 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVamsa: Tracking Provenance in Data Science Scripts
Jan 07, 2020

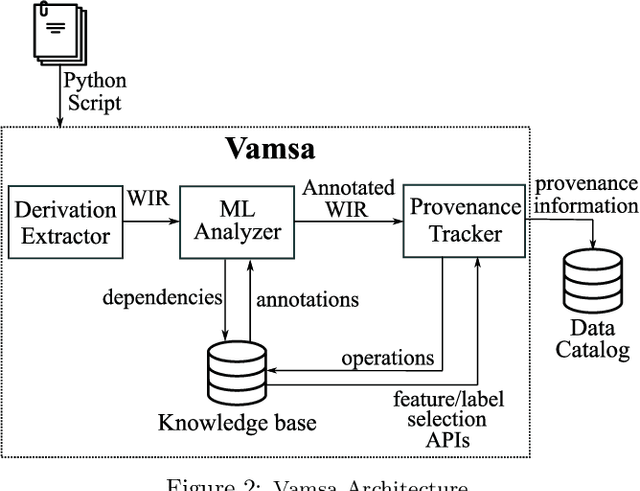

Machine learning (ML) which was initially adopted for search ranking and recommendation systems has firmly moved into the realm of core enterprise operations like sales optimization and preventative healthcare. For such ML applications, often deployed in regulated environments, the standards for user privacy, security, and data governance are substantially higher. This imposes the need for tracking provenance end-to-end, from the data sources used for training ML models to the predictions of the deployed models. In this work, we take a first step towards this direction by introducing the ML provenance tracking problem in the context of data science scripts. The fundamental idea is to automatically identify the relationships between data and ML models and in particular, to track which columns in a dataset have been used to derive the features of a ML model. We discuss the challenges in capturing such provenance information in the context of Python, the most common language used by data scientists. We then, present Vamsa, a modular system that extracts provenance from Python scripts without requiring any changes to the user's code. Using up to 450K real-world data science scripts from Kaggle and publicly available Python notebooks, we verify the effectiveness of Vamsa in terms of coverage, and performance. We also evaluate Vamsa's accuracy on a smaller subset of manually labeled data. Our analysis shows that Vamsa's precision and recall range from 87.5% to 98.3% and its latency is typically in the order of milliseconds for scripts of average size.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019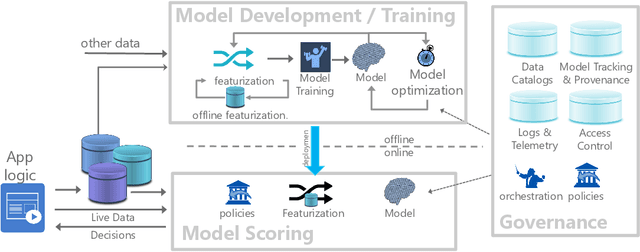
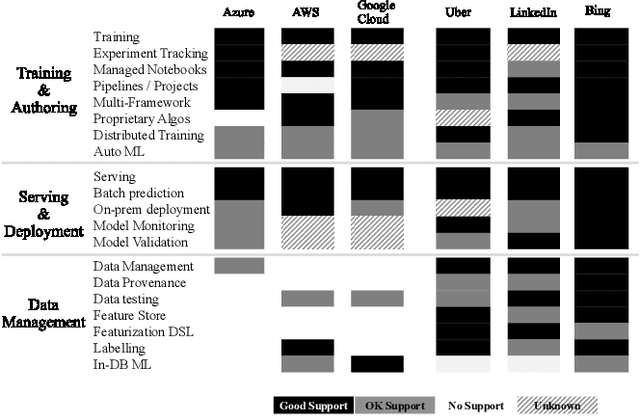
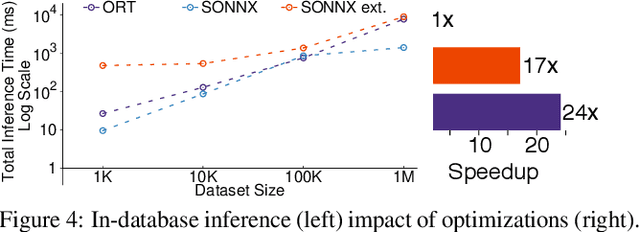
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.