 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovBench: Evaluating Large Language Models on Academic Paper Novelty Assessment
Apr 13, 2026Novelty is a core requirement in academic publishing and a central focus of peer review, yet the growing volume of submissions has placed increasing pressure on human reviewers. While large language models (LLMs), including those fine-tuned on peer review data, have shown promise in generating review comments, the absence of a dedicated benchmark has limited systematic evaluation of their ability to assess research novelty. To address this gap, we introduce NovBench, the first large-scale benchmark designed to evaluate LLMs' capability to generate novelty evaluations in support of human peer review. NovBench comprises 1,684 paper-review pairs from a leading NLP conference, including novelty descriptions extracted from paper introductions and corresponding expert-written novelty evaluations. We focus on both sources because the introduction provides a standardized and explicit articulation of novelty claims, while expert-written novelty evaluations constitute one of the current gold standards of human judgment. Furthermore, we propose a four-dimensional evaluation framework (including Relevance, Correctness, Coverage, and Clarity) to assess the quality of LLM-generated novelty evaluations. Extensive experiments on both general and specialized LLMs under different prompting strategies reveal that current models exhibit limited understanding of scientific novelty, and that fine--tuned models often suffer from instruction-following deficiencies. These findings underscore the need for targeted fine-tuning strategies that jointly improve novelty comprehension and instruction adherence.
CALM: Culturally Self-Aware Language Models
Jan 07, 2026Cultural awareness in language models is the capacity to understand and adapt to diverse cultural contexts. However, most existing approaches treat culture as static background knowledge, overlooking its dynamic and evolving nature. This limitation reduces their reliability in downstream tasks that demand genuine cultural sensitivity. In this work, we introduce CALM, a novel framework designed to endow language models with cultural self-awareness. CALM disentangles task semantics from explicit cultural concepts and latent cultural signals, shaping them into structured cultural clusters through contrastive learning. These clusters are then aligned via cross-attention to establish fine-grained interactions among related cultural features and are adaptively integrated through a Mixture-of-Experts mechanism along culture-specific dimensions. The resulting unified representation is fused with the model's original knowledge to construct a culturally grounded internal identity state, which is further enhanced through self-prompted reflective learning, enabling continual adaptation and self-correction. Extensive experiments conducted on multiple cross-cultural benchmark datasets demonstrate that CALM consistently outperforms state-of-the-art methods.
Learn to Select: Exploring Label Distribution Divergence for In-Context Demonstration Selection in Text Classification
Nov 10, 2025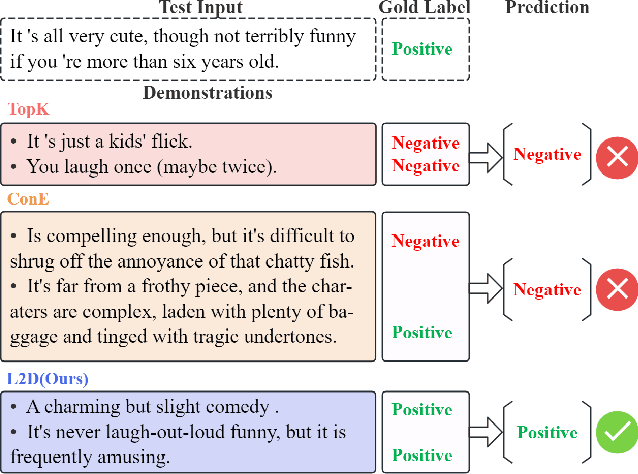
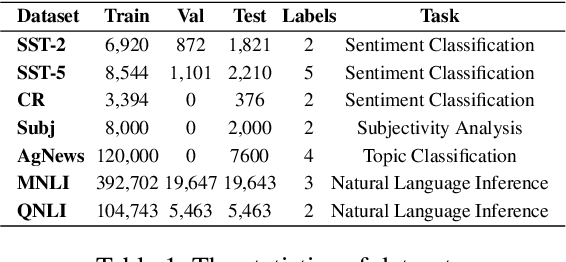
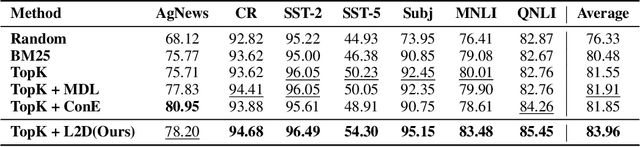
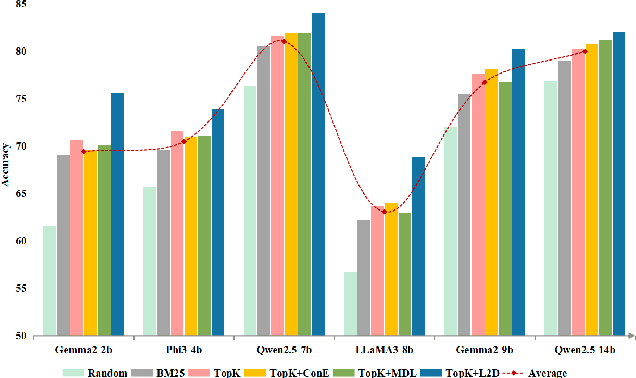
In-context learning (ICL) for text classification, which uses a few input-label demonstrations to describe a task, has demonstrated impressive performance on large language models (LLMs). However, the selection of in-context demonstrations plays a crucial role and can significantly affect LLMs' performance. Most existing demonstration selection methods primarily focus on semantic similarity between test inputs and demonstrations, often overlooking the importance of label distribution alignment. To address this limitation, we propose a two-stage demonstration selection method, TopK + Label Distribution Divergence (L2D), which leverages a fine-tuned BERT-like small language model (SLM) to generate label distributions and calculate their divergence for both test inputs and candidate demonstrations. This enables the selection of demonstrations that are not only semantically similar but also aligned in label distribution with the test input. Extensive experiments across seven text classification benchmarks show that our method consistently outperforms previous demonstration selection strategies. Further analysis reveals a positive correlation between the performance of LLMs and the accuracy of the underlying SLMs used for label distribution estimation.
Learning to Play Like Humans: A Framework for LLM Adaptation in Interactive Fiction Games
May 18, 2025Interactive Fiction games (IF games) are where players interact through natural language commands. While recent advances in Artificial Intelligence agents have reignited interest in IF games as a domain for studying decision-making, existing approaches prioritize task-specific performance metrics over human-like comprehension of narrative context and gameplay logic. This work presents a cognitively inspired framework that guides Large Language Models (LLMs) to learn and play IF games systematically. Our proposed **L**earning to **P**lay **L**ike **H**umans (LPLH) framework integrates three key components: (1) structured map building to capture spatial and narrative relationships, (2) action learning to identify context-appropriate commands, and (3) feedback-driven experience analysis to refine decision-making over time. By aligning LLMs-based agents' behavior with narrative intent and commonsense constraints, LPLH moves beyond purely exploratory strategies to deliver more interpretable, human-like performance. Crucially, this approach draws on cognitive science principles to more closely simulate how human players read, interpret, and respond within narrative worlds. As a result, LPLH reframes the IF games challenge as a learning problem for LLMs-based agents, offering a new path toward robust, context-aware gameplay in complex text-based environments.
RICCARDO: Radar Hit Prediction and Convolution for Camera-Radar 3D Object Detection
Apr 12, 2025Radar hits reflect from points on both the boundary and internal to object outlines. This results in a complex distribution of radar hits that depends on factors including object category, size, and orientation. Current radar-camera fusion methods implicitly account for this with a black-box neural network. In this paper, we explicitly utilize a radar hit distribution model to assist fusion. First, we build a model to predict radar hit distributions conditioned on object properties obtained from a monocular detector. Second, we use the predicted distribution as a kernel to match actual measured radar points in the neighborhood of the monocular detections, generating matching scores at nearby positions. Finally, a fusion stage combines context with the kernel detector to refine the matching scores. Our method achieves the state-of-the-art radar-camera detection performance on nuScenes. Our source code is available at https://github.com/longyunf/riccardo.
Less but Better: Parameter-Efficient Fine-Tuning of Large Language Models for Personality Detection
Apr 07, 2025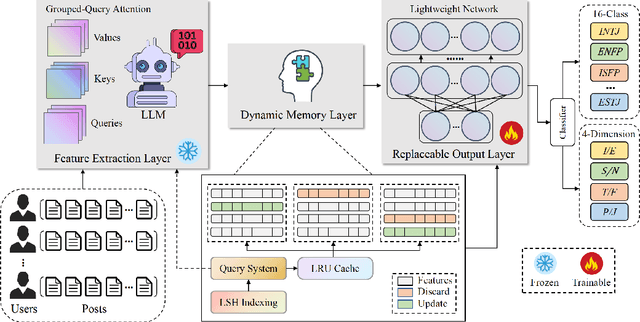
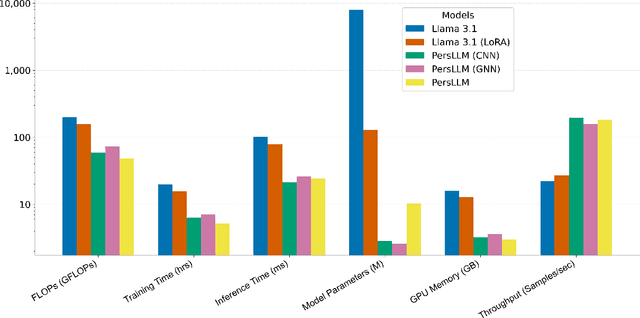
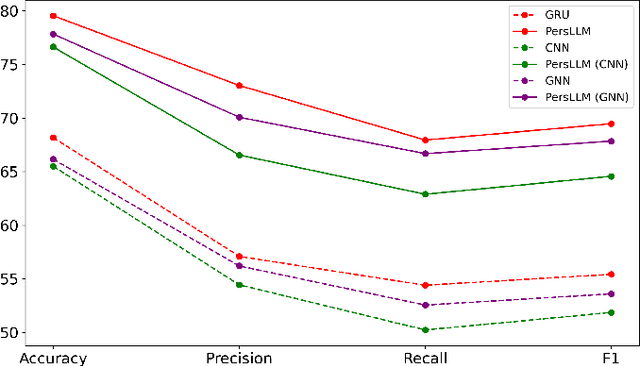
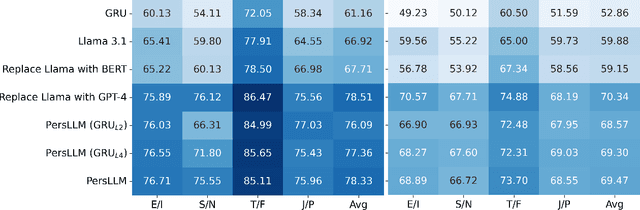
Personality detection automatically identifies an individual's personality from various data sources, such as social media texts. However, as the parameter scale of language models continues to grow, the computational cost becomes increasingly difficult to manage. Fine-tuning also grows more complex, making it harder to justify the effort and reliably predict outcomes. We introduce a novel parameter-efficient fine-tuning framework, PersLLM, to address these challenges. In PersLLM, a large language model (LLM) extracts high-dimensional representations from raw data and stores them in a dynamic memory layer. PersLLM then updates the downstream layers with a replaceable output network, enabling flexible adaptation to various personality detection scenarios. By storing the features in the memory layer, we eliminate the need for repeated complex computations by the LLM. Meanwhile, the lightweight output network serves as a proxy for evaluating the overall effectiveness of the framework, improving the predictability of results. Experimental results on key benchmark datasets like Kaggle and Pandora show that PersLLM significantly reduces computational cost while maintaining competitive performance and strong adaptability.
LL4G: Self-Supervised Dynamic Optimization for Graph-Based Personality Detection
Apr 02, 2025Graph-based personality detection constructs graph structures from textual data, particularly social media posts. Current methods often struggle with sparse or noisy data and rely on static graphs, limiting their ability to capture dynamic changes between nodes and relationships. This paper introduces LL4G, a self-supervised framework leveraging large language models (LLMs) to optimize graph neural networks (GNNs). LLMs extract rich semantic features to generate node representations and to infer explicit and implicit relationships. The graph structure adaptively adds nodes and edges based on input data, continuously optimizing itself. The GNN then uses these optimized representations for joint training on node reconstruction, edge prediction, and contrastive learning tasks. This integration of semantic and structural information generates robust personality profiles. Experimental results on Kaggle and Pandora datasets show LL4G outperforms state-of-the-art models.
XIFBench: Evaluating Large Language Models on Multilingual Instruction Following
Mar 10, 2025Large Language Models (LLMs) have demonstrated remarkable instruction-following capabilities across various applications. However, their performance in multilingual settings remains poorly understood, as existing evaluations lack fine-grained constraint analysis. We introduce XIFBench, a comprehensive constraint-based benchmark for assessing multilingual instruction-following abilities of LLMs, featuring a novel taxonomy of five constraint categories and 465 parallel instructions across six languages spanning different resource levels. To ensure consistent cross-lingual evaluation, we develop a requirement-based protocol that leverages English requirements as semantic anchors. These requirements are then used to validate the translations across languages. Extensive experiments with various LLMs reveal notable variations in instruction-following performance across resource levels, identifying key influencing factors such as constraint categories, instruction complexity, and cultural specificity.
Generator-Assistant Stepwise Rollback Framework for Large Language Model Agent
Mar 04, 2025



Large language model (LLM) agents typically adopt a step-by-step reasoning framework, in which they interleave the processes of thinking and acting to accomplish the given task. However, this paradigm faces a deep-rooted one-pass issue whereby each generated intermediate thought is plugged into the trajectory regardless of its correctness, which can cause irreversible error propagation. To address the issue, this paper proposes a novel framework called Generator-Assistant Stepwise Rollback (GA-Rollback) to induce better decision-making for LLM agents. Particularly, GA-Rollback utilizes a generator to interact with the environment and an assistant to examine each action produced by the generator, where the assistant triggers a rollback operation upon detection of incorrect actions. Moreover, we introduce two additional strategies tailored for the rollback scenario to further improve its effectiveness. Extensive experiments show that GA-Rollback achieves significant improvements over several strong baselines on three widely used benchmarks. Our analysis further reveals that GA-Rollback can function as a robust plug-and-play module, integrating seamlessly with other methods.
Detecting harassment and defamation in cyberbullying with emotion-adaptive training
Jan 28, 2025



Existing research on detecting cyberbullying incidents on social media has primarily concentrated on harassment and is typically approached as a binary classification task. However, cyberbullying encompasses various forms, such as denigration and harassment, which celebrities frequently face. Furthermore, suitable training data for these diverse forms of cyberbullying remains scarce. In this study, we first develop a celebrity cyberbullying dataset that encompasses two distinct types of incidents: harassment and defamation. We investigate various types of transformer-based models, namely masked (RoBERTa, Bert and DistilBert), replacing(Electra), autoregressive (XLnet), masked&permuted (Mpnet), text-text (T5) and large language models (Llama2 and Llama3) under low source settings. We find that they perform competitively on explicit harassment binary detection. However, their performance is substantially lower on harassment and denigration multi-classification tasks. Therefore, we propose an emotion-adaptive training framework (EAT) that helps transfer knowledge from the domain of emotion detection to the domain of cyberbullying detection to help detect indirect cyberbullying events. EAT consistently improves the average macro F1, precision and recall by 20% in cyberbullying detection tasks across nine transformer-based models under low-resource settings. Our claims are supported by intuitive theoretical insights and extensive experiments.