 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELOAD: A Robust and Efficient Learned Query Optimizer for Database Systems
Apr 16, 2026Recent advances in query optimization have shifted from traditional rule-based and cost-based techniques towards machine learning-driven approaches. Among these, reinforcement learning (RL) has attracted significant attention due to its ability to optimize long-term performance by learning policies over query planning. However, existing RL-based query optimizers often exhibit unstable performance at the level of individual queries, including severe performance regressions, and require prolonged training to reach the plan quality of expert, cost-based optimizers. These shortcomings make learned query optimizers difficult to deploy in practice and remain a major barrier to their adoption in production database systems. To address these challenges, we present RELOAD, a robust and efficient learned query optimizer for database systems. RELOAD focuses on (i) robustness, by minimizing query-level performance regressions and ensuring consistent optimization behavior across executions, and (ii) efficiency, by accelerating convergence to expert-level plan quality. Through extensive experiments on standard benchmarks, including Join Order Benchmark, TPC-DS, and Star Schema Benchmark, RELOAD demonstrates up to 2.4x higher robustness and 3.1x greater efficiency compared to state-of-the-art RL-based query optimization techniques.
Optimizing open-domain question answering with graph-based retrieval augmented generation
Mar 04, 2025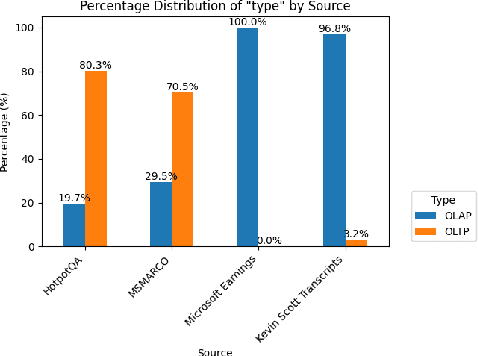
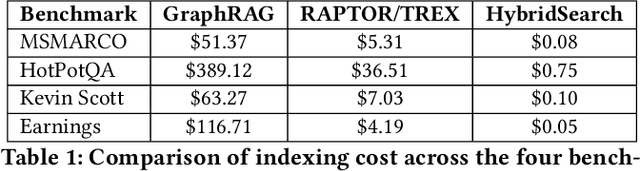
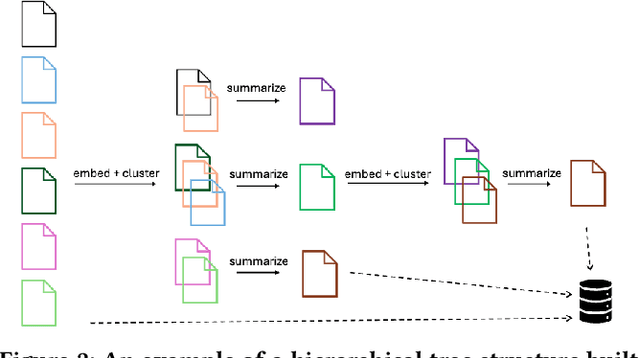
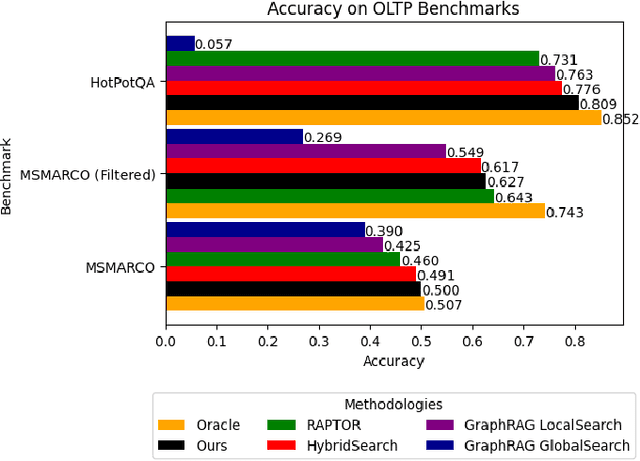
In this work, we benchmark various graph-based retrieval-augmented generation (RAG) systems across a broad spectrum of query types, including OLTP-style (fact-based) and OLAP-style (thematic) queries, to address the complex demands of open-domain question answering (QA). Traditional RAG methods often fall short in handling nuanced, multi-document synthesis tasks. By structuring knowledge as graphs, we can facilitate the retrieval of context that captures greater semantic depth and enhances language model operations. We explore graph-based RAG methodologies and introduce TREX, a novel, cost-effective alternative that combines graph-based and vector-based retrieval techniques. Our benchmarking across four diverse datasets highlights the strengths of different RAG methodologies, demonstrates TREX's ability to handle multiple open-domain QA types, and reveals the limitations of current evaluation methods. In a real-world technical support case study, we demonstrate how TREX solutions can surpass conventional vector-based RAG in efficiently synthesizing data from heterogeneous sources. Our findings underscore the potential of augmenting large language models with advanced retrieval and orchestration capabilities, advancing scalable, graph-based AI solutions.
DECO: Life-Cycle Management of Enterprise-Grade Chatbots
Dec 08, 2024



Software engineers frequently grapple with the challenge of accessing disparate documentation and telemetry data, including Troubleshooting Guides (TSGs), incident reports, code repositories, and various internal tools developed by multiple stakeholders. While on-call duties are inevitable, incident resolution becomes even more daunting due to the obscurity of legacy sources and the pressures of strict time constraints. To enhance the efficiency of on-call engineers (OCEs) and streamline their daily workflows, we introduced DECO -- a comprehensive framework for developing, deploying, and managing enterprise-grade chatbots tailored to improve productivity in engineering routines. This paper details the design and implementation of the DECO framework, emphasizing its innovative NL2SearchQuery functionality and a hierarchical planner. These features support efficient and customized retrieval-augmented-generation (RAG) algorithms that not only extract relevant information from diverse sources but also select the most pertinent toolkits in response to user queries. This enables the addressing of complex technical questions and provides seamless, automated access to internal resources. Additionally, DECO incorporates a robust mechanism for converting unstructured incident logs into user-friendly, structured guides, effectively bridging the documentation gap. Feedback from users underscores DECO's pivotal role in simplifying complex engineering tasks, accelerating incident resolution, and bolstering organizational productivity. Since its launch in September 2023, DECO has demonstrated its effectiveness through extensive engagement, with tens of thousands of interactions from hundreds of active users across multiple organizations within the company.
vMFER: Von Mises-Fisher Experience Resampling Based on Uncertainty of Gradient Directions for Policy Improvement
May 14, 2024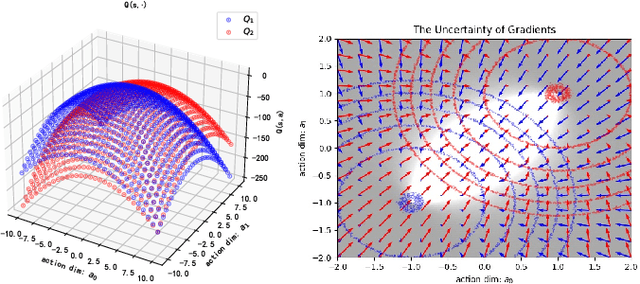

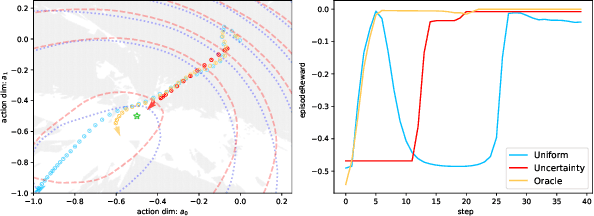
Reinforcement Learning (RL) is a widely employed technique in decision-making problems, encompassing two fundamental operations -- policy evaluation and policy improvement. Enhancing learning efficiency remains a key challenge in RL, with many efforts focused on using ensemble critics to boost policy evaluation efficiency. However, when using multiple critics, the actor in the policy improvement process can obtain different gradients. Previous studies have combined these gradients without considering their disagreements. Therefore, optimizing the policy improvement process is crucial to enhance learning efficiency. This study focuses on investigating the impact of gradient disagreements caused by ensemble critics on policy improvement. We introduce the concept of uncertainty of gradient directions as a means to measure the disagreement among gradients utilized in the policy improvement process. Through measuring the disagreement among gradients, we find that transitions with lower uncertainty of gradient directions are more reliable in the policy improvement process. Building on this analysis, we propose a method called von Mises-Fisher Experience Resampling (vMFER), which optimizes the policy improvement process by resampling transitions and assigning higher confidence to transitions with lower uncertainty of gradient directions. Our experiments demonstrate that vMFER significantly outperforms the benchmark and is particularly well-suited for ensemble structures in RL.
Hybrid Message Passing-Based Detectors for Uplink Grant-Free NOMA Systems
Jan 26, 2024This paper studies improving the detector performance which considers the activity state (AS) temporal correlation of the user equipments (UEs) in the time domain under the uplink grant-free non-orthogonal multiple access (GF-NOMA) system. The Bernoulli Gaussian-Markov chain (BG-MC) probability model is used for exploiting both the sparsity and slow change characteristic of the AS of the UE. The GAMP Bernoulli Gaussian-Markov chain (GAMP-BG-MC) algorithm is proposed to improve the detector performance, which can utilize the bidirectional message passing between the neighboring time slots to fully exploit the temporally-correlated AS of the UE. Furthermore, the parameters of the BG-MC model can be updated adaptively during the estimation procedure with unknown system statistics. Simulation results show that the proposed algorithm can improve the detection accuracy compared with the existing methods while keeping the same order complexity.
Locally temporal-spatial pattern learning with graph attention mechanism for EEG-based emotion recognition
Aug 19, 2022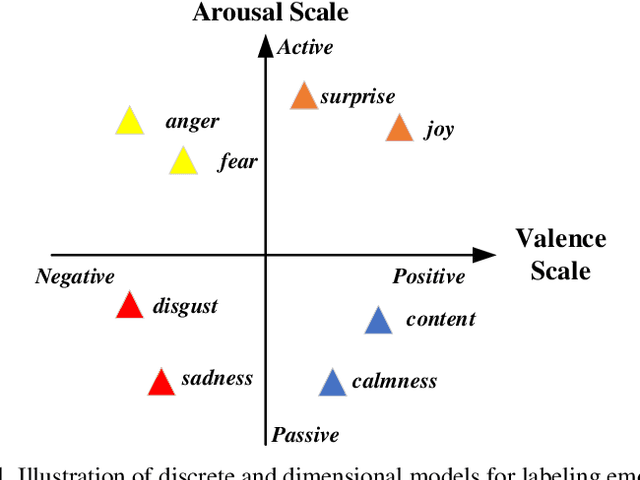

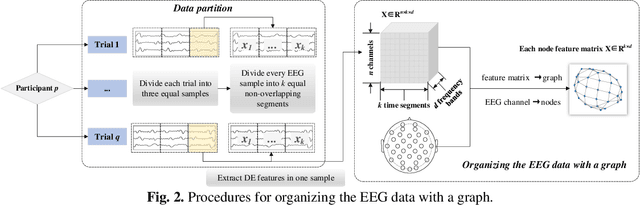
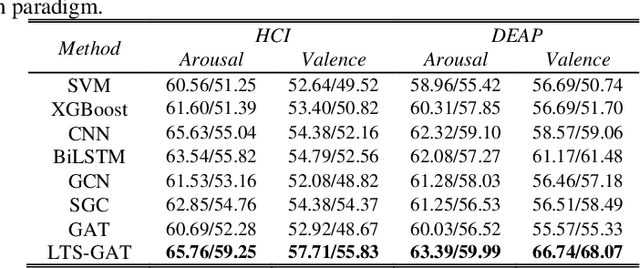
Technique of emotion recognition enables computers to classify human affective states into discrete categories. However, the emotion may fluctuate instead of maintaining a stable state even within a short time interval. There is also a difficulty to take the full use of the EEG spatial distribution due to its 3-D topology structure. To tackle the above issues, we proposed a locally temporal-spatial pattern learning graph attention network (LTS-GAT) in the present study. In the LTS-GAT, a divide-and-conquer scheme was used to examine local information on temporal and spatial dimensions of EEG patterns based on the graph attention mechanism. A dynamical domain discriminator was added to improve the robustness against inter-individual variations of the EEG statistics to learn robust EEG feature representations across different participants. We evaluated the LTS-GAT on two public datasets for affective computing studies under individual-dependent and independent paradigms. The effectiveness of LTS-GAT model was demonstrated when compared to other existing mainstream methods. Moreover, visualization methods were used to illustrate the relations of different brain regions and emotion recognition. Meanwhile, the weights of different time segments were also visualized to investigate emotion sparsity problems.
Homotopy Based Reinforcement Learning with Maximum Entropy for Autonomous Air Combat
Dec 01, 2021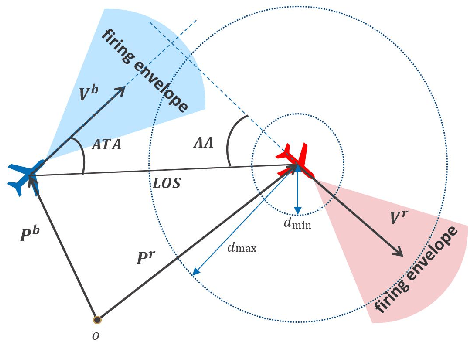
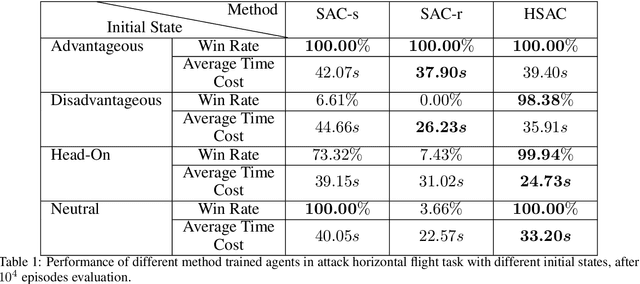
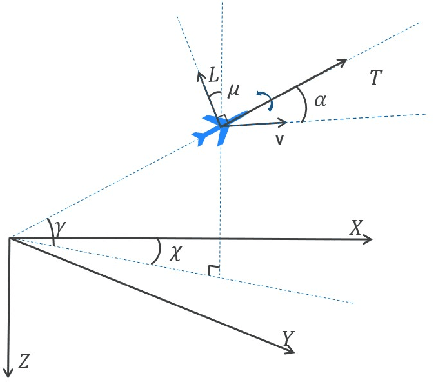

The Intelligent decision of the unmanned combat aerial vehicle (UCAV) has long been a challenging problem. The conventional search method can hardly satisfy the real-time demand during high dynamics air combat scenarios. The reinforcement learning (RL) method can significantly shorten the decision time via using neural networks. However, the sparse reward problem limits its convergence speed and the artificial prior experience reward can easily deviate its optimal convergent direction of the original task, which raises great difficulties for the RL air combat application. In this paper, we propose a homotopy-based soft actor-critic method (HSAC) which focuses on addressing these problems via following the homotopy path between the original task with sparse reward and the auxiliary task with artificial prior experience reward. The convergence and the feasibility of this method are also proved in this paper. To confirm our method feasibly, we construct a detailed 3D air combat simulation environment for the RL-based methods training firstly, and we implement our method in both the attack horizontal flight UCAV task and the self-play confrontation task. Experimental results show that our method performs better than the methods only utilizing the sparse reward or the artificial prior experience reward. The agent trained by our method can reach more than 98.3% win rate in the attack horizontal flight UCAV task and average 67.4% win rate when confronted with the agents trained by the other two methods.
Phoebe: A Learning-based Checkpoint Optimizer
Oct 05, 2021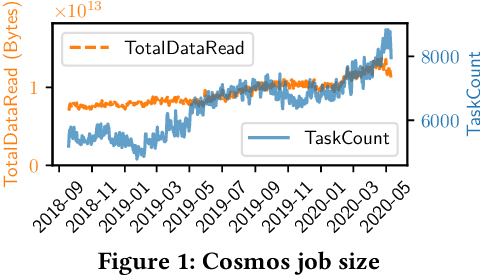
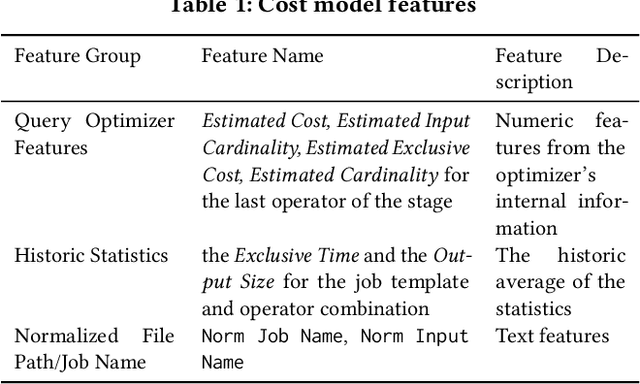
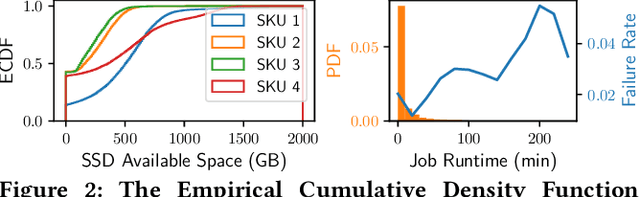
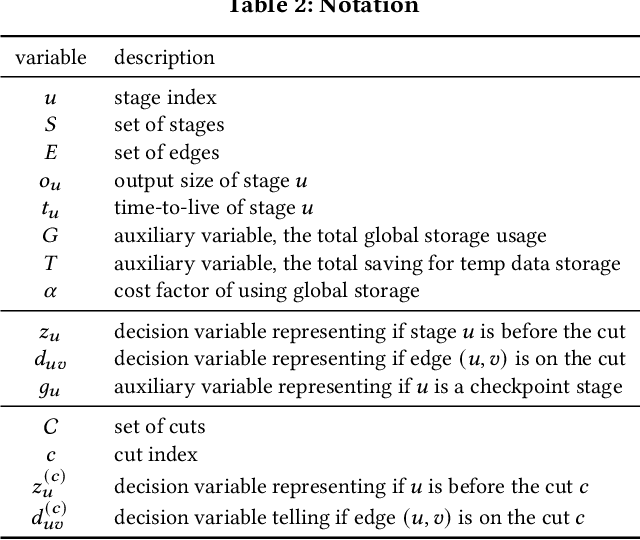
Easy-to-use programming interfaces paired with cloud-scale processing engines have enabled big data system users to author arbitrarily complex analytical jobs over massive volumes of data. However, as the complexity and scale of analytical jobs increase, they encounter a number of unforeseen problems, hotspots with large intermediate data on temporary storage, longer job recovery time after failures, and worse query optimizer estimates being examples of issues that we are facing at Microsoft. To address these issues, we propose Phoebe, an efficient learning-based checkpoint optimizer. Given a set of constraints and an objective function at compile-time, Phoebe is able to determine the decomposition of job plans, and the optimal set of checkpoints to preserve their outputs to durable global storage. Phoebe consists of three machine learning predictors and one optimization module. For each stage of a job, Phoebe makes accurate predictions for: (1) the execution time, (2) the output size, and (3) the start/end time taking into account the inter-stage dependencies. Using these predictions, we formulate checkpoint optimization as an integer programming problem and propose a scalable heuristic algorithm that meets the latency requirement of the production environment. We demonstrate the effectiveness of Phoebe in production workloads, and show that we can free the temporary storage on hotspots by more than 70% and restart failed jobs 68% faster on average with minimum performance impact. Phoebe also illustrates that adding multiple sets of checkpoints is not cost-efficient, which dramatically reduces the complexity of the optimization.
Seagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020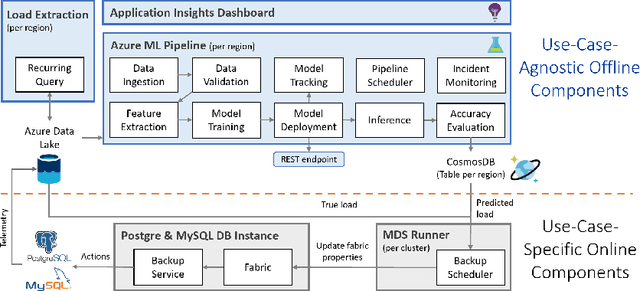
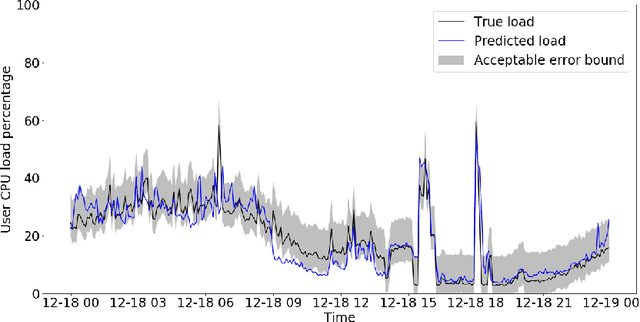
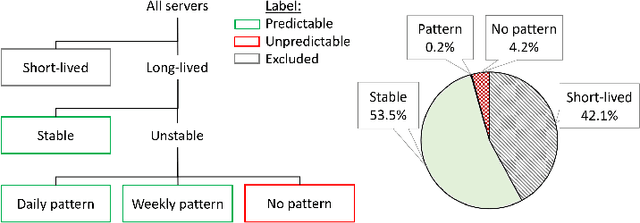
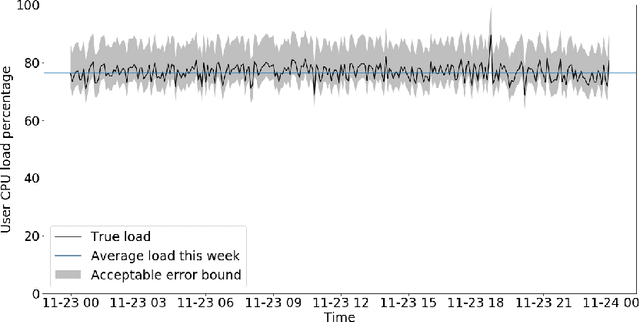
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.
MLOS: An Infrastructure for Automated Software Performance Engineering
Jun 04, 2020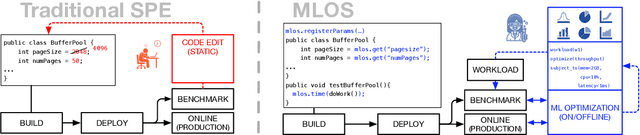
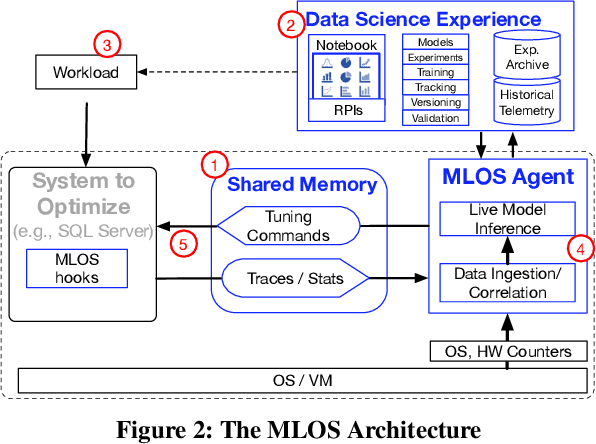
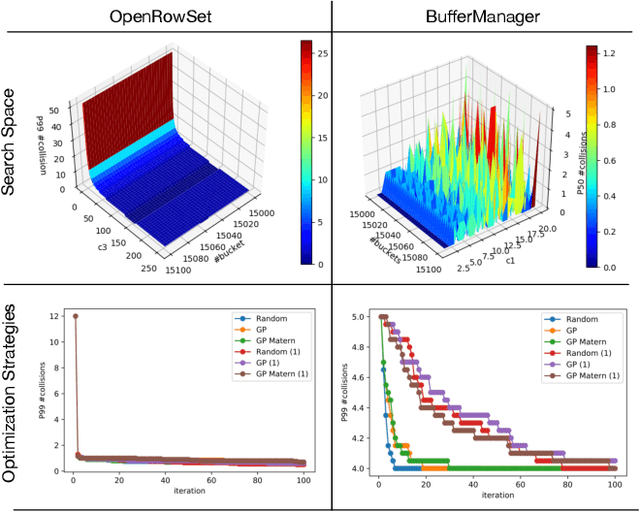
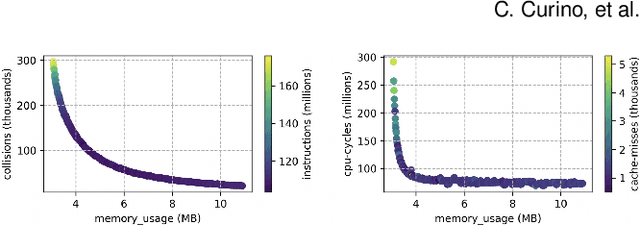
Developing modern systems software is a complex task that combines business logic programming and Software Performance Engineering (SPE). The later is an experimental and labor-intensive activity focused on optimizing the system for a given hardware, software, and workload (hw/sw/wl) context. Today's SPE is performed during build/release phases by specialized teams, and cursed by: 1) lack of standardized and automated tools, 2) significant repeated work as hw/sw/wl context changes, 3) fragility induced by a "one-size-fit-all" tuning (where improvements on one workload or component may impact others). The net result: despite costly investments, system software is often outside its optimal operating point - anecdotally leaving 30% to 40% of performance on the table. The recent developments in Data Science (DS) hints at an opportunity: combining DS tooling and methodologies with a new developer experience to transform the practice of SPE. In this paper we present: MLOS, an ML-powered infrastructure and methodology to democratize and automate Software Performance Engineering. MLOS enables continuous, instance-level, robust, and trackable systems optimization. MLOS is being developed and employed within Microsoft to optimize SQL Server performance. Early results indicated that component-level optimizations can lead to 20%-90% improvements when custom-tuning for a specific hw/sw/wl, hinting at a significant opportunity. However, several research challenges remain that will require community involvement. To this end, we are in the process of open-sourcing the MLOS core infrastructure, and we are engaging with academic institutions to create an educational program around Software 2.0 and MLOS ideas.