 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRICCARDO: Radar Hit Prediction and Convolution for Camera-Radar 3D Object Detection
Apr 12, 2025Radar hits reflect from points on both the boundary and internal to object outlines. This results in a complex distribution of radar hits that depends on factors including object category, size, and orientation. Current radar-camera fusion methods implicitly account for this with a black-box neural network. In this paper, we explicitly utilize a radar hit distribution model to assist fusion. First, we build a model to predict radar hit distributions conditioned on object properties obtained from a monocular detector. Second, we use the predicted distribution as a kernel to match actual measured radar points in the neighborhood of the monocular detections, generating matching scores at nearby positions. Finally, a fusion stage combines context with the kernel detector to refine the matching scores. Our method achieves the state-of-the-art radar-camera detection performance on nuScenes. Our source code is available at https://github.com/longyunf/riccardo.
DecoupledGaussian: Object-Scene Decoupling for Physics-Based Interaction
Mar 07, 2025



We present DecoupledGaussian, a novel system that decouples static objects from their contacted surfaces captured in-the-wild videos, a key prerequisite for realistic Newtonian-based physical simulations. Unlike prior methods focused on synthetic data or elastic jittering along the contact surface, which prevent objects from fully detaching or moving independently, DecoupledGaussian allows for significant positional changes without being constrained by the initial contacted surface. Recognizing the limitations of current 2D inpainting tools for restoring 3D locations, our approach proposes joint Poisson fields to repair and expand the Gaussians of both objects and contacted scenes after separation. This is complemented by a multi-carve strategy to refine the object's geometry. Our system enables realistic simulations of decoupling motions, collisions, and fractures driven by user-specified impulses, supporting complex interactions within and across multiple scenes. We validate DecoupledGaussian through a comprehensive user study and quantitative benchmarks. This system enhances digital interaction with objects and scenes in real-world environments, benefiting industries such as VR, robotics, and autonomous driving. Our project page is at: https://wangmiaowei.github.io/DecoupledGaussian.github.io/.
Public Computer Vision Datasets for Precision Livestock Farming: A Systematic Survey
Jun 15, 2024



Technology-driven precision livestock farming (PLF) empowers practitioners to monitor and analyze animal growth and health conditions for improved productivity and welfare. Computer vision (CV) is indispensable in PLF by using cameras and computer algorithms to supplement or supersede manual efforts for livestock data acquisition. Data availability is crucial for developing innovative monitoring and analysis systems through artificial intelligence-based techniques. However, data curation processes are tedious, time-consuming, and resource intensive. This study presents the first systematic survey of publicly available livestock CV datasets (https://github.com/Anil-Bhujel/Public-Computer-Vision-Dataset-A-Systematic-Survey). Among 58 public datasets identified and analyzed, encompassing different species of livestock, almost half of them are for cattle, followed by swine, poultry, and other animals. Individual animal detection and color imaging are the dominant application and imaging modality for livestock. The characteristics and baseline applications of the datasets are discussed, emphasizing the implications for animal welfare advocates. Challenges and opportunities are also discussed to inspire further efforts in developing livestock CV datasets. This study highlights that the limited quantity of high-quality annotated datasets collected from diverse environments, animals, and applications, the absence of contextual metadata, are a real bottleneck in PLF.
Self-Annotated 3D Geometric Learning for Smeared Points Removal
Nov 15, 2023



There has been significant progress in improving the accuracy and quality of consumer-level dense depth sensors. Nevertheless, there remains a common depth pixel artifact which we call smeared points. These are points not on any 3D surface and typically occur as interpolations between foreground and background objects. As they cause fictitious surfaces, these points have the potential to harm applications dependent on the depth maps. Statistical outlier removal methods fare poorly in removing these points as they tend also to remove actual surface points. Trained network-based point removal faces difficulty in obtaining sufficient annotated data. To address this, we propose a fully self-annotated method to train a smeared point removal classifier. Our approach relies on gathering 3D geometric evidence from multiple perspectives to automatically detect and annotate smeared points and valid points. To validate the effectiveness of our method, we present a new benchmark dataset: the Real Azure-Kinect dataset. Experimental results and ablation studies show that our method outperforms traditional filters and other self-annotated methods. Our work is publicly available at https://github.com/wangmiaowei/wacv2024_smearedremover.git.
Label-Efficient Learning in Agriculture: A Comprehensive Review
May 24, 2023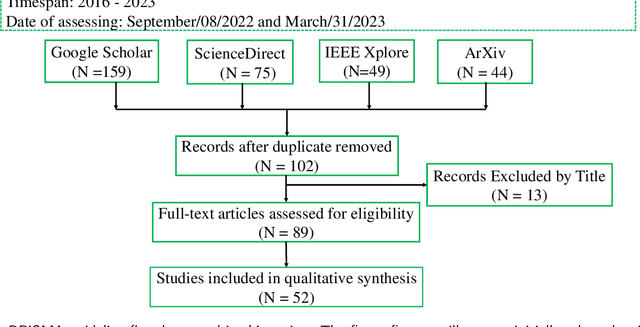
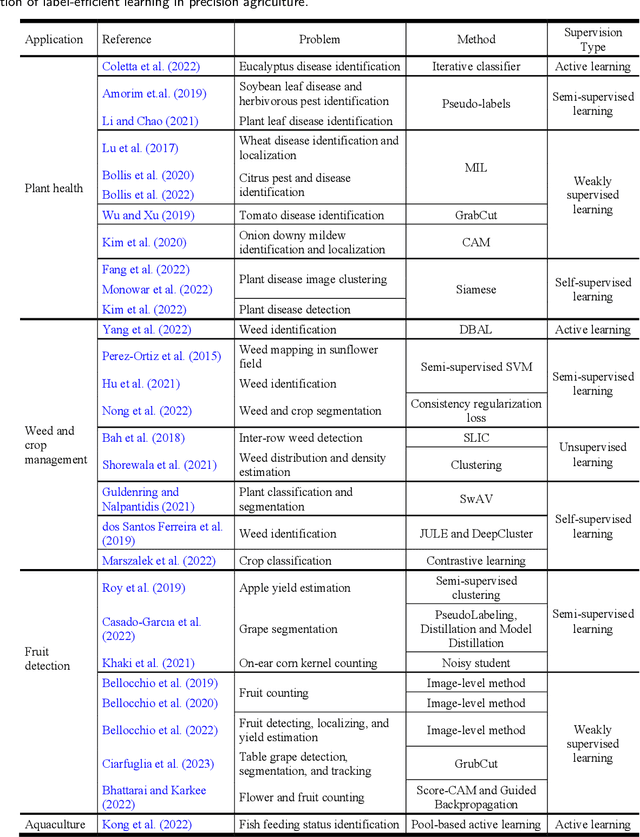
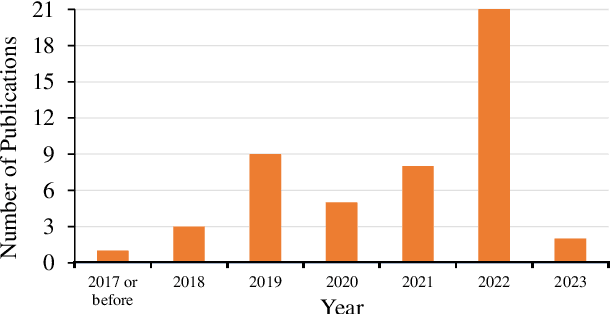
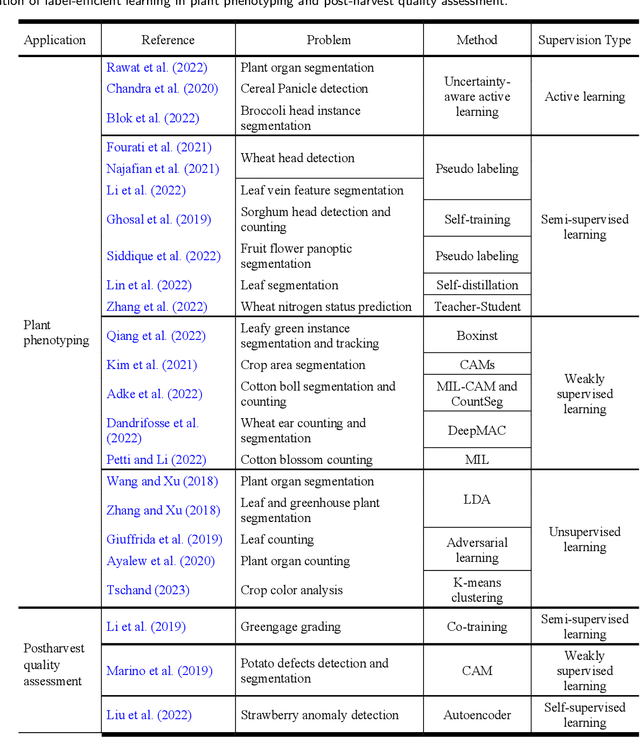
The past decade has witnessed many great successes of machine learning (ML) and deep learning (DL) applications in agricultural systems, including weed control, plant disease diagnosis, agricultural robotics, and precision livestock management. Despite tremendous progresses, one downside of such ML/DL models is that they generally rely on large-scale labeled datasets for training, and the performance of such models is strongly influenced by the size and quality of available labeled data samples. In addition, collecting, processing, and labeling such large-scale datasets is extremely costly and time-consuming, partially due to the rising cost in human labor. Therefore, developing label-efficient ML/DL methods for agricultural applications has received significant interests among researchers and practitioners. In fact, there are more than 50 papers on developing and applying deep-learning-based label-efficient techniques to address various agricultural problems since 2016, which motivates the authors to provide a timely and comprehensive review of recent label-efficient ML/DL methods in agricultural applications. To this end, we first develop a principled taxonomy to organize these methods according to the degree of supervision, including weak supervision (i.e., active learning and semi-/weakly- supervised learning), and no supervision (i.e., un-/self- supervised learning), supplemented by representative state-of-the-art label-efficient ML/DL methods. In addition, a systematic review of various agricultural applications exploiting these label-efficient algorithms, such as precision agriculture, plant phenotyping, and postharvest quality assessment, is presented. Finally, we discuss the current problems and challenges, as well as future research directions. A well-classified paper list can be accessed at https://github.com/DongChen06/Label-efficient-in-Agriculture.
TransCAR: Transformer-based Camera-And-Radar Fusion for 3D Object Detection
Apr 30, 2023Despite radar's popularity in the automotive industry, for fusion-based 3D object detection, most existing works focus on LiDAR and camera fusion. In this paper, we propose TransCAR, a Transformer-based Camera-And-Radar fusion solution for 3D object detection. Our TransCAR consists of two modules. The first module learns 2D features from surround-view camera images and then uses a sparse set of 3D object queries to index into these 2D features. The vision-updated queries then interact with each other via transformer self-attention layer. The second module learns radar features from multiple radar scans and then applies transformer decoder to learn the interactions between radar features and vision-updated queries. The cross-attention layer within the transformer decoder can adaptively learn the soft-association between the radar features and vision-updated queries instead of hard-association based on sensor calibration only. Finally, our model estimates a bounding box per query using set-to-set Hungarian loss, which enables the method to avoid non-maximum suppression. TransCAR improves the velocity estimation using the radar scans without temporal information. The superior experimental results of our TransCAR on the challenging nuScenes datasets illustrate that our TransCAR outperforms state-of-the-art Camera-Radar fusion-based 3D object detection approaches.
Multi-modal Program Inference: a Marriage of Pre-trainedLanguage Models and Component-based Synthesis
Sep 03, 2021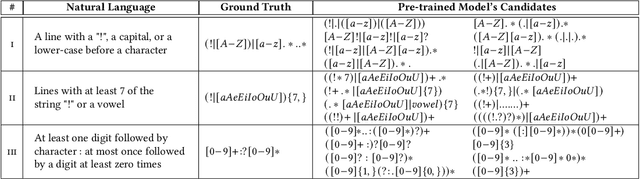
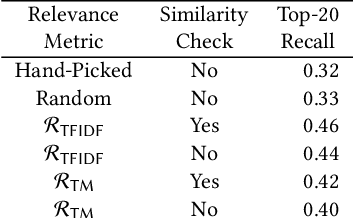


Multi-modal program synthesis refers to the task of synthesizing programs (code) from their specification given in different forms, such as a combination of natural language and examples. Examples provide a precise but incomplete specification, and natural language provides an ambiguous but more "complete" task description. Machine-learned pre-trained models (PTMs) are adept at handling ambiguous natural language, but struggle with generating syntactically and semantically precise code. Program synthesis techniques can generate correct code, often even from incomplete but precise specifications, such as examples, but they are unable to work with the ambiguity of natural languages. We present an approach that combines PTMs with component-based synthesis (CBS): PTMs are used to generate candidates programs from the natural language description of the task, which are then used to guide the CBS procedure to find the program that matches the precise examples-based specification. We use our combination approach to instantiate multi-modal synthesis systems for two programming domains: the domain of regular expressions and the domain of CSS selectors. Our evaluation demonstrates the effectiveness of our domain-agnostic approach in comparison to a state-of-the-art specialized system, and the generality of our approach in providing multi-modal program synthesis from natural language and examples in different programming domains.
Full-Velocity Radar Returns by Radar-Camera Fusion
Aug 24, 2021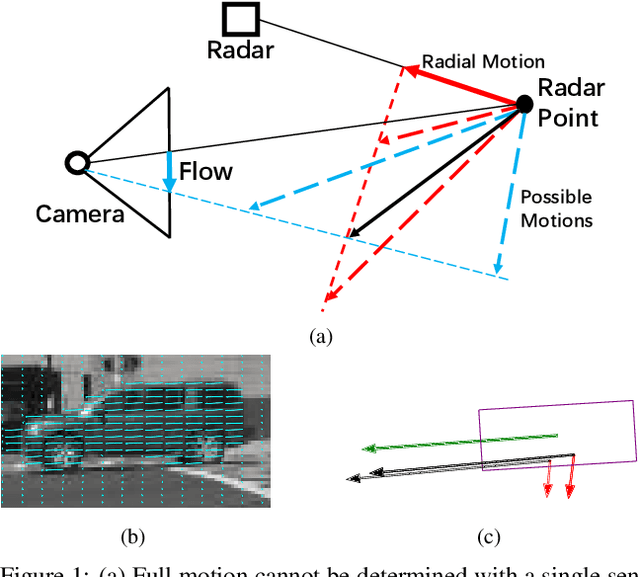
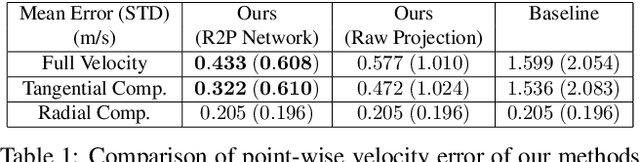

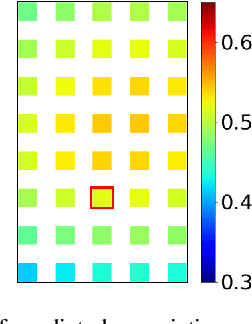
A distinctive feature of Doppler radar is the measurement of velocity in the radial direction for radar points. However, the missing tangential velocity component hampers object velocity estimation as well as temporal integration of radar sweeps in dynamic scenes. Recognizing that fusing camera with radar provides complementary information to radar, in this paper we present a closed-form solution for the point-wise, full-velocity estimate of Doppler returns using the corresponding optical flow from camera images. Additionally, we address the association problem between radar returns and camera images with a neural network that is trained to estimate radar-camera correspondences. Experimental results on the nuScenes dataset verify the validity of the method and show significant improvements over the state-of-the-art in velocity estimation and accumulation of radar points.
Radar-Camera Pixel Depth Association for Depth Completion
Jun 05, 2021



While radar and video data can be readily fused at the detection level, fusing them at the pixel level is potentially more beneficial. This is also more challenging in part due to the sparsity of radar, but also because automotive radar beams are much wider than a typical pixel combined with a large baseline between camera and radar, which results in poor association between radar pixels and color pixel. A consequence is that depth completion methods designed for LiDAR and video fare poorly for radar and video. Here we propose a radar-to-pixel association stage which learns a mapping from radar returns to pixels. This mapping also serves to densify radar returns. Using this as a first stage, followed by a more traditional depth completion method, we are able to achieve image-guided depth completion with radar and video. We demonstrate performance superior to camera and radar alone on the nuScenes dataset. Our source code is available at https://github.com/longyunf/rc-pda.
Depth Completion with Twin Surface Extrapolation at Occlusion Boundaries
Apr 07, 2021



Depth completion starts from a sparse set of known depth values and estimates the unknown depths for the remaining image pixels. Most methods model this as depth interpolation and erroneously interpolate depth pixels into the empty space between spatially distinct objects, resulting in depth-smearing across occlusion boundaries. Here we propose a multi-hypothesis depth representation that explicitly models both foreground and background depths in the difficult occlusion-boundary regions. Our method can be thought of as performing twin-surface extrapolation, rather than interpolation, in these regions. Next our method fuses these extrapolated surfaces into a single depth image leveraging the image data. Key to our method is the use of an asymmetric loss function that operates on a novel twin-surface representation. This enables us to train a network to simultaneously do surface extrapolation and surface fusion. We characterize our loss function and compare with other common losses. Finally, we validate our method on three different datasets; KITTI, an outdoor real-world dataset, NYU2, indoor real-world depth dataset and Virtual KITTI, a photo-realistic synthetic dataset with dense groundtruth, and demonstrate improvement over the state of the art.