 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers
Jan 24, 2026The quadratic complexity of standard attention mechanisms poses a significant scalability bottleneck for large language models (LLMs) in long-context scenarios. While hybrid attention strategies that combine sparse and full attention within a single model offer a viable solution, they typically employ static computation ratios (i.e., fixed proportions of sparse versus full attention) and fail to adapt to the varying sparsity sensitivities of downstream tasks during inference. To address this issue, we propose Elastic Attention, which allows the model to dynamically adjust its overall sparsity based on the input. This is achieved by integrating a lightweight Attention Router into the existing pretrained model, which dynamically assigns each attention head to different computation modes. Within only 12 hours of training on 8xA800 GPUs, our method enables models to achieve both strong performance and efficient inference. Experiments across three long-context benchmarks on widely-used LLMs demonstrate the superiority of our method.
MemoryRewardBench: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 24, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce MemoryRewardBench, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. MemoryRewardBench covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
$\texttt{MemoryRewardBench}$: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 17, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce $\texttt{MemoryRewardBench}$, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. $\texttt{MemoryRewardBench}$ covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
Accelerate Speculative Decoding with Sparse Computation in Verification
Dec 26, 2025Speculative decoding accelerates autoregressive language model inference by verifying multiple draft tokens in parallel. However, the verification stage often becomes the dominant computational bottleneck, especially for long-context inputs and mixture-of-experts (MoE) models. Existing sparsification methods are designed primarily for standard token-by-token autoregressive decoding to remove substantial computational redundancy in LLMs. This work systematically adopts different sparse methods on the verification stage of the speculative decoding and identifies structured redundancy across multiple dimensions. Based on these observations, we propose a sparse verification framework that jointly sparsifies attention, FFN, and MoE components during the verification stage to reduce the dominant computation cost. The framework further incorporates an inter-draft token and inter-layer retrieval reuse strategy to further reduce redundant computation without introducing additional training. Extensive experiments across summarization, question answering, and mathematical reasoning datasets demonstrate that the proposed methods achieve favorable efficiency-accuracy trade-offs, while maintaining stable acceptance length.
Overview of CHIP 2025 Shared Task 2: Discharge Medication Recommendation for Metabolic Diseases Based on Chinese Electronic Health Records
Nov 09, 2025Discharge medication recommendation plays a critical role in ensuring treatment continuity, preventing readmission, and improving long-term management for patients with chronic metabolic diseases. This paper present an overview of the CHIP 2025 Shared Task 2 competition, which aimed to develop state-of-the-art approaches for automatically recommending appro-priate discharge medications using real-world Chinese EHR data. For this task, we constructed CDrugRed, a high-quality dataset consisting of 5,894 de-identified hospitalization records from 3,190 patients in China. This task is challenging due to multi-label nature of medication recommendation, het-erogeneous clinical text, and patient-specific variability in treatment plans. A total of 526 teams registered, with 167 and 95 teams submitting valid results to the Phase A and Phase B leaderboards, respectively. The top-performing team achieved the highest overall performance on the final test set, with a Jaccard score of 0.5102, F1 score of 0.6267, demonstrating the potential of advanced large language model (LLM)-based ensemble systems. These re-sults highlight both the promise and remaining challenges of applying LLMs to medication recommendation in Chinese EHRs. The post-evaluation phase remains open at https://tianchi.aliyun.com/competition/entrance/532411/.
FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
Oct 26, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models (LLMs). In this context, models explore reasoning trajectories and exploit rollouts with correct answers as positive signals for policy optimization. However, these rollouts might involve flawed patterns such as answer-guessing and jump-in-reasoning. Such flawed-positive rollouts are rewarded identically to fully correct ones, causing policy models to internalize these unreliable reasoning patterns. In this work, we first conduct a systematic study of flawed-positive rollouts in RL and find that they enable rapid capability gains during the early optimization stage, while constraining reasoning capability later by reinforcing unreliable patterns. Building on these insights, we propose Flawed-Aware Policy Optimization (FAPO), which presents a parameter-free reward penalty for flawed-positive rollouts, enabling the policy to leverage them as useful shortcuts in the warm-up stage, securing stable early gains, while gradually shifting optimization toward reliable reasoning in the later refinement stage. To accurately and comprehensively detect flawed-positive rollouts, we introduce a generative reward model (GenRM) with a process-level reward that precisely localizes reasoning errors. Experiments show that FAPO is effective in broad domains, improving outcome correctness, process reliability, and training stability without increasing the token budget.
LongRM: Revealing and Unlocking the Context Boundary of Reward Modeling
Oct 08, 2025Reward model (RM) plays a pivotal role in aligning large language model (LLM) with human preferences. As real-world applications increasingly involve long history trajectories, e.g., LLM agent, it becomes indispensable to evaluate whether a model's responses are not only high-quality but also grounded in and consistent with the provided context. Yet, current RMs remain confined to short-context settings and primarily focus on response-level attributes (e.g., safety or helpfulness), while largely neglecting the critical dimension of long context-response consistency. In this work, we introduce Long-RewardBench, a benchmark specifically designed for long-context RM evaluation, featuring both Pairwise Comparison and Best-of-N tasks. Our preliminary study reveals that even state-of-the-art generative RMs exhibit significant fragility in long-context scenarios, failing to maintain context-aware preference judgments. Motivated by the analysis of failure patterns observed in model outputs, we propose a general multi-stage training strategy that effectively scales arbitrary models into robust Long-context RMs (LongRMs). Experiments show that our approach not only substantially improves performance on long-context evaluation but also preserves strong short-context capability. Notably, our 8B LongRM outperforms much larger 70B-scale baselines and matches the performance of the proprietary Gemini 2.5 Pro model.
BatonVoice: An Operationalist Framework for Enhancing Controllable Speech Synthesis with Linguistic Intelligence from LLMs
Sep 30, 2025The rise of Large Language Models (LLMs) is reshaping multimodel models, with speech synthesis being a prominent application. However, existing approaches often underutilize the linguistic intelligence of these models, typically failing to leverage their powerful instruction-following capabilities. This limitation hinders the model's ability to follow text instructions for controllable Text-to-Speech~(TTS). To address this, we propose a new paradigm inspired by ``operationalism'' that decouples instruction understanding from speech generation. We introduce BatonVoice, a framework where an LLM acts as a ``conductor'', understanding user instructions and generating a textual ``plan'' -- explicit vocal features (e.g., pitch, energy). A separate TTS model, the ``orchestra'', then generates the speech from these features. To realize this component, we develop BatonTTS, a TTS model trained specifically for this task. Our experiments demonstrate that BatonVoice achieves strong performance in controllable and emotional speech synthesis, outperforming strong open- and closed-source baselines. Notably, our approach enables remarkable zero-shot cross-lingual generalization, accurately applying feature control abilities to languages unseen during post-training. This demonstrates that objectifying speech into textual vocal features can more effectively unlock the linguistic intelligence of LLMs.
Learning Active Perception via Self-Evolving Preference Optimization for GUI Grounding
Sep 04, 2025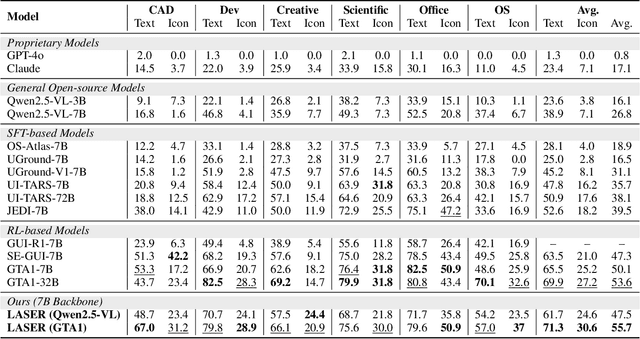



Vision Language Models (VLMs) have recently achieved significant progress in bridging visual perception and linguistic reasoning. Recently, OpenAI o3 model introduced a zoom-in search strategy that effectively elicits active perception capabilities in VLMs, improving downstream task performance. However, enabling VLMs to reason effectively over appropriate image regions remains a core challenge in GUI grounding, particularly under high-resolution inputs and complex multi-element visual interactions. In this work, we propose LASER, a self-evolving framework that progressively endows VLMs with multi-step perception capabilities, enabling precise coordinate prediction. Specifically, our approach integrate Monte Carlo quality estimation with Intersection-over-Union (IoU)-based region quality evaluation to jointly encourage both accuracy and diversity in constructing high-quality preference data. This combination explicitly guides the model to focus on instruction-relevant key regions while adaptively allocating reasoning steps based on task complexity. Comprehensive experiments on the ScreenSpot Pro and ScreenSpot-v2 benchmarks demonstrate consistent performance gains, validating the effectiveness of our method. Furthermore, when fine-tuned on GTA1-7B, LASER achieves a score of 55.7 on the ScreenSpot-Pro benchmark, establishing a new state-of-the-art (SoTA) among 7B-scale models.
Unlocking Recursive Thinking of LLMs: Alignment via Refinement
Jun 06, 2025The OpenAI o1-series models have demonstrated that leveraging long-form Chain of Thought (CoT) can substantially enhance performance. However, the recursive thinking capabilities of Large Language Models (LLMs) remain limited, particularly in the absence of expert-curated data for distillation. In this paper, we propose \textbf{AvR}: \textbf{Alignment via Refinement}, a novel method aimed at unlocking the potential of LLMs for recursive reasoning through long-form CoT. AvR introduces a refinement process that integrates criticism and improvement actions, guided by differentiable learning techniques to optimize \textbf{refinement-aware rewards}. As a result, the synthesized multi-round data can be organized as a long refinement thought, further enabling test-time scaling. Experimental results show that AvR significantly outperforms conventional preference optimization methods. Notably, with only 3k synthetic samples, our method boosts the performance of the LLaMA-3-8B-Instruct model by over 20\% in win rate on AlpacaEval 2.0. Our code is available at Github (https://github.com/Banner-Z/AvR.git).