 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerator-Assistant Stepwise Rollback Framework for Large Language Model Agent
Mar 04, 2025



Large language model (LLM) agents typically adopt a step-by-step reasoning framework, in which they interleave the processes of thinking and acting to accomplish the given task. However, this paradigm faces a deep-rooted one-pass issue whereby each generated intermediate thought is plugged into the trajectory regardless of its correctness, which can cause irreversible error propagation. To address the issue, this paper proposes a novel framework called Generator-Assistant Stepwise Rollback (GA-Rollback) to induce better decision-making for LLM agents. Particularly, GA-Rollback utilizes a generator to interact with the environment and an assistant to examine each action produced by the generator, where the assistant triggers a rollback operation upon detection of incorrect actions. Moreover, we introduce two additional strategies tailored for the rollback scenario to further improve its effectiveness. Extensive experiments show that GA-Rollback achieves significant improvements over several strong baselines on three widely used benchmarks. Our analysis further reveals that GA-Rollback can function as a robust plug-and-play module, integrating seamlessly with other methods.
LLM with Relation Classifier for Document-Level Relation Extraction
Aug 25, 2024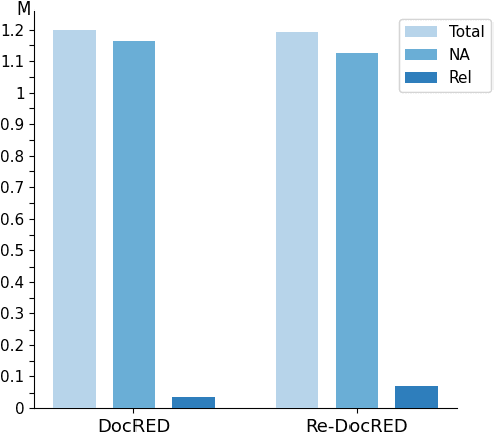


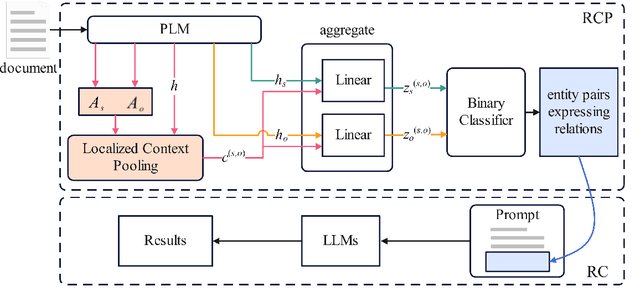
Large language models (LLMs) create a new paradigm for natural language processing. Despite their advancement, LLM-based methods still lag behind traditional approaches in document-level relation extraction (DocRE), a critical task for understanding complex entity relations. This paper investigates the causes of this performance gap, identifying the dispersion of attention by LLMs due to entity pairs without relations as a primary factor. We then introduce a novel classifier-LLM approach to DocRE. The proposed approach begins with a classifier specifically designed to select entity pair candidates exhibiting potential relations and thereby feeds them to LLM for the final relation extraction. This method ensures that during inference, the LLM's focus is directed primarily at entity pairs with relations. Experiments on DocRE benchmarks reveal that our method significantly outperforms recent LLM-based DocRE models and achieves competitive performance with several leading traditional DocRE models.