-Grained Model Appearance Customization
Nov 18, 2025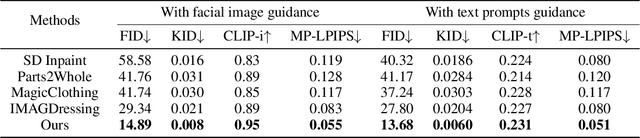
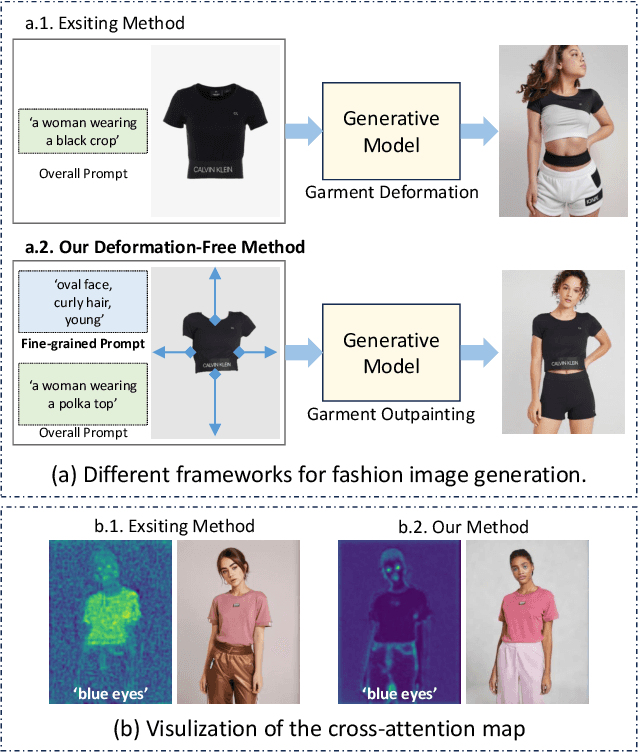

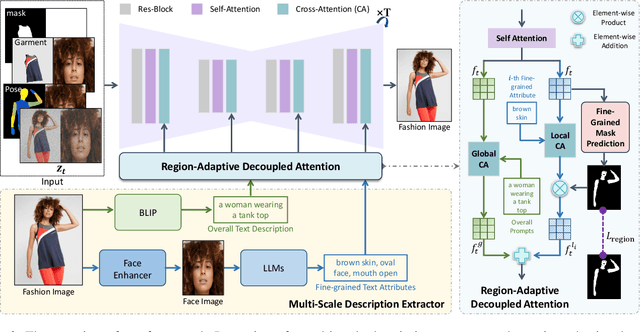
Garment-centric fashion image generation aims to synthesize realistic and controllable human models dressing a given garment, which has attracted growing interest due to its practical applications in e-commerce. The key challenges of the task lie in two aspects: (1) faithfully preserving the garment details, and (2) gaining fine-grained controllability over the model's appearance. Existing methods typically require performing garment deformation in the generation process, which often leads to garment texture distortions. Also, they fail to control the fine-grained attributes of the generated models, due to the lack of specifically designed mechanisms. To address these issues, we propose FashionMAC, a novel diffusion-based deformation-free framework that achieves high-quality and controllable fashion showcase image generation. The core idea of our framework is to eliminate the need for performing garment deformation and directly outpaint the garment segmented from a dressed person, which enables faithful preservation of the intricate garment details. Moreover, we propose a novel region-adaptive decoupled attention (RADA) mechanism along with a chained mask injection strategy to achieve fine-grained appearance controllability over the synthesized human models. Specifically, RADA adaptively predicts the generated regions for each fine-grained text attribute and enforces the text attribute to focus on the predicted regions by a chained mask injection strategy, significantly enhancing the visual fidelity and the controllability. Extensive experiments validate the superior performance of our framework compared to existing state-of-the-art methods.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
LF-GNSS: Towards More Robust Satellite Positioning with a Hard Example Mining Enhanced Learning-Filtering Deep Fusion Framework
May 26, 2025

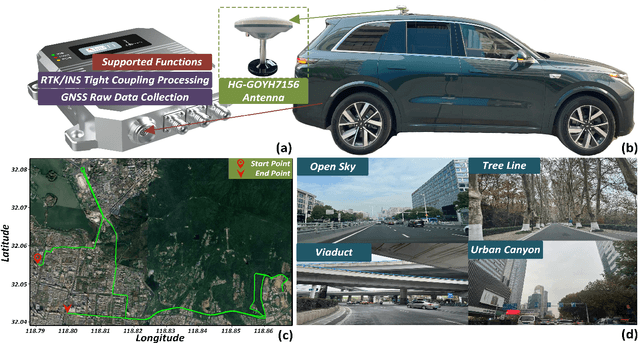
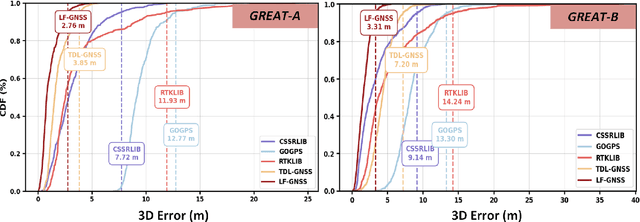
Global Navigation Satellite System (GNSS) is essential for autonomous driving systems, unmanned vehicles, and various location-based technologies, as it provides the precise geospatial information necessary for navigation and situational awareness. However, its performance is often degraded by Non-Line-Of-Sight (NLOS) and multipath effects, especially in urban environments. Recently, Artificial Intelligence (AI) has been driving innovation across numerous industries, introducing novel solutions to mitigate the challenges in satellite positioning. This paper presents a learning-filtering deep fusion framework for satellite positioning, termed LF-GNSS. The framework utilizes deep learning networks to intelligently analyze the signal characteristics of satellite observations, enabling the adaptive construction of observation noise covariance matrices and compensated innovation vectors for Kalman filter input. A dynamic hard example mining technique is incorporated to enhance model robustness by prioritizing challenging satellite signals during training. Additionally, we introduce a novel feature representation based on Dilution of Precision (DOP) contributions, which helps to more effectively characterize the signal quality of individual satellites and improve measurement weighting. LF-GNSS has been validated on both public and private datasets, demonstrating superior positioning accuracy compared to traditional methods and other learning-based solutions. To encourage further integration of AI and GNSS research, we will open-source the code at https://github.com/GarlanLou/LF-GNSS, and release a collection of satellite positioning datasets for urban scenarios at https://github.com/GarlanLou/LF-GNSS-Dataset.
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Mar 03, 2025In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model's appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.
Detection of AI Deepfake and Fraud in Online Payments Using GAN-Based Models
Jan 13, 2025



This study explores the use of Generative Adversarial Networks (GANs) to detect AI deepfakes and fraudulent activities in online payment systems. With the growing prevalence of deepfake technology, which can manipulate facial features in images and videos, the potential for fraud in online transactions has escalated. Traditional security systems struggle to identify these sophisticated forms of fraud. This research proposes a novel GAN-based model that enhances online payment security by identifying subtle manipulations in payment images. The model is trained on a dataset consisting of real-world online payment images and deepfake images generated using advanced GAN architectures, such as StyleGAN and DeepFake. The results demonstrate that the proposed model can accurately distinguish between legitimate transactions and deepfakes, achieving a high detection rate above 95%. This approach significantly improves the robustness of payment systems against AI-driven fraud. The paper contributes to the growing field of digital security, offering insights into the application of GANs for fraud detection in financial services. Keywords- Payment Security, Image Recognition, Generative Adversarial Networks, AI Deepfake, Fraudulent Activities
AnimateAnything: Consistent and Controllable Animation for Video Generation
Nov 16, 2024


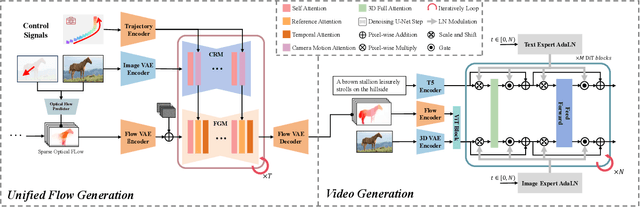
We present a unified controllable video generation approach AnimateAnything that facilitates precise and consistent video manipulation across various conditions, including camera trajectories, text prompts, and user motion annotations. Specifically, we carefully design a multi-scale control feature fusion network to construct a common motion representation for different conditions. It explicitly converts all control information into frame-by-frame optical flows. Then we incorporate the optical flows as motion priors to guide final video generation. In addition, to reduce the flickering issues caused by large-scale motion, we propose a frequency-based stabilization module. It can enhance temporal coherence by ensuring the video's frequency domain consistency. Experiments demonstrate that our method outperforms the state-of-the-art approaches. For more details and videos, please refer to the webpage: https://yu-shaonian.github.io/Animate_Anything/.
StuGPTViz: A Visual Analytics Approach to Understand Student-ChatGPT Interactions
Jul 17, 2024



The integration of Large Language Models (LLMs), especially ChatGPT, into education is poised to revolutionize students' learning experiences by introducing innovative conversational learning methodologies. To empower students to fully leverage the capabilities of ChatGPT in educational scenarios, understanding students' interaction patterns with ChatGPT is crucial for instructors. However, this endeavor is challenging due to the absence of datasets focused on student-ChatGPT conversations and the complexities in identifying and analyzing the evolutional interaction patterns within conversations. To address these challenges, we collected conversational data from 48 students interacting with ChatGPT in a master's level data visualization course over one semester. We then developed a coding scheme, grounded in the literature on cognitive levels and thematic analysis, to categorize students' interaction patterns with ChatGPT. Furthermore, we present a visual analytics system, StuGPTViz, that tracks and compares temporal patterns in student prompts and the quality of ChatGPT's responses at multiple scales, revealing significant pedagogical insights for instructors. We validated the system's effectiveness through expert interviews with six data visualization instructors and three case studies. The results confirmed StuGPTViz's capacity to enhance educators' insights into the pedagogical value of ChatGPT. We also discussed the potential research opportunities of applying visual analytics in education and developing AI-driven personalized learning solutions.
fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations
Jul 11, 2024Pre-trained language models (PLMs) have revolutionized both the natural language processing research and applications. However, stereotypical biases (e.g., gender and racial discrimination) encoded in PLMs have raised negative ethical implications for PLMs, which critically limits their broader applications. To address the aforementioned unfairness issues, we present fairBERTs, a general framework for learning fair fine-tuned BERT series models by erasing the protected sensitive information via semantic and fairness-aware perturbations generated by a generative adversarial network. Through extensive qualitative and quantitative experiments on two real-world tasks, we demonstrate the great superiority of fairBERTs in mitigating unfairness while maintaining the model utility. We also verify the feasibility of transferring adversarial components in fairBERTs to other conventionally trained BERT-like models for yielding fairness improvements. Our findings may shed light on further research on building fairer fine-tuned PLMs.
Advanced Financial Fraud Detection Using GNN-CL Model
Jul 09, 2024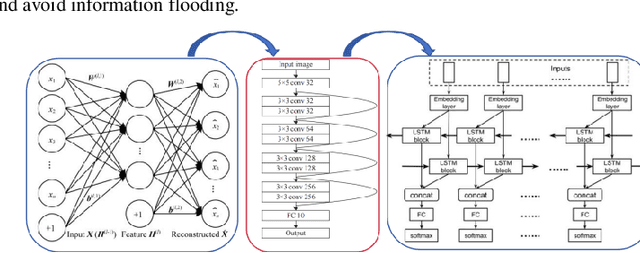
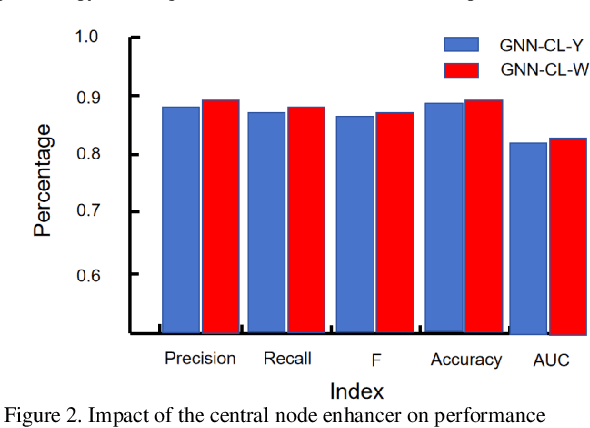
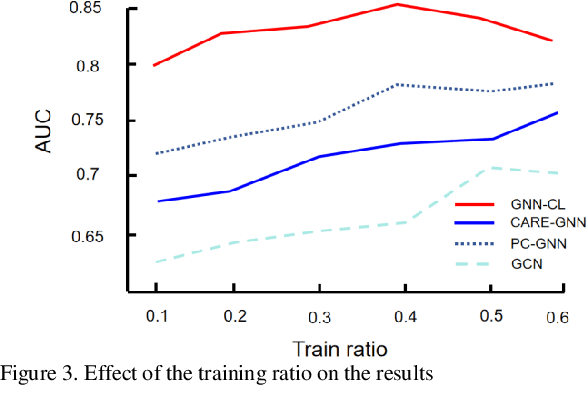
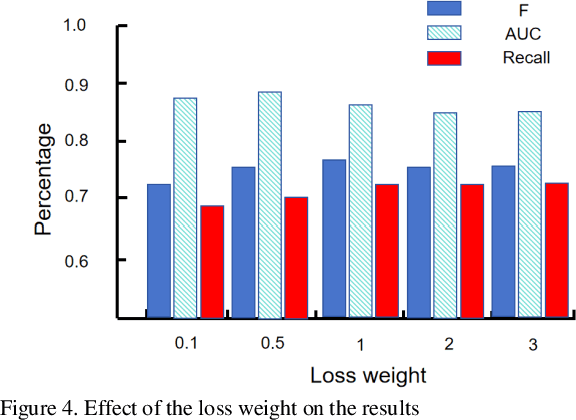
The innovative GNN-CL model proposed in this paper marks a breakthrough in the field of financial fraud detection by synergistically combining the advantages of graph neural networks (gnn), convolutional neural networks (cnn) and long short-term memory (LSTM) networks. This convergence enables multifaceted analysis of complex transaction patterns, improving detection accuracy and resilience against complex fraudulent activities. A key novelty of this paper is the use of multilayer perceptrons (MLPS) to estimate node similarity, effectively filtering out neighborhood noise that can lead to false positives. This intelligent purification mechanism ensures that only the most relevant information is considered, thereby improving the model's understanding of the network structure. Feature weakening often plagues graph-based models due to the dilution of key signals. In order to further address the challenge of feature weakening, GNN-CL adopts reinforcement learning strategies. By dynamically adjusting the weights assigned to central nodes, it reinforces the importance of these influential entities to retain important clues of fraud even in less informative data. Experimental evaluations on Yelp datasets show that the results highlight the superior performance of GNN-CL compared to existing methods.
FE-GUT: Factor Graph Optimization hybrid with Extended Kalman Filter for tightly coupled GNSS/UWB Integration
Jul 09, 2024

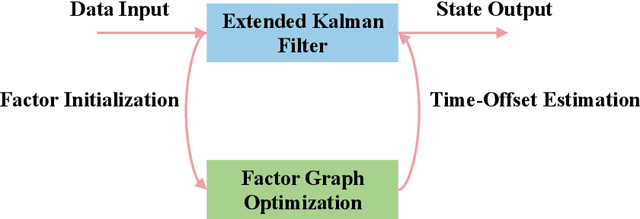
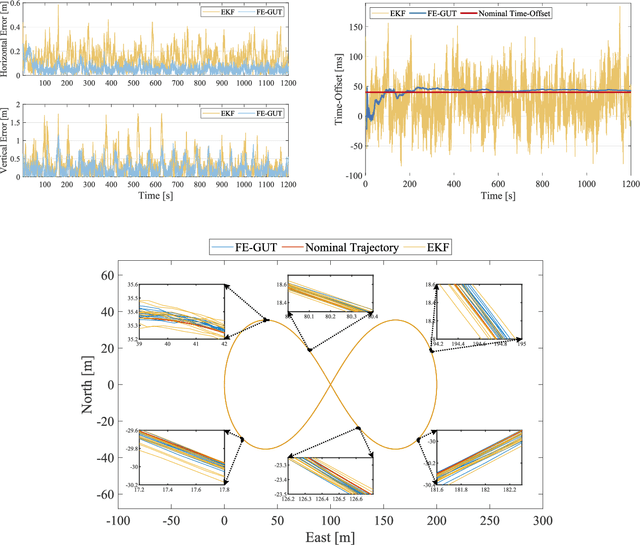
Precise positioning and navigation information has been increasingly important with the development of the consumer electronics market. Due to some deficits of Global Navigation Satellite System (GNSS), such as susceptible to interferences, integrating of GNSS with additional alternative sensors is a promising approach to overcome the performance limitations of GNSS-based localization systems. Ultra-Wideband (UWB) can be used to enhance GNSS in constructing an integrated localization system. However, most low-cost UWB devices lack a hardware-level time synchronization feature, which necessitates the estimation and compensation of the time-offset in the tightly coupled GNSS/UWB integration. Given the flexibility of probabilistic graphical models, the time-offset can be modeled as an invariant constant in the discretization of the continuous model. This work proposes a novel architecture in which Factor Graph Optimization (FGO) is hybrid with Extend Kalman Filter (EKF) for tightly coupled GNSS/UWB integration with online Temporal calibration (FE-GUT). FGO is utilized to precisely estimate the time-offset, while EKF provides initailization for the new factors and performs time-offset compensation. Simulation-based experiments validate the integrated localization performance of FE-GUT. In a four-wheeled robot scenario, the results demonstrate that, compared to EKF, FE-GUT can improve horizontal and vertical localization accuracy by 58.59\% and 34.80\%, respectively, while the time-offset estimation accuracy is improved by 76.80\%. All the source codes and datasets can be gotten via https://github.com/zhaoqj23/FE-GUT/.