 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-MLLM: Captioning and Generating 3D content via Multi-modal Large Language Models
Jan 29, 2026Large Language Models(LLMs) have revolutionized text generation and multimodal perception, but their capabilities in 3D content generation remain underexplored. Existing methods compromise by producing either low-resolution meshes or coarse structural proxies, failing to capture fine-grained geometry natively. In this paper, we propose CG-MLLM, a novel Multi-modal Large Language Model (MLLM) capable of 3D captioning and high-resolution 3D generation in a single framework. Leveraging the Mixture-of-Transformer architecture, CG-MLLM decouples disparate modeling needs, where the Token-level Autoregressive (TokenAR) Transformer handles token-level content, and the Block-level Autoregressive (BlockAR) Transformer handles block-level content. By integrating a pre-trained vision-language backbone with a specialized 3D VAE latent space, CG-MLLM facilitates long-context interactions between standard tokens and spatial blocks within a single integrated architecture. Experimental results show that CG-MLLM significantly outperforms existing MLLMs in generating high-fidelity 3D objects, effectively bringing high-resolution 3D content creation into the mainstream LLM paradigm.
EmoLoom-2B: Fast Base-Model Screening for Emotion Classification and VAD with Lexicon-Weak Supervision and KV-Off Evaluation
Jan 03, 2026We introduce EmoLoom-2B, a lightweight and reproducible pipeline that turns small language models under 2B parameters into fast screening candidates for joint emotion classification and Valence-Arousal-Dominance prediction. To ensure protocol-faithful and fair evaluation, we unify data loading, training, and inference under a single JSON input-output contract and remove avoidable variance by adopting KV-off decoding as the default setting. We incorporate two orthogonal semantic regularizers: a VAD-preserving constraint that aligns generated text with target VAD triples, and a lightweight external appraisal classifier that provides training-time guidance on goal attainment, controllability, certainty, and fairness without injecting long rationales. To improve polarity sensitivity, we introduce Valence Flip augmentation based on mirrored emotional pairs. During supervised fine-tuning, we apply A/B mixture sampling with entropy-aware temperature scheduling to balance coverage and convergence. Using Qwen-1.8B-Chat as the base model, EmoLoom-2B achieves strong performance on GoEmotions and EmpatheticDialogues, and demonstrates robust cross-corpus generalization on DailyDialog. The proposed recipe is budget-aware, auditable, and re-entrant, serving as a dependable screening pass before heavier training or multimodal fusion.
FashionMAC: Deformation-Free Fashion Image Generation with Fine-Grained Model Appearance Customization
Nov 18, 2025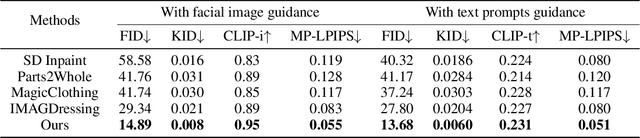
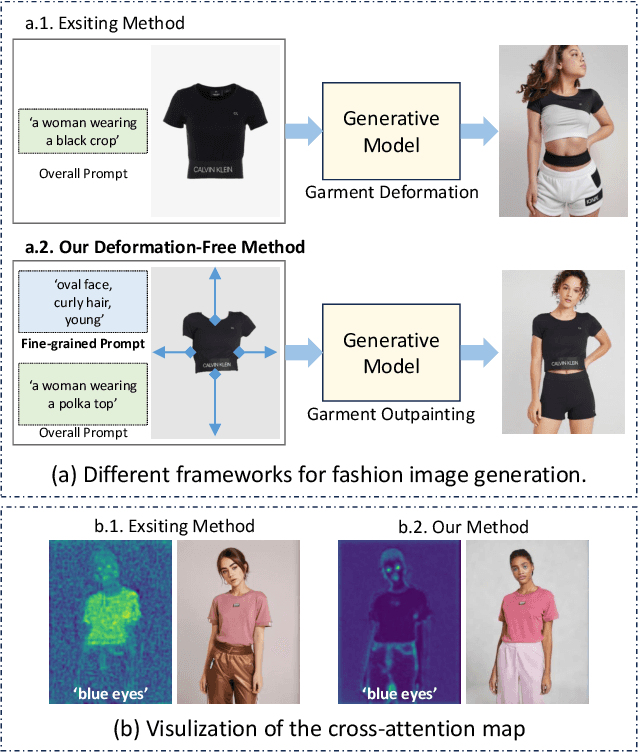

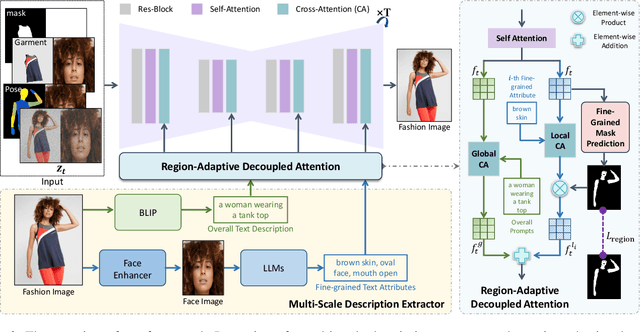
Garment-centric fashion image generation aims to synthesize realistic and controllable human models dressing a given garment, which has attracted growing interest due to its practical applications in e-commerce. The key challenges of the task lie in two aspects: (1) faithfully preserving the garment details, and (2) gaining fine-grained controllability over the model's appearance. Existing methods typically require performing garment deformation in the generation process, which often leads to garment texture distortions. Also, they fail to control the fine-grained attributes of the generated models, due to the lack of specifically designed mechanisms. To address these issues, we propose FashionMAC, a novel diffusion-based deformation-free framework that achieves high-quality and controllable fashion showcase image generation. The core idea of our framework is to eliminate the need for performing garment deformation and directly outpaint the garment segmented from a dressed person, which enables faithful preservation of the intricate garment details. Moreover, we propose a novel region-adaptive decoupled attention (RADA) mechanism along with a chained mask injection strategy to achieve fine-grained appearance controllability over the synthesized human models. Specifically, RADA adaptively predicts the generated regions for each fine-grained text attribute and enforces the text attribute to focus on the predicted regions by a chained mask injection strategy, significantly enhancing the visual fidelity and the controllability. Extensive experiments validate the superior performance of our framework compared to existing state-of-the-art methods.
StableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.
Enhanced Velocity Field Modeling for Gaussian Video Reconstruction
Jul 31, 2025High-fidelity 3D video reconstruction is essential for enabling real-time rendering of dynamic scenes with realistic motion in virtual and augmented reality (VR/AR). The deformation field paradigm of 3D Gaussian splatting has achieved near-photorealistic results in video reconstruction due to the great representation capability of deep deformation networks. However, in videos with complex motion and significant scale variations, deformation networks often overfit to irregular Gaussian trajectories, leading to suboptimal visual quality. Moreover, the gradient-based densification strategy designed for static scene reconstruction proves inadequate to address the absence of dynamic content. In light of these challenges, we propose a flow-empowered velocity field modeling scheme tailored for Gaussian video reconstruction, dubbed FlowGaussian-VR. It consists of two core components: a velocity field rendering (VFR) pipeline which enables optical flow-based optimization, and a flow-assisted adaptive densification (FAD) strategy that adjusts the number and size of Gaussians in dynamic regions. We validate our model's effectiveness on multi-view dynamic reconstruction and novel view synthesis with multiple real-world datasets containing challenging motion scenarios, demonstrating not only notable visual improvements (over 2.5 dB gain in PSNR) and less blurry artifacts in dynamic textures, but also regularized and trackable per-Gaussian trajectories.
Neural Shell Texture Splatting: More Details and Fewer Primitives
Jul 27, 2025Gaussian splatting techniques have shown promising results in novel view synthesis, achieving high fidelity and efficiency. However, their high reconstruction quality comes at the cost of requiring a large number of primitives. We identify this issue as stemming from the entanglement of geometry and appearance in Gaussian Splatting. To address this, we introduce a neural shell texture, a global representation that encodes texture information around the surface. We use Gaussian primitives as both a geometric representation and texture field samplers, efficiently splatting texture features into image space. Our evaluation demonstrates that this disentanglement enables high parameter efficiency, fine texture detail reconstruction, and easy textured mesh extraction, all while using significantly fewer primitives.
SpatialCrafter: Unleashing the Imagination of Video Diffusion Models for Scene Reconstruction from Limited Observations
May 17, 2025Novel view synthesis (NVS) boosts immersive experiences in computer vision and graphics. Existing techniques, though progressed, rely on dense multi-view observations, restricting their application. This work takes on the challenge of reconstructing photorealistic 3D scenes from sparse or single-view inputs. We introduce SpatialCrafter, a framework that leverages the rich knowledge in video diffusion models to generate plausible additional observations, thereby alleviating reconstruction ambiguity. Through a trainable camera encoder and an epipolar attention mechanism for explicit geometric constraints, we achieve precise camera control and 3D consistency, further reinforced by a unified scale estimation strategy to handle scale discrepancies across datasets. Furthermore, by integrating monocular depth priors with semantic features in the video latent space, our framework directly regresses 3D Gaussian primitives and efficiently processes long-sequence features using a hybrid network structure. Extensive experiments show our method enhances sparse view reconstruction and restores the realistic appearance of 3D scenes.
DecoupledGaussian: Object-Scene Decoupling for Physics-Based Interaction
Mar 07, 2025



We present DecoupledGaussian, a novel system that decouples static objects from their contacted surfaces captured in-the-wild videos, a key prerequisite for realistic Newtonian-based physical simulations. Unlike prior methods focused on synthetic data or elastic jittering along the contact surface, which prevent objects from fully detaching or moving independently, DecoupledGaussian allows for significant positional changes without being constrained by the initial contacted surface. Recognizing the limitations of current 2D inpainting tools for restoring 3D locations, our approach proposes joint Poisson fields to repair and expand the Gaussians of both objects and contacted scenes after separation. This is complemented by a multi-carve strategy to refine the object's geometry. Our system enables realistic simulations of decoupling motions, collisions, and fractures driven by user-specified impulses, supporting complex interactions within and across multiple scenes. We validate DecoupledGaussian through a comprehensive user study and quantitative benchmarks. This system enhances digital interaction with objects and scenes in real-world environments, benefiting industries such as VR, robotics, and autonomous driving. Our project page is at: https://wangmiaowei.github.io/DecoupledGaussian.github.io/.
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Mar 03, 2025In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model's appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.
Detail-Preserving Latent Diffusion for Stable Shadow Removal
Dec 23, 2024Achieving high-quality shadow removal with strong generalizability is challenging in scenes with complex global illumination. Due to the limited diversity in shadow removal datasets, current methods are prone to overfitting training data, often leading to reduced performance on unseen cases. To address this, we leverage the rich visual priors of a pre-trained Stable Diffusion (SD) model and propose a two-stage fine-tuning pipeline to adapt the SD model for stable and efficient shadow removal. In the first stage, we fix the VAE and fine-tune the denoiser in latent space, which yields substantial shadow removal but may lose some high-frequency details. To resolve this, we introduce a second stage, called the detail injection stage. This stage selectively extracts features from the VAE encoder to modulate the decoder, injecting fine details into the final results. Experimental results show that our method outperforms state-of-the-art shadow removal techniques. The cross-dataset evaluation further demonstrates that our method generalizes effectively to unseen data, enhancing the applicability of shadow removal methods.