 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECO: Life-Cycle Management of Enterprise-Grade Chatbots
Dec 08, 2024



Software engineers frequently grapple with the challenge of accessing disparate documentation and telemetry data, including Troubleshooting Guides (TSGs), incident reports, code repositories, and various internal tools developed by multiple stakeholders. While on-call duties are inevitable, incident resolution becomes even more daunting due to the obscurity of legacy sources and the pressures of strict time constraints. To enhance the efficiency of on-call engineers (OCEs) and streamline their daily workflows, we introduced DECO -- a comprehensive framework for developing, deploying, and managing enterprise-grade chatbots tailored to improve productivity in engineering routines. This paper details the design and implementation of the DECO framework, emphasizing its innovative NL2SearchQuery functionality and a hierarchical planner. These features support efficient and customized retrieval-augmented-generation (RAG) algorithms that not only extract relevant information from diverse sources but also select the most pertinent toolkits in response to user queries. This enables the addressing of complex technical questions and provides seamless, automated access to internal resources. Additionally, DECO incorporates a robust mechanism for converting unstructured incident logs into user-friendly, structured guides, effectively bridging the documentation gap. Feedback from users underscores DECO's pivotal role in simplifying complex engineering tasks, accelerating incident resolution, and bolstering organizational productivity. Since its launch in September 2023, DECO has demonstrated its effectiveness through extensive engagement, with tens of thousands of interactions from hundreds of active users across multiple organizations within the company.
Vamsa: Tracking Provenance in Data Science Scripts
Jan 07, 2020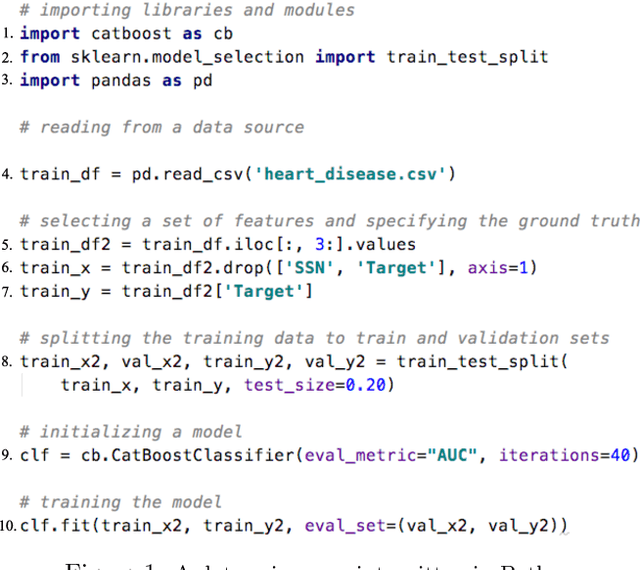

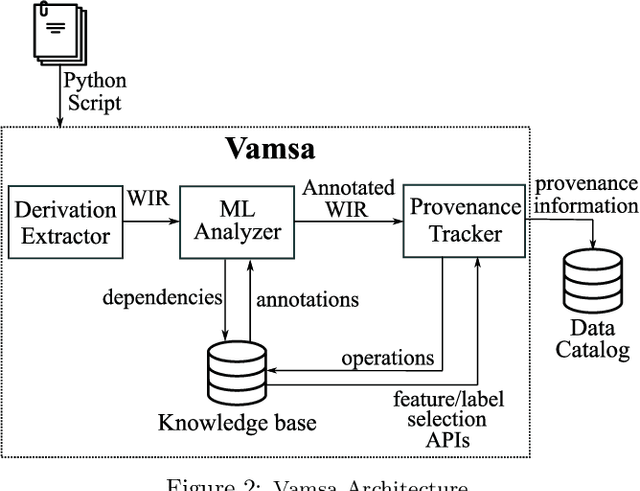

Machine learning (ML) which was initially adopted for search ranking and recommendation systems has firmly moved into the realm of core enterprise operations like sales optimization and preventative healthcare. For such ML applications, often deployed in regulated environments, the standards for user privacy, security, and data governance are substantially higher. This imposes the need for tracking provenance end-to-end, from the data sources used for training ML models to the predictions of the deployed models. In this work, we take a first step towards this direction by introducing the ML provenance tracking problem in the context of data science scripts. The fundamental idea is to automatically identify the relationships between data and ML models and in particular, to track which columns in a dataset have been used to derive the features of a ML model. We discuss the challenges in capturing such provenance information in the context of Python, the most common language used by data scientists. We then, present Vamsa, a modular system that extracts provenance from Python scripts without requiring any changes to the user's code. Using up to 450K real-world data science scripts from Kaggle and publicly available Python notebooks, we verify the effectiveness of Vamsa in terms of coverage, and performance. We also evaluate Vamsa's accuracy on a smaller subset of manually labeled data. Our analysis shows that Vamsa's precision and recall range from 87.5% to 98.3% and its latency is typically in the order of milliseconds for scripts of average size.
Data Science through the looking glass and what we found there
Dec 19, 2019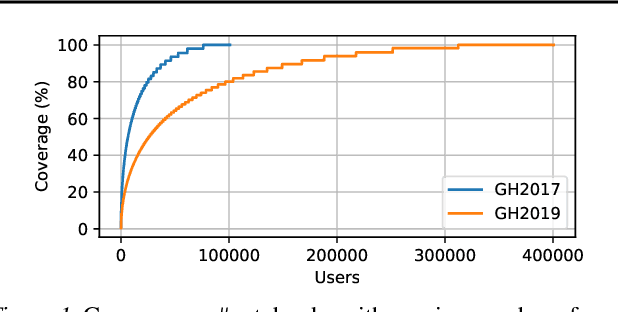
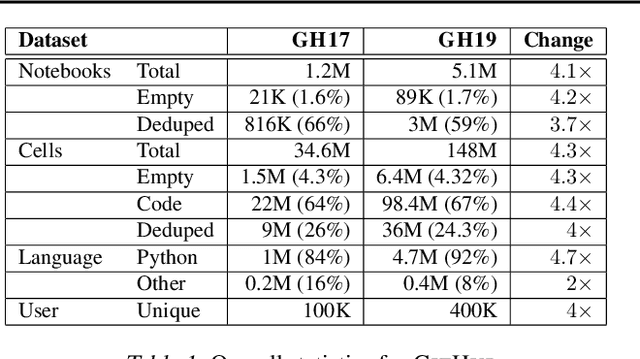
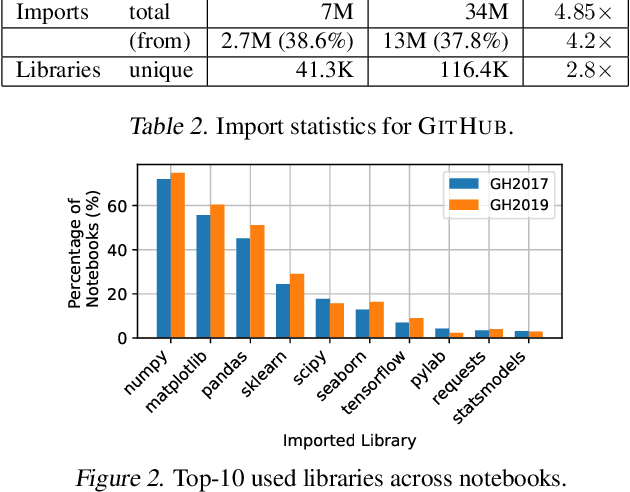
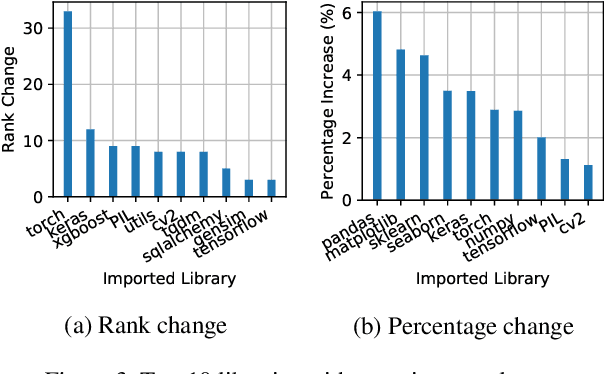
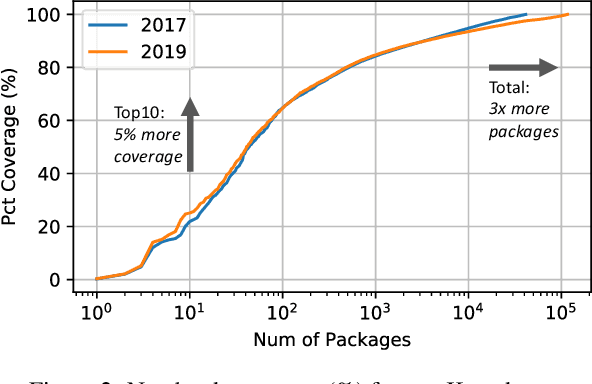
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.
Extending Relational Query Processing with ML Inference
Nov 01, 2019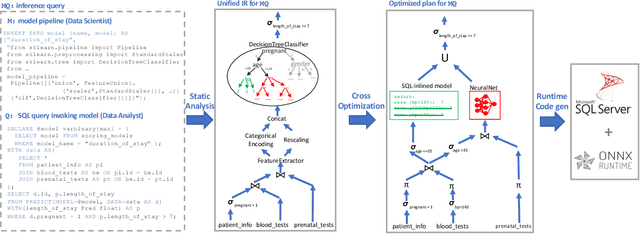

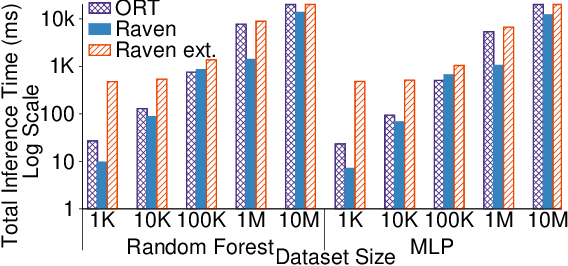
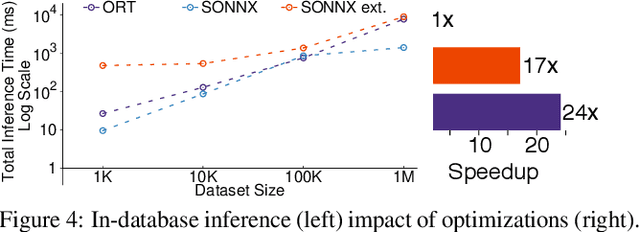
The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019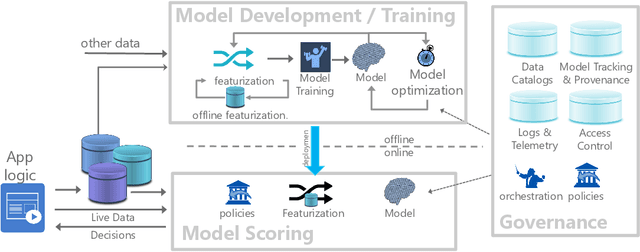
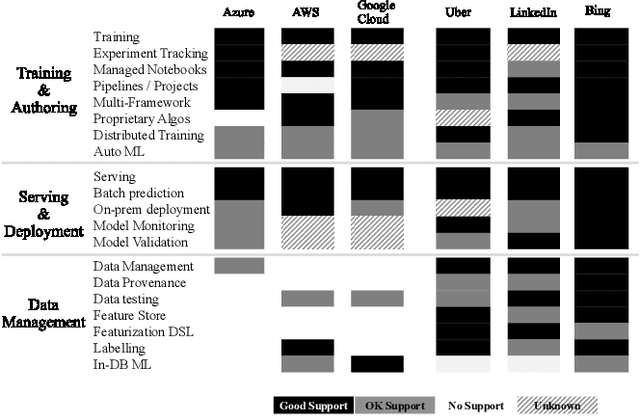
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.
Griffon: Reasoning about Job Anomalies with Unlabeled Data in Cloud-based Platforms
Aug 23, 2019

Microsoft's internal big data analytics platform is comprised of hundreds of thousands of machines, serving over half a million jobs daily, from thousands of users. The majority of these jobs are recurring and are crucial for the company's operation. Although administrators spend significant effort tuning system performance, some jobs inevitably experience slowdowns, i.e., their execution time degrades over previous runs. Currently, the investigation of such slowdowns is a labor-intensive and error-prone process, which costs Microsoft significant human and machine resources, and negatively impacts several lines of businesses. In this work, we present Griffin, a system we built and have deployed in production last year to automatically discover the root cause of job slowdowns. Existing solutions either rely on labeled data (i.e., resolved incidents with labeled reasons for job slowdowns), which is in most cases non-existent or non-trivial to acquire, or on time-series analysis of individual metrics that do not target specific jobs holistically. In contrast, in Griffin we cast the problem to a corresponding regression one that predicts the runtime of a job, and show how the relative contributions of the features used to train our interpretable model can be exploited to rank the potential causes of job slowdowns. Evaluated over historical incidents, we show that Griffin discovers slowdown causes that are consistent with the ones validated by domain-expert engineers, in a fraction of the time required by them.