 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Token-Level Policy Gradients for Complex Reasoning with Large Language Models
Feb 16, 2026Existing policy-gradient methods for auto-regressive language models typically select subsequent tokens one at a time as actions in the policy. While effective for many generation tasks, such an approach may not fully capture the structure of complex reasoning tasks, where a single semantic decision is often realized across multiple tokens--for example, when defining variables or composing equations. This introduces a potential mismatch between token-level optimization and the inherently block-level nature of reasoning in these settings. To bridge this gap, we propose Multi-token Policy Gradient Optimization (MPO), a framework that treats sequences of K consecutive tokens as unified semantic actions. This block-level perspective enables our method to capture the compositional structure of reasoning trajectories and supports optimization over coherent, higher-level objectives. Experiments on mathematical reasoning and coding benchmarks show that MPO outperforms standard token-level policy gradient baselines, highlight the limitations of token-level policy gradients for complex reasoning, motivating future research to look beyond token-level granularity for reasoning-intensive language tasks.
The Rise of Darkness: Safety-Utility Trade-Offs in Role-Playing Dialogue Agents
Feb 28, 2025Large Language Models (LLMs) have made remarkable advances in role-playing dialogue agents, demonstrating their utility in character simulations. However, it remains challenging for these agents to balance character portrayal utility with content safety because this essential character simulation often comes with the risk of generating unsafe content. To address this issue, we first conduct a systematic exploration of the safety-utility trade-off across multiple LLMs. Our analysis reveals that risk scenarios created by villain characters and user queries (referred to as risk coupling) contribute to this trade-off. Building on this, we propose a novel Adaptive Dynamic Multi-Preference (ADMP) method, which dynamically adjusts safety-utility preferences based on the degree of risk coupling and guides the model to generate responses biased toward utility or safety. We further introduce Coupling Margin Sampling (CMS) into coupling detection to enhance the model's ability to handle high-risk scenarios. Experimental results demonstrate that our approach improves safety metrics while maintaining utility.
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
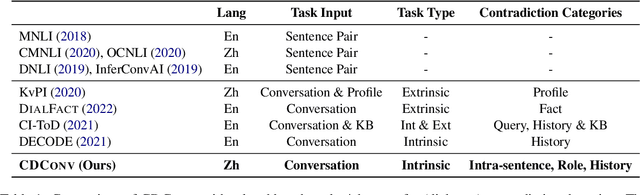

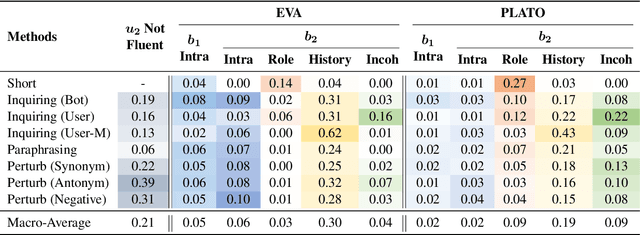
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.
SINC: Service Information Augmented Open-Domain Conversation
Jun 28, 2022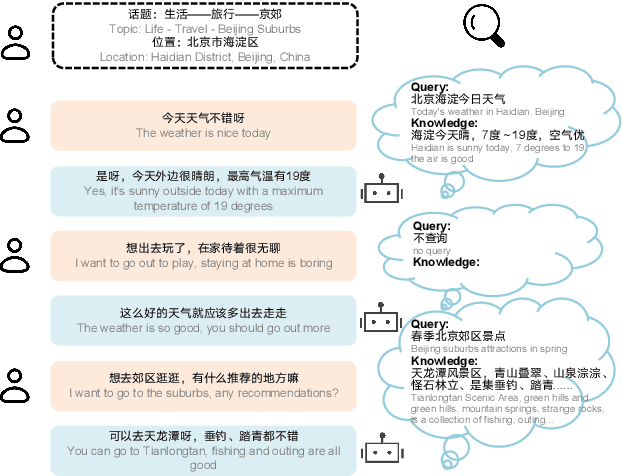
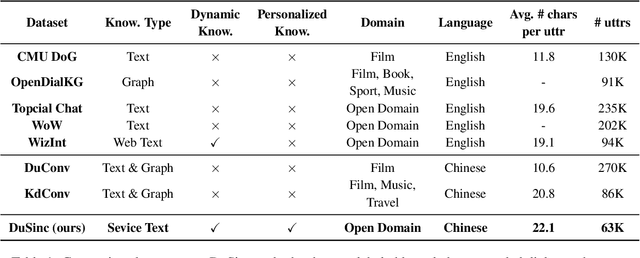
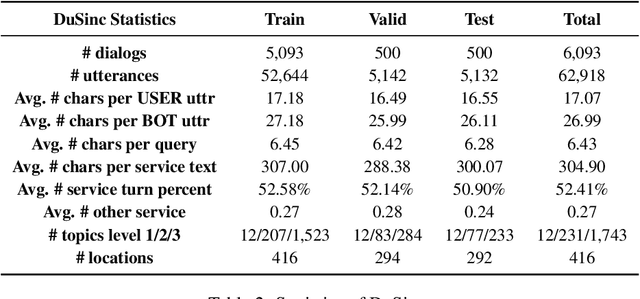
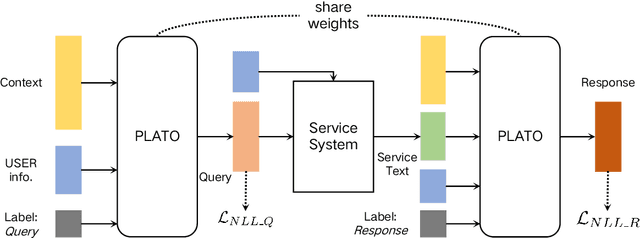
Generative open-domain dialogue systems can benefit from external knowledge, but the lack of external knowledge resources and the difficulty in finding relevant knowledge limit the development of this technology. To this end, we propose a knowledge-driven dialogue task using dynamic service information. Specifically, we use a large number of service APIs that can provide high coverage and spatiotemporal sensitivity as external knowledge sources. The dialogue system generates queries to request external services along with user information, get the relevant knowledge, and generate responses based on this knowledge. To implement this method, we collect and release the first open domain Chinese service knowledge dialogue dataset DuSinc. At the same time, we construct a baseline model PLATO-SINC, which realizes the automatic utilization of service information for dialogue. Both automatic evaluation and human evaluation show that our proposed new method can significantly improve the effect of open-domain conversation, and the session-level overall score in human evaluation is improved by 59.29% compared with the dialogue pre-training model PLATO-2. The dataset and benchmark model will be open sourced.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021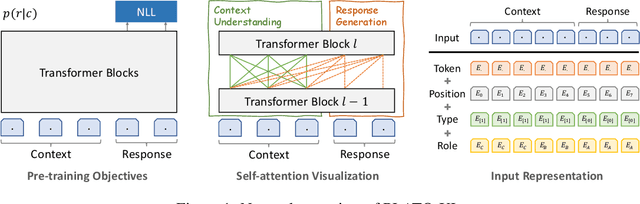
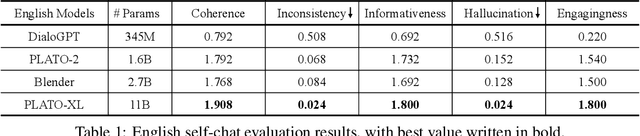

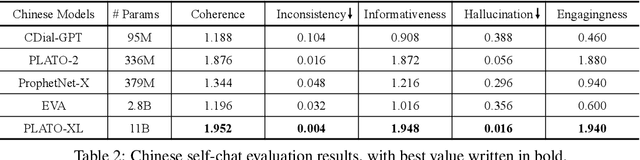
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.
Learning to Select External Knowledge with Multi-Scale Negative Sampling
Feb 03, 2021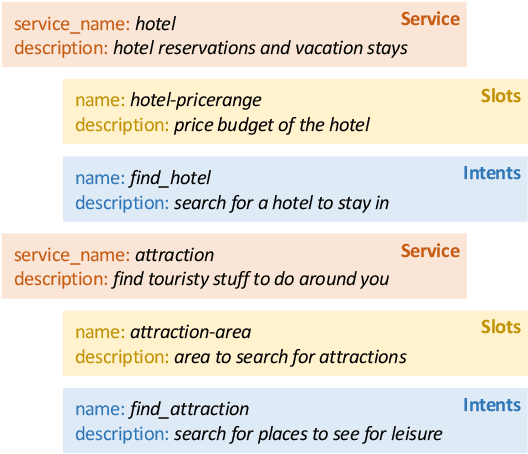
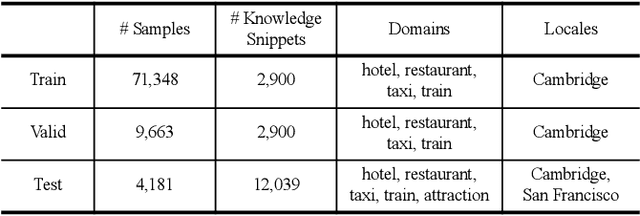
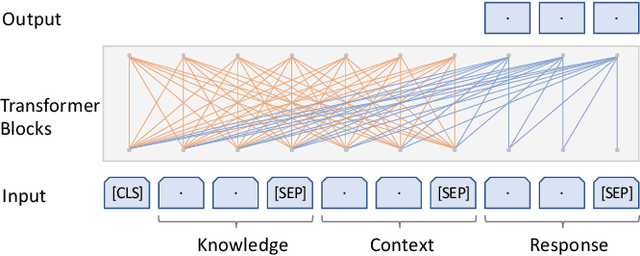
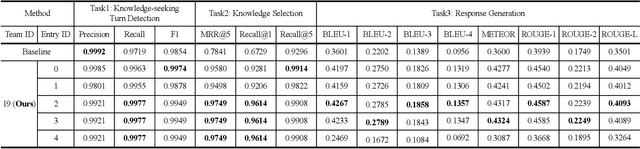
The Track-1 of DSTC9 aims to effectively answer user requests or questions during task-oriented dialogues, which are out of the scope of APIs/DB. By leveraging external knowledge resources, relevant information can be retrieved and encoded into the response generation for these out-of-API-coverage queries. In this work, we have explored several advanced techniques to enhance the utilization of external knowledge and boost the quality of response generation, including schema guided knowledge decision, negatives enhanced knowledge selection, and knowledge grounded response generation. To evaluate the performance of our proposed method, comprehensive experiments have been carried out on the publicly available dataset. Our approach was ranked as the best in human evaluation of DSTC9 Track-1.