 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025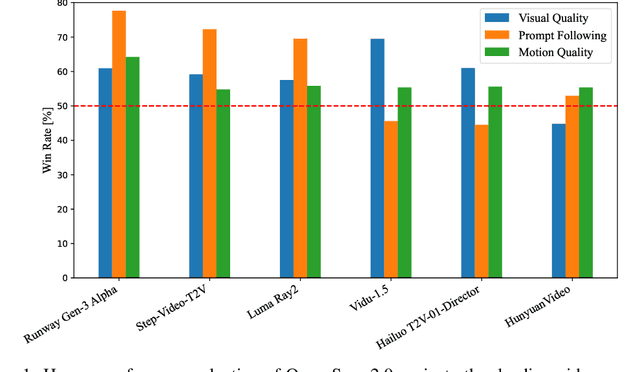


Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
AnimateAnything: Consistent and Controllable Animation for Video Generation
Nov 16, 2024


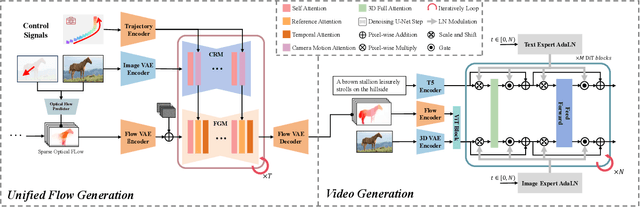
We present a unified controllable video generation approach AnimateAnything that facilitates precise and consistent video manipulation across various conditions, including camera trajectories, text prompts, and user motion annotations. Specifically, we carefully design a multi-scale control feature fusion network to construct a common motion representation for different conditions. It explicitly converts all control information into frame-by-frame optical flows. Then we incorporate the optical flows as motion priors to guide final video generation. In addition, to reduce the flickering issues caused by large-scale motion, we propose a frequency-based stabilization module. It can enhance temporal coherence by ensuring the video's frequency domain consistency. Experiments demonstrate that our method outperforms the state-of-the-art approaches. For more details and videos, please refer to the webpage: https://yu-shaonian.github.io/Animate_Anything/.