 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Socially via Cognitive Reasoning
Sep 26, 2025LLMs trained for logical reasoning excel at step-by-step deduction to reach verifiable answers. However, this paradigm is ill-suited for navigating social situations, which induce an interpretive process of analyzing ambiguous cues that rarely yield a definitive outcome. To bridge this gap, we introduce Cognitive Reasoning, a paradigm modeled on human social cognition. It formulates the interpretive process into a structured cognitive flow of interconnected cognitive units (e.g., observation or attribution), which combine adaptively to enable effective social thinking and responses. We then propose CogFlow, a complete framework that instills this capability in LLMs. CogFlow first curates a dataset of cognitive flows by simulating the associative and progressive nature of human thought via tree-structured planning. After instilling the basic cognitive reasoning capability via supervised fine-tuning, CogFlow adopts reinforcement learning to enable the model to improve itself via trial and error, guided by a multi-objective reward that optimizes both cognitive flow and response quality. Extensive experiments show that CogFlow effectively enhances the social cognitive capabilities of LLMs, and even humans, leading to more effective social decision-making.
Beyond Nash Equilibrium: Bounded Rationality of LLMs and humans in Strategic Decision-making
Jun 11, 2025Large language models are increasingly used in strategic decision-making settings, yet evidence shows that, like humans, they often deviate from full rationality. In this study, we compare LLMs and humans using experimental paradigms directly adapted from behavioral game-theory research. We focus on two well-studied strategic games, Rock-Paper-Scissors and the Prisoner's Dilemma, which are well known for revealing systematic departures from rational play in human subjects. By placing LLMs in identical experimental conditions, we evaluate whether their behaviors exhibit the bounded rationality characteristic of humans. Our findings show that LLMs reproduce familiar human heuristics, such as outcome-based strategy switching and increased cooperation when future interaction is possible, but they apply these rules more rigidly and demonstrate weaker sensitivity to the dynamic changes in the game environment. Model-level analyses reveal distinctive architectural signatures in strategic behavior, and even reasoning models sometimes struggle to find effective strategies in adaptive situations. These results indicate that current LLMs capture only a partial form of human-like bounded rationality and highlight the need for training methods that encourage flexible opponent modeling and stronger context awareness.
Crisp: Cognitive Restructuring of Negative Thoughts through Multi-turn Supportive Dialogues
Apr 24, 2025Cognitive Restructuring (CR) is a psychotherapeutic process aimed at identifying and restructuring an individual's negative thoughts, arising from mental health challenges, into more helpful and positive ones via multi-turn dialogues. Clinician shortage and stigma urge the development of human-LLM interactive psychotherapy for CR. Yet, existing efforts implement CR via simple text rewriting, fixed-pattern dialogues, or a one-shot CR workflow, failing to align with the psychotherapeutic process for effective CR. To address this gap, we propose CRDial, a novel framework for CR, which creates multi-turn dialogues with specifically designed identification and restructuring stages of negative thoughts, integrates sentence-level supportive conversation strategies, and adopts a multi-channel loop mechanism to enable iterative CR. With CRDial, we distill Crisp, a large-scale and high-quality bilingual dialogue dataset, from LLM. We then train Crispers, Crisp-based conversational LLMs for CR, at 7B and 14B scales. Extensive human studies show the superiority of Crispers in pointwise, pairwise, and intervention evaluations.
HPSS: Heuristic Prompting Strategy Search for LLM Evaluators
Feb 18, 2025
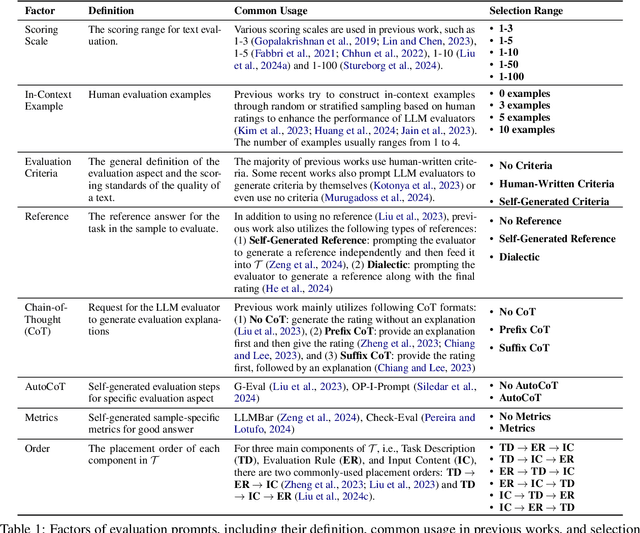
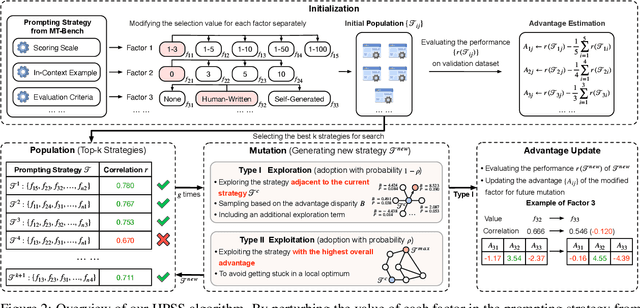
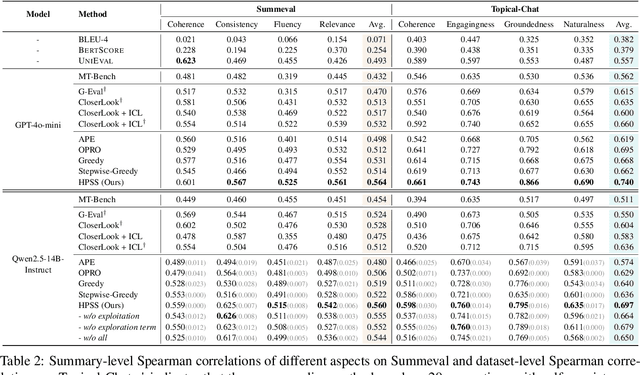
Since the adoption of large language models (LLMs) for text evaluation has become increasingly prevalent in the field of natural language processing (NLP), a series of existing works attempt to optimize the prompts for LLM evaluators to improve their alignment with human judgment. However, their efforts are limited to optimizing individual factors of evaluation prompts, such as evaluation criteria or output formats, neglecting the combinatorial impact of multiple factors, which leads to insufficient optimization of the evaluation pipeline. Nevertheless, identifying well-behaved prompting strategies for adjusting multiple factors requires extensive enumeration. To this end, we comprehensively integrate 8 key factors for evaluation prompts and propose a novel automatic prompting strategy optimization method called Heuristic Prompting Strategy Search (HPSS). Inspired by the genetic algorithm, HPSS conducts an iterative search to find well-behaved prompting strategies for LLM evaluators. A heuristic function is employed to guide the search process, enhancing the performance of our algorithm. Extensive experiments across four evaluation tasks demonstrate the effectiveness of HPSS, consistently outperforming both human-designed evaluation prompts and existing automatic prompt optimization methods.
CharacterBench: Benchmarking Character Customization of Large Language Models
Dec 16, 2024



Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at https://github.com/thu-coai/CharacterBench.
Benchmarking Complex Instruction-Following with Multiple Constraints Composition
Jul 04, 2024



Instruction following is one of the fundamental capabilities of large language models (LLMs). As the ability of LLMs is constantly improving, they have been increasingly applied to deal with complex human instructions in real-world scenarios. Therefore, how to evaluate the ability of complex instruction-following of LLMs has become a critical research problem. Existing benchmarks mainly focus on modeling different types of constraints in human instructions while neglecting the composition of different constraints, which is an indispensable constituent in complex instructions. To this end, we propose ComplexBench, a benchmark for comprehensively evaluating the ability of LLMs to follow complex instructions composed of multiple constraints. We propose a hierarchical taxonomy for complex instructions, including 4 constraint types, 19 constraint dimensions, and 4 composition types, and manually collect a high-quality dataset accordingly. To make the evaluation reliable, we augment LLM-based evaluators with rules to effectively verify whether generated texts can satisfy each constraint and composition. Furthermore, we obtain the final evaluation score based on the dependency structure determined by different composition types. ComplexBench identifies significant deficiencies in existing LLMs when dealing with complex instructions with multiple constraints composition.
ToMBench: Benchmarking Theory of Mind in Large Language Models
Feb 23, 2024



Theory of Mind (ToM) is the cognitive capability to perceive and ascribe mental states to oneself and others. Recent research has sparked a debate over whether large language models (LLMs) exhibit a form of ToM. However, existing ToM evaluations are hindered by challenges such as constrained scope, subjective judgment, and unintended contamination, yielding inadequate assessments. To address this gap, we introduce ToMBench with three key characteristics: a systematic evaluation framework encompassing 8 tasks and 31 abilities in social cognition, a multiple-choice question format to support automated and unbiased evaluation, and a build-from-scratch bilingual inventory to strictly avoid data leakage. Based on ToMBench, we conduct extensive experiments to evaluate the ToM performance of 10 popular LLMs across tasks and abilities. We find that even the most advanced LLMs like GPT-4 lag behind human performance by over 10% points, indicating that LLMs have not achieved a human-level theory of mind yet. Our aim with ToMBench is to enable an efficient and effective evaluation of LLMs' ToM capabilities, thereby facilitating the development of LLMs with inherent social intelligence.
EmoBench: Evaluating the Emotional Intelligence of Large Language Models
Feb 19, 2024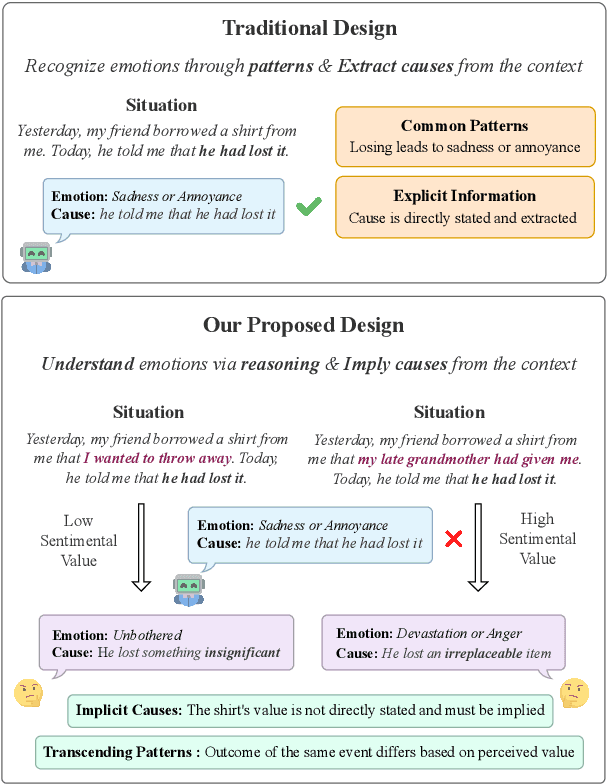



Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion regulation and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data will be publicly available from https://github.com/Sahandfer/EmoBench.
CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
Nov 28, 2023



In this paper, we present CharacterGLM, a series of models built upon ChatGLM, with model sizes ranging from 6B to 66B parameters. Our CharacterGLM is designed for generating Character-based Dialogues (CharacterDial), which aims to equip a conversational AI system with character customization for satisfying people's inherent social desires and emotional needs. On top of CharacterGLM, we can customize various AI characters or social agents by configuring their attributes (identities, interests, viewpoints, experiences, achievements, social relationships, etc.) and behaviors (linguistic features, emotional expressions, interaction patterns, etc.). Our model outperforms most mainstream close-source large langauge models, including the GPT series, especially in terms of consistency, human-likeness, and engagement according to manual evaluations. We will release our 6B version of CharacterGLM and a subset of training data to facilitate further research development in the direction of character-based dialogue generation.
Facilitating Multi-turn Emotional Support Conversation with Positive Emotion Elicitation: A Reinforcement Learning Approach
Jul 16, 2023



Emotional support conversation (ESC) aims to provide emotional support (ES) to improve one's mental state. Existing works stay at fitting grounded responses and responding strategies (e.g., question), which ignore the effect on ES and lack explicit goals to guide emotional positive transition. To this end, we introduce a new paradigm to formalize multi-turn ESC as a process of positive emotion elicitation. Addressing this task requires finely adjusting the elicitation intensity in ES as the conversation progresses while maintaining conversational goals like coherence. In this paper, we propose Supporter, a mixture-of-expert-based reinforcement learning model, and well design ES and dialogue coherence rewards to guide policy's learning for responding. Experiments verify the superiority of Supporter in achieving positive emotion elicitation during responding while maintaining conversational goals including coherence.