 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Apr 02, 2026Large language model (LLM)-based evolution is a promising approach for open-ended discovery, where progress requires sustained search and knowledge accumulation. Existing methods still rely heavily on fixed heuristics and hard-coded exploration rules, which limit the autonomy of LLM agents. We present CORAL, the first framework for autonomous multi-agent evolution on open-ended problems. CORAL replaces rigid control with long-running agents that explore, reflect, and collaborate through shared persistent memory, asynchronous multi-agent execution, and heartbeat-based interventions. It also provides practical safeguards, including isolated workspaces, evaluator separation, resource management, and agent session and health management. Evaluated on diverse mathematical, algorithmic, and systems optimization tasks, CORAL sets new state-of-the-art results on 10 tasks, achieving 3-10 times higher improvement rates with far fewer evaluations than fixed evolutionary search baselines across tasks. On Anthropic's kernel engineering task, four co-evolving agents improve the best known score from 1363 to 1103 cycles. Mechanistic analyses further show how these gains arise from knowledge reuse and multi-agent exploration and communication. Together, these results suggest that greater agent autonomy and multi-agent evolution can substantially improve open-ended discovery. Code is available at https://github.com/Human-Agent-Society/CORAL.
ADV-0: Closed-Loop Min-Max Adversarial Training for Long-Tail Robustness in Autonomous Driving
Mar 16, 2026Deploying autonomous driving systems requires robustness against long-tail scenarios that are rare but safety-critical. While adversarial training offers a promising solution, existing methods typically decouple scenario generation from policy optimization and rely on heuristic surrogates. This leads to objective misalignment and fails to capture the shifting failure modes of evolving policies. This paper presents ADV-0, a closed-loop min-max optimization framework that treats the interaction between driving policy (defender) and adversarial agent (attacker) as a zero-sum Markov game. By aligning the attacker's utility directly with the defender's objective, we reveal the optimal adversary distribution. To make this tractable, we cast dynamic adversary evolution as iterative preference learning, efficiently approximating this optimum and offering an algorithm-agnostic solution to the game. Theoretically, ADV-0 converges to a Nash Equilibrium and maximizes a certified lower bound on real-world performance. Experiments indicate that it effectively exposes diverse safety-critical failures and greatly enhances the generalizability of both learned policies and motion planners against unseen long-tail risks.
Character-R1: Enhancing Role-Aware Reasoning in Role-Playing Agents via RLVR
Jan 08, 2026Current role-playing agents (RPAs) are typically constructed by imitating surface-level behaviors, but this approach lacks internal cognitive consistency, often causing out-of-character errors in complex situations. To address this, we propose Character-R1, a framework designed to provide comprehensive verifiable reward signals for effective role-aware reasoning, which are missing in recent studies. Specifically, our framework comprises three core designs: (1) Cognitive Focus Reward, which enforces explicit label-based analysis of 10 character elements (e.g., worldview) to structure internal cognition; (2) Reference-Guided Reward, which utilizes overlap-based metrics with reference responses as optimization anchors to enhance exploration and performance; and (3) Character-Conditioned Reward Normalization, which adjusts reward distributions based on character categories to ensure robust optimization across heterogeneous roles. Extensive experiments demonstrate that Character-R1 significantly outperforms existing methods in knowledge, memory and others.
Large Language Models for Data Synthesis
May 20, 2025Generating synthetic data that faithfully captures the statistical structure of real-world distributions is a fundamental challenge in data modeling. Classical approaches often depend on strong parametric assumptions or manual structural design and struggle in high-dimensional or heterogeneous domains. Recent progress in Large Language Models (LLMs) reveals their potential as flexible, high-dimensional priors over real-world distributions. However, when applied to data synthesis, standard LLM-based sampling is inefficient, constrained by fixed context limits, and fails to ensure statistical alignment. Given this, we introduce LLMSynthor, a general framework for data synthesis that transforms LLMs into structure-aware simulators guided by distributional feedback. LLMSynthor treats the LLM as a nonparametric copula simulator for modeling high-order dependencies and introduces LLM Proposal Sampling to generate grounded proposal distributions that improve sampling efficiency without requiring rejection. By minimizing discrepancies in the summary statistics space, the iterative synthesis loop aligns real and synthetic data while gradually uncovering and refining the latent generative structure. We evaluate LLMSynthor in both controlled and real-world settings using heterogeneous datasets in privacy-sensitive domains (e.g., e-commerce, population, and mobility) that encompass both structured and unstructured formats. The synthetic data produced by LLMSynthor shows high statistical fidelity, practical utility, and cross-data adaptability, positioning it as a valuable tool across economics, social science, urban studies, and beyond.
Reimagining Urban Science: Scaling Causal Inference with Large Language Models
Apr 15, 2025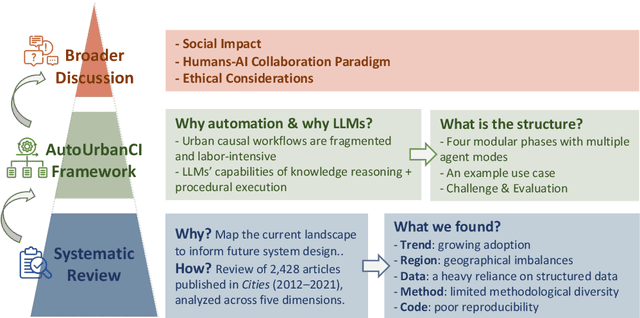
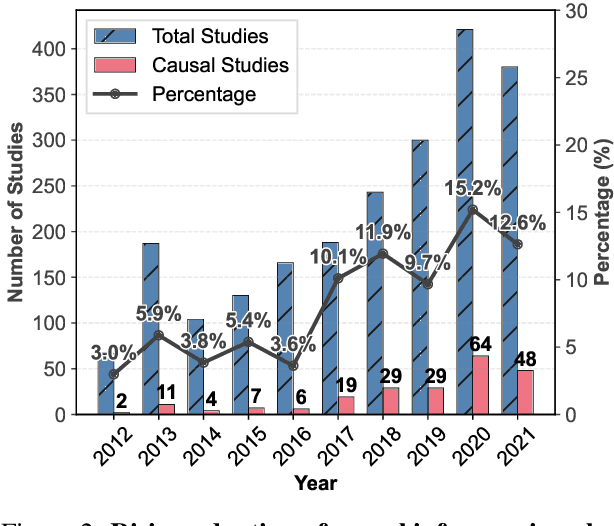

Urban causal research is essential for understanding the complex dynamics of cities and informing evidence-based policies. However, it is challenged by the inefficiency and bias of hypothesis generation, barriers to multimodal data complexity, and the methodological fragility of causal experimentation. Recent advances in large language models (LLMs) present an opportunity to rethink how urban causal analysis is conducted. This Perspective examines current urban causal research by analyzing taxonomies that categorize research topics, data sources, and methodological approaches to identify structural gaps. We then introduce an LLM-driven conceptual framework, AutoUrbanCI, composed of four distinct modular agents responsible for hypothesis generation, data engineering, experiment design and execution, and results interpretation with policy recommendations. We propose evaluation criteria for rigor and transparency and reflect on implications for human-AI collaboration, equity, and accountability. We call for a new research agenda that embraces AI-augmented workflows not as replacements for human expertise but as tools to broaden participation, improve reproducibility, and unlock more inclusive forms of urban causal reasoning.
Vision-to-Music Generation: A Survey
Mar 27, 2025Vision-to-music Generation, including video-to-music and image-to-music tasks, is a significant branch of multimodal artificial intelligence demonstrating vast application prospects in fields such as film scoring, short video creation, and dance music synthesis. However, compared to the rapid development of modalities like text and images, research in vision-to-music is still in its preliminary stage due to its complex internal structure and the difficulty of modeling dynamic relationships with video. Existing surveys focus on general music generation without comprehensive discussion on vision-to-music. In this paper, we systematically review the research progress in the field of vision-to-music generation. We first analyze the technical characteristics and core challenges for three input types: general videos, human movement videos, and images, as well as two output types of symbolic music and audio music. We then summarize the existing methodologies on vision-to-music generation from the architecture perspective. A detailed review of common datasets and evaluation metrics is provided. Finally, we discuss current challenges and promising directions for future research. We hope our survey can inspire further innovation in vision-to-music generation and the broader field of multimodal generation in academic research and industrial applications. To follow latest works and foster further innovation in this field, we are continuously maintaining a GitHub repository at https://github.com/wzk1015/Awesome-Vision-to-Music-Generation.
INTENT: Trajectory Prediction Framework with Intention-Guided Contrastive Clustering
Mar 06, 2025Accurate trajectory prediction of road agents (e.g., pedestrians, vehicles) is an essential prerequisite for various intelligent systems applications, such as autonomous driving and robotic navigation. Recent research highlights the importance of environmental contexts (e.g., maps) and the "multi-modality" of trajectories, leading to increasingly complex model structures. However, real-world deployments require lightweight models that can quickly migrate and adapt to new environments. Additionally, the core motivations of road agents, referred to as their intentions, deserves further exploration. In this study, we advocate that understanding and reasoning road agents' intention plays a key role in trajectory prediction tasks, and the main challenge is that the concept of intention is fuzzy and abstract. To this end, we present INTENT, an efficient intention-guided trajectory prediction model that relies solely on information contained in the road agent's trajectory. Our model distinguishes itself from existing models in several key aspects: (i) We explicitly model road agents' intentions through contrastive clustering, accommodating the fuzziness and abstraction of human intention in their trajectories. (ii) The proposed INTENT is based solely on multi-layer perceptrons (MLPs), resulting in reduced training and inference time, making it very efficient and more suitable for real-world deployment. (iii) By leveraging estimated intentions and an innovative algorithm for transforming trajectory observations, we obtain more robust trajectory representations that lead to superior prediction accuracy. Extensive experiments on real-world trajectory datasets for pedestrians and autonomous vehicles demonstrate the effectiveness and efficiency of INTENT.
The Rise of Darkness: Safety-Utility Trade-Offs in Role-Playing Dialogue Agents
Feb 28, 2025Large Language Models (LLMs) have made remarkable advances in role-playing dialogue agents, demonstrating their utility in character simulations. However, it remains challenging for these agents to balance character portrayal utility with content safety because this essential character simulation often comes with the risk of generating unsafe content. To address this issue, we first conduct a systematic exploration of the safety-utility trade-off across multiple LLMs. Our analysis reveals that risk scenarios created by villain characters and user queries (referred to as risk coupling) contribute to this trade-off. Building on this, we propose a novel Adaptive Dynamic Multi-Preference (ADMP) method, which dynamically adjusts safety-utility preferences based on the degree of risk coupling and guides the model to generate responses biased toward utility or safety. We further introduce Coupling Margin Sampling (CMS) into coupling detection to enhance the model's ability to handle high-risk scenarios. Experimental results demonstrate that our approach improves safety metrics while maintaining utility.
The Power of Personality: A Human Simulation Perspective to Investigate Large Language Model Agents
Feb 28, 2025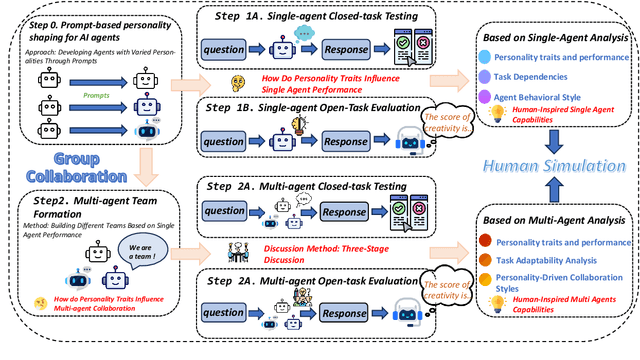
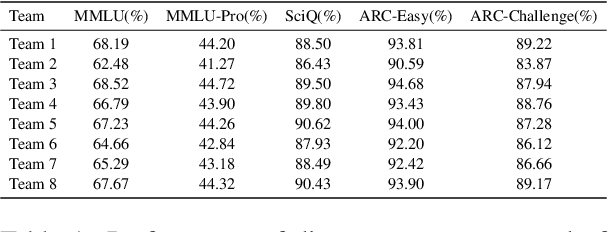
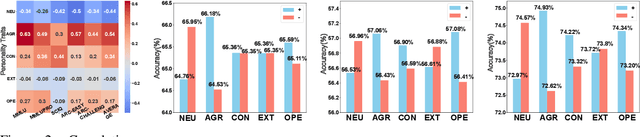

Large language models (LLMs) excel in both closed tasks (including problem-solving, and code generation) and open tasks (including creative writing), yet existing explanations for their capabilities lack connections to real-world human intelligence. To fill this gap, this paper systematically investigates LLM intelligence through the lens of ``human simulation'', addressing three core questions: (1) How do personality traits affect problem-solving in closed tasks? (2) How do traits shape creativity in open tasks? (3) How does single-agent performance influence multi-agent collaboration? By assigning Big Five personality traits to LLM agents and evaluating their performance in single- and multi-agent settings, we reveal that specific traits significantly influence reasoning accuracy (closed tasks) and creative output (open tasks). Furthermore, multi-agent systems exhibit collective intelligence distinct from individual capabilities, driven by distinguishing combinations of personalities. We demonstrate that LLMs inherently simulate human behavior through next-token prediction, mirroring human language, decision-making, and collaborative dynamics.
Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Composite Spatial Reasoning
Oct 21, 2024Vision language models (VLMs) have demonstrated impressive performance across a wide range of downstream tasks. However, their proficiency in spatial reasoning remains limited, despite its crucial role in tasks involving navigation and interaction with physical environments. Specifically, much of the spatial reasoning in these tasks occurs in two-dimensional (2D) environments, and our evaluation reveals that state-of-the-art VLMs frequently generate implausible and incorrect responses to composite spatial reasoning problems, including simple pathfinding tasks that humans can solve effortlessly at a glance. To address this, we explore an effective approach to enhance 2D spatial reasoning within VLMs by training the model on basic spatial capabilities. We begin by disentangling the key components of 2D spatial reasoning: direction comprehension, distance estimation, and localization. Our central hypothesis is that mastering these basic spatial capabilities can significantly enhance a model's performance on composite spatial tasks requiring advanced spatial understanding and combinatorial problem-solving. To investigate this hypothesis, we introduce Sparkle, a framework that fine-tunes VLMs on these three basic spatial capabilities by synthetic data generation and targeted supervision to form an instruction dataset for each capability. Our experiments demonstrate that VLMs fine-tuned with Sparkle achieve significant performance gains, not only in the basic tasks themselves but also in generalizing to composite and out-of-distribution spatial reasoning tasks (e.g., improving from 13.5% to 40.0% on the shortest path problem). These findings underscore the effectiveness of mastering basic spatial capabilities in enhancing composite spatial problem-solving, offering insights for improving VLMs' spatial reasoning capabilities.