 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Personality: A Human Simulation Perspective to Investigate Large Language Model Agents
Paper and Code
Feb 28, 2025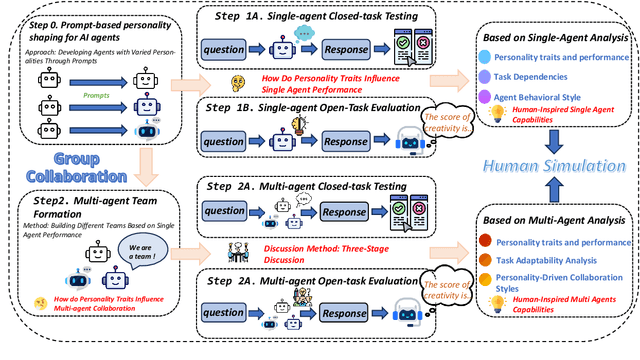
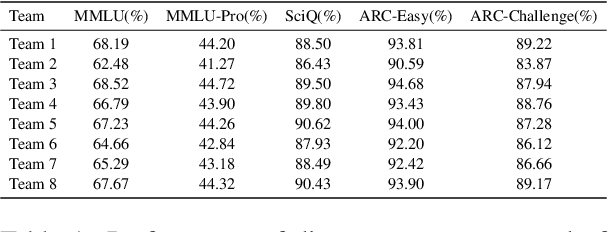
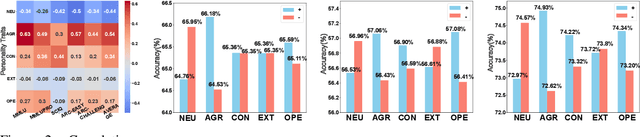

Large language models (LLMs) excel in both closed tasks (including problem-solving, and code generation) and open tasks (including creative writing), yet existing explanations for their capabilities lack connections to real-world human intelligence. To fill this gap, this paper systematically investigates LLM intelligence through the lens of ``human simulation'', addressing three core questions: (1) How do personality traits affect problem-solving in closed tasks? (2) How do traits shape creativity in open tasks? (3) How does single-agent performance influence multi-agent collaboration? By assigning Big Five personality traits to LLM agents and evaluating their performance in single- and multi-agent settings, we reveal that specific traits significantly influence reasoning accuracy (closed tasks) and creative output (open tasks). Furthermore, multi-agent systems exhibit collective intelligence distinct from individual capabilities, driven by distinguishing combinations of personalities. We demonstrate that LLMs inherently simulate human behavior through next-token prediction, mirroring human language, decision-making, and collaborative dynamics.