 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Near-Field Integrated Imaging and Communication in Distributed MIMO Networks
Aug 24, 2025In this work, we propose a general framework for wireless imaging in distributed MIMO wideband communication systems, considering multi-view non-isotropic targets and near-field propagation effects. For indoor scenarios where the objective is to image small-scale objects with high resolution, we propose a range migration algorithm (RMA)-based scheme using three kinds of array architectures: the full array, boundary array, and distributed boundary array. With non-isotropic near-field channels, we establish the Fourier transformation (FT)-based relationship between the imaging reflectivity and the distributed spatial-domain signals and discuss the corresponding theoretical properties. Next, for outdoor scenarios where the objective is to reconstruct the large-scale three-dimensional (3D) environment with coarse resolution, we propose a sparse Bayesian learning (SBL)-based algorithm to solve the multiple measurement vector (MMV) problem, which further addresses the non-isotropic reflectivity across different subcarriers. Numerical results demonstrate the effectiveness of the proposed algorithms in acquiring high-resolution small objects and accurately reconstructing large-scale environments.
Multi-dimensional Parameter Estimation in RIS-aided MU-MIMO Channels
May 05, 2025We address the channel estimation problem in reconfigurable intelligent surface (RIS) aided broadband systems by proposing a dual-structure and multi-dimensional transformations (DS-MDT) algorithm. The proposed approach leverages the dual-structure features of the channel parameters to assist users experiencing weaker channel conditions, thereby enhancing estimation performance. Moreover, given that the channel parameters are distributed across multiple dimensions of the received tensor, the proposed algorithm employs multi-dimensional transformations to effectively isolate and extract distinct parameters. The numerical results demonstrate the proposed algorithm reduces the normalized mean square error (NMSE) by up to 10 dB while maintaining lower complexity compared to state-of-the-art methods.
Holographic MIMO Multi-Cell Communications
Feb 23, 2025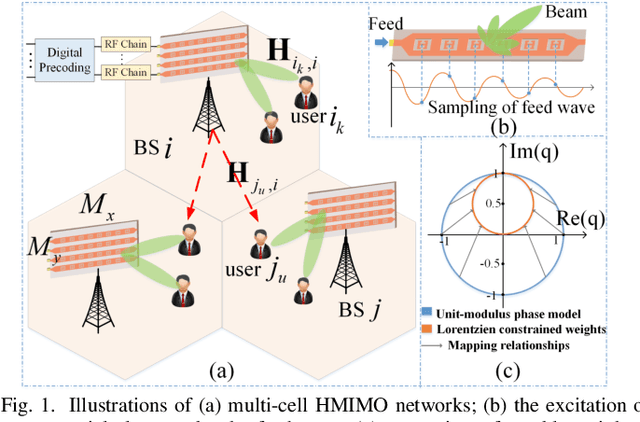
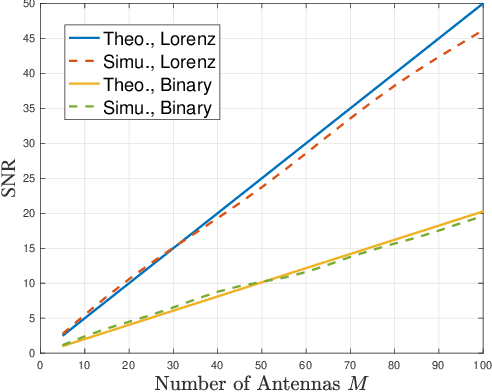
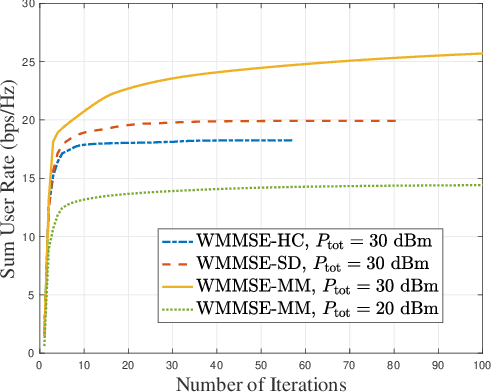
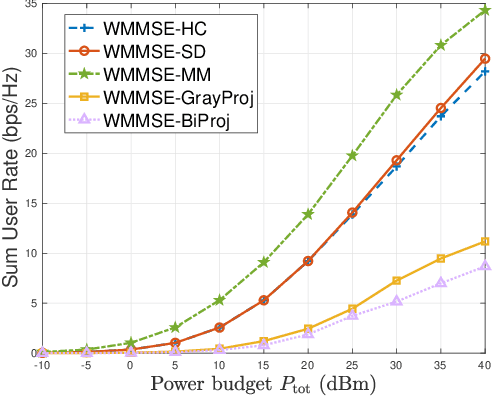
Metamaterial antennas are appealing for next-generation wireless networks due to their simplified hardware and much-reduced size, power, and cost. This paper investigates the holographic multiple-input multiple-output (HMIMO)-aided multi-cell systems with practical per-radio frequency (RF) chain power constraints. With multiple antennas at both base stations (BSs) and users, we design the baseband digital precoder and the tuning response of HMIMO metamaterial elements to maximize the weighted sum user rate. Specifically, under the framework of block coordinate descent (BCD) and weighted minimum mean square error (WMMSE) techniques, we derive the low-complexity closed-form solution for baseband precoder without requiring bisection search and matrix inversion. Then, for the design of HMIMO metamaterial elements under binary tuning constraints, we first propose a low-complexity suboptimal algorithm with closed-form solutions by exploiting the hidden convexity (HC) in the quadratic problem and then further propose an accelerated sphere decoding (SD)-based algorithm which yields global optimal solution in the iteration. For HMIMO metamaterial element design under the Lorentzian-constrained phase model, we propose a maximization-minorization (MM) algorithm with closed-form solutions at each iteration step. Furthermore, in a simplified multiple-input single-output (MISO) scenario, we derive the scaling law of downlink single-to-noise (SNR) for HMIMO with binary and Lorentzian tuning constraints and theoretically compare it with conventional fully digital/hybrid arrays. Simulation results demonstrate the effectiveness of our algorithms compared to benchmarks and the benefits of HMIMO compared to conventional arrays.
Cooperative Multistatic Target Detection in Cell-Free Communication Networks
Oct 21, 2024


In this work, we consider the target detection problem in a multistatic integrated sensing and communication (ISAC) scenario characterized by the cell-free MIMO communication network deployment, where multiple radio units (RUs) in the network cooperate with each other for the sensing task. By exploiting the angle resolution from multiple arrays deployed in the network and the delay resolution from the communication signals, i.e., orthogonal frequency division multiplexing (OFDM) signals, we formulate a cooperative sensing problem with coherent data fusion of multiple RUs' observations and propose a sparse Bayesian learning (SBL)-based method, where the global coordinates of target locations are directly detected. Intensive numerical results indicate promising target detection performance of the proposed SBL-based method. Additionally, a theoretical analysis of the considered cooperative multistatic sensing task is provided using the pairwise error probability (PEP) analysis, which can be used to provide design insights, e.g., illumination and beam patterns, for the considered problem.
Iterative Equalization of CPM With Unitary Approximate Message Passing
Aug 14, 2024



Continuous phase modulation (CPM) has extensive applications in wireless communications due to its high spectral and power efficiency. However, its nonlinear characteristics pose significant challenges for detection in frequency selective fading channels. This paper proposes an iterative receiver tailored for the detection of CPM signals over frequency selective fading channels. This design leverages the factor graph framework to integrate equalization, demodulation, and decoding functions. The equalizer employs the unitary approximate message passing (UAMP) algorithm, while the unitary transformation is implemented using the fast Fourier transform (FFT) with the aid of a cyclic prefix (CP), thereby achieving low computational complexity while with high performance. For CPM demodulation and channel decoding, with belief propagation (BP), we design a message passing-based maximum a posteriori (MAP) algorithm, and the message exchange between the demodulator, decoder and equalizer is elaborated. With proper message passing schedules, the receiver can achieve fast convergence. Simulation results show that compared with existing turbo receivers, the proposed receiver delivers significant performance enhancement with low computational complexity.
Compressed Sensing Inspired User Acquisition for Downlink Integrated Sensing and Communication Transmissions
Jul 01, 2024This paper investigates radar-assisted user acquisition for downlink multi-user multiple-input multiple-output (MIMO) transmission using Orthogonal Frequency Division Multiplexing (OFDM) signals. Specifically, we formulate a concise mathematical model for the user acquisition problem, where each user is characterized by its delay and beamspace response. Therefore, we propose a two-stage method for user acquisition, where the Multiple Signal Classification (MUSIC) algorithm is adopted for delay estimation, and then a least absolute shrinkage and selection operator (LASSO) is applied for estimating the user response in the beamspace. Furthermore, we also provide a comprehensive performance analysis of the considered problem based on the pair-wise error probability (PEP). Particularly, we show that the rank and the geometric mean of non-zero eigenvalues of the squared beamspace difference matrix determines the user acquisition performance. More importantly, we reveal that simultaneously probing multiple beams outperforms concentrating power on a specific beam direction in each time slot under the power constraint, when only limited OFDM symbols are transmitted. Our numerical results confirm our conclusions and also demonstrate a promising acquisition performance of the proposed two-stage method.
Hybrid Message Passing-Based Detectors for Uplink Grant-Free NOMA Systems
Jan 26, 2024This paper studies improving the detector performance which considers the activity state (AS) temporal correlation of the user equipments (UEs) in the time domain under the uplink grant-free non-orthogonal multiple access (GF-NOMA) system. The Bernoulli Gaussian-Markov chain (BG-MC) probability model is used for exploiting both the sparsity and slow change characteristic of the AS of the UE. The GAMP Bernoulli Gaussian-Markov chain (GAMP-BG-MC) algorithm is proposed to improve the detector performance, which can utilize the bidirectional message passing between the neighboring time slots to fully exploit the temporally-correlated AS of the UE. Furthermore, the parameters of the BG-MC model can be updated adaptively during the estimation procedure with unknown system statistics. Simulation results show that the proposed algorithm can improve the detection accuracy compared with the existing methods while keeping the same order complexity.
CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
Nov 28, 2023



In this paper, we present CharacterGLM, a series of models built upon ChatGLM, with model sizes ranging from 6B to 66B parameters. Our CharacterGLM is designed for generating Character-based Dialogues (CharacterDial), which aims to equip a conversational AI system with character customization for satisfying people's inherent social desires and emotional needs. On top of CharacterGLM, we can customize various AI characters or social agents by configuring their attributes (identities, interests, viewpoints, experiences, achievements, social relationships, etc.) and behaviors (linguistic features, emotional expressions, interaction patterns, etc.). Our model outperforms most mainstream close-source large langauge models, including the GPT series, especially in terms of consistency, human-likeness, and engagement according to manual evaluations. We will release our 6B version of CharacterGLM and a subset of training data to facilitate further research development in the direction of character-based dialogue generation.
EMF Exposure Mitigation in RIS-Assisted Multi-Beam Communications
May 11, 2023This paper proposes a method for reducing {third-party} exposure to electromagnetic fields (EMF) by exploiting the capability of a reconfigurable intelligent surfaces' (RIS) to manipulate the electromagnetic environment. We consider users capable of multi-beam communication, such that a user can use a set of different propagation paths enabled by the RIS. The optimization objective is to find propagation alternatives that allow to maintain the target quality of service while minimizing the level of EMF at surrounding non-intended users (NUEs). We provide an evolutionary heuristic solution based on Genetic Algorithm (GA) for power equalization and multi-beam selection of a codebook at the Base Station. Our results show valuable insights into how RIS-assisted multi-beam communications can mitigate EMF exposure with minimal degradation of the spectral efficiency.