 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Clinical Data Using Generative AI
May 30, 2025Artificial Intelligence (AI) is making a major impact on healthcare, particularly through its application in natural language processing (NLP) and predictive analytics. The healthcare sector has increasingly adopted AI for tasks such as clinical data analysis and medical code assignment. However, searching for clinical information in large and often unorganized datasets remains a manual and error-prone process. Assisting this process with automations can help physicians improve their operational productivity significantly. In this paper, we present a generative AI approach, coined SearchAI, to enhance the accuracy and efficiency of searching clinical data. Unlike traditional code assignment, which is a one-to-one problem, clinical data search is a one-to-many problem, i.e., a given search query can map to a family of codes. Healthcare professionals typically search for groups of related diseases, drugs, or conditions that map to many codes, and therefore, they need search tools that can handle keyword synonyms, semantic variants, and broad open-ended queries. SearchAI employs a hierarchical model that respects the coding hierarchy and improves the traversal of relationships from parent to child nodes. SearchAI navigates these hierarchies predictively and ensures that all paths are reachable without losing any relevant nodes. To evaluate the effectiveness of SearchAI, we conducted a series of experiments using both public and production datasets. Our results show that SearchAI outperforms default hierarchical traversals across several metrics, including accuracy, robustness, performance, and scalability. SearchAI can help make clinical data more accessible, leading to streamlined workflows, reduced administrative burden, and enhanced coding and diagnostic accuracy.
Sibyl: Forecasting Time-Evolving Query Workloads
Jan 08, 2024Database systems often rely on historical query traces to perform workload-based performance tuning. However, real production workloads are time-evolving, making historical queries ineffective for optimizing future workloads. To address this challenge, we propose SIBYL, an end-to-end machine learning-based framework that accurately forecasts a sequence of future queries, with the entire query statements, in various prediction windows. Drawing insights from real-workloads, we propose template-based featurization techniques and develop a stacked-LSTM with an encoder-decoder architecture for accurate forecasting of query workloads. We also develop techniques to improve forecasting accuracy over large prediction windows and achieve high scalability over large workloads with high variability in arrival rates of queries. Finally, we propose techniques to handle workload drifts. Our evaluation on four real workloads demonstrates that SIBYL can forecast workloads with an $87.3\%$ median F1 score, and can result in $1.7\times$ and $1.3\times$ performance improvement when applied to materialized view selection and index selection applications, respectively.
GEqO: ML-Accelerated Semantic Equivalence Detection
Jan 02, 2024



Large scale analytics engines have become a core dependency for modern data-driven enterprises to derive business insights and drive actions. These engines support a large number of analytic jobs processing huge volumes of data on a daily basis, and workloads are often inundated with overlapping computations across multiple jobs. Reusing common computation is crucial for efficient cluster resource utilization and reducing job execution time. Detecting common computation is the first and key step for reducing this computational redundancy. However, detecting equivalence on large-scale analytics engines requires efficient and scalable solutions that are fully automated. In addition, to maximize computation reuse, equivalence needs to be detected at the semantic level instead of just the syntactic level (i.e., the ability to detect semantic equivalence of seemingly different-looking queries). Unfortunately, existing solutions fall short of satisfying these requirements. In this paper, we take a major step towards filling this gap by proposing GEqO, a portable and lightweight machine-learning-based framework for efficiently identifying semantically equivalent computations at scale. GEqO introduces two machine-learning-based filters that quickly prune out nonequivalent subexpressions and employs a semi-supervised learning feedback loop to iteratively improve its model with an intelligent sampling mechanism. Further, with its novel database-agnostic featurization method, GEqO can transfer the learning from one workload and database to another. Our extensive empirical evaluation shows that, on TPC-DS-like queries, GEqO yields significant performance gains-up to 200x faster than automated verifiers-and finds up to 2x more equivalences than optimizer and signature-based equivalence detection approaches.
Deploying a Steered Query Optimizer in Production at Microsoft
Oct 24, 2022
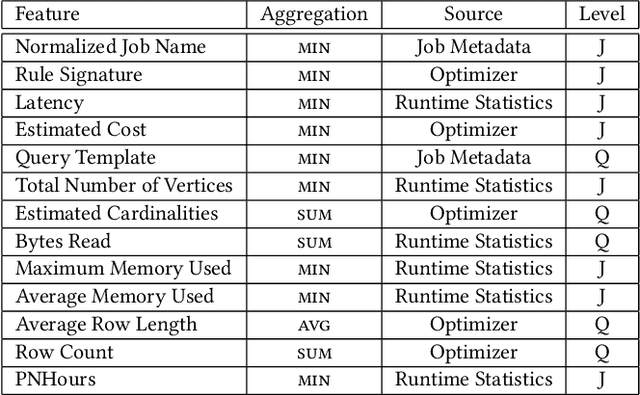
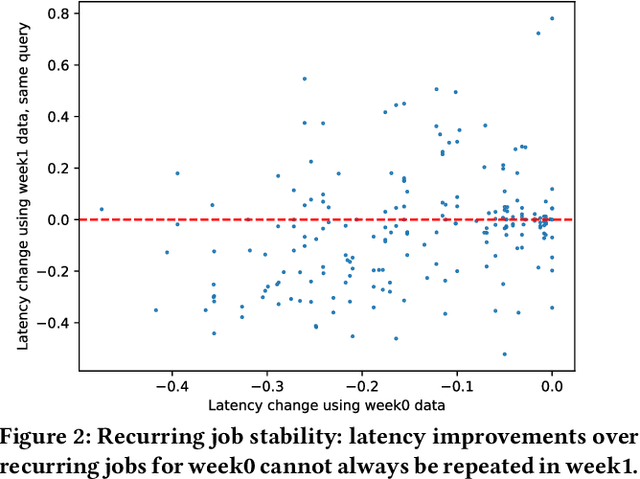
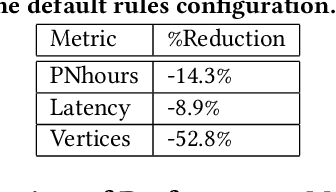
Modern analytical workloads are highly heterogeneous and massively complex, making generic query optimizers untenable for many customers and scenarios. As a result, it is important to specialize these optimizers to instances of the workloads. In this paper, we continue a recent line of work in steering a query optimizer towards better plans for a given workload, and make major strides in pushing previous research ideas to production deployment. Along the way we solve several operational challenges including, making steering actions more manageable, keeping the costs of steering within budget, and avoiding unexpected performance regressions in production. Our resulting system, QQ-advisor, essentially externalizes the query planner to a massive offline pipeline for better exploration and specialization. We discuss various aspects of our design and show detailed results over production SCOPE workloads at Microsoft, where the system is currently enabled by default.
Predictive Price-Performance Optimization for Serverless Query Processing
Dec 16, 2021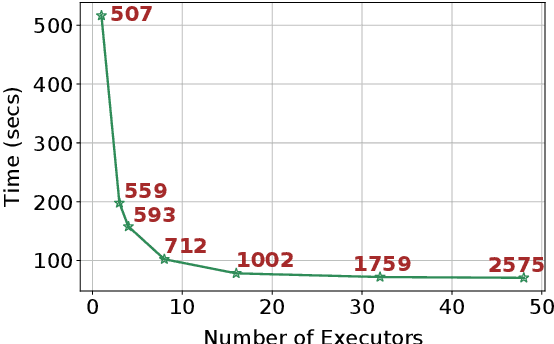
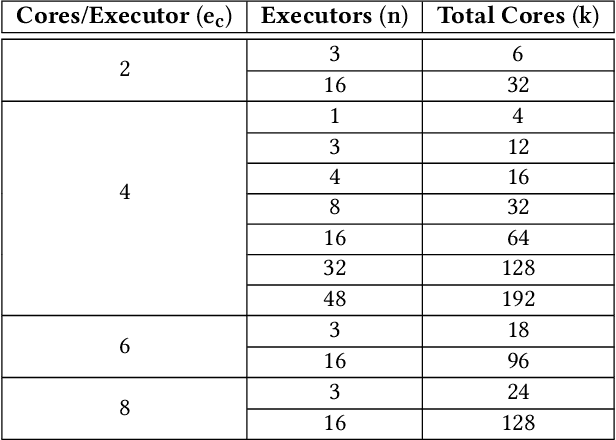
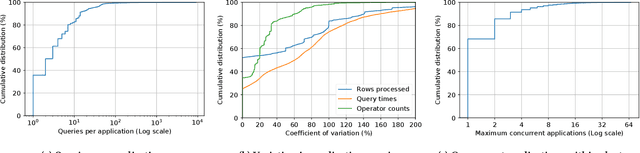
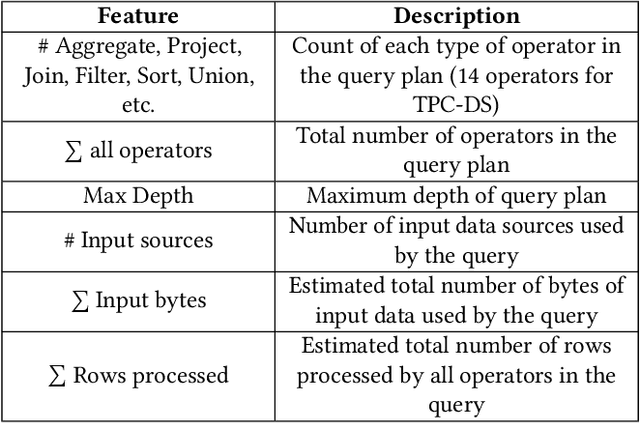
We present an efficient, parametric modeling framework for predictive resource allocations, focusing on the amount of computational resources, that can optimize for a range of price-performance objectives for data analytics in serverless query processing settings. We discuss and evaluate in depth how our system, AutoExecutor, can use this framework to automatically select near-optimal executor and core counts for Spark SQL queries running on Azure Synapse. Our techniques improve upon Spark's in-built, reactive, dynamic executor allocation capabilities by substantially reducing the total executors allocated and executor occupancy while running queries, thereby freeing up executors that can potentially be used by other concurrent queries or in reducing the overall cluster provisioning needs. In contrast with post-execution analysis tools such as Sparklens, we predict resource allocations for queries before executing them and can also account for changes in input data sizes for predicting the desired allocations.
Phoebe: A Learning-based Checkpoint Optimizer
Oct 05, 2021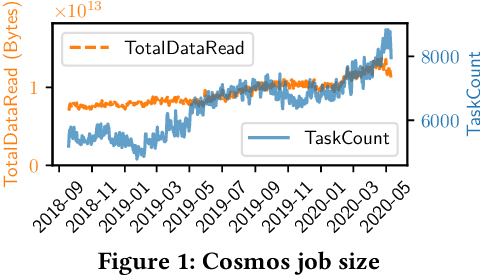
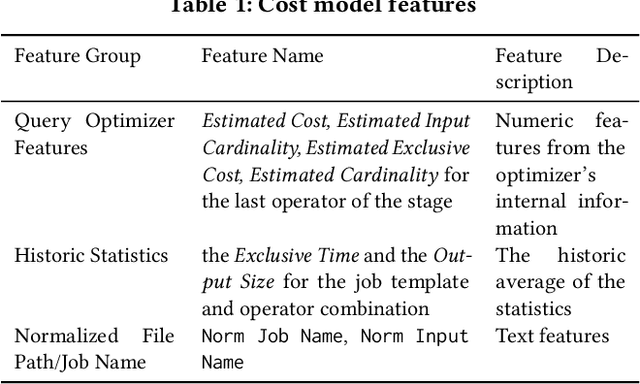
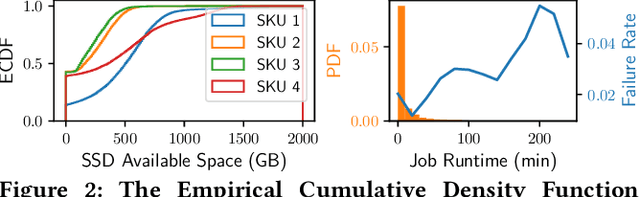
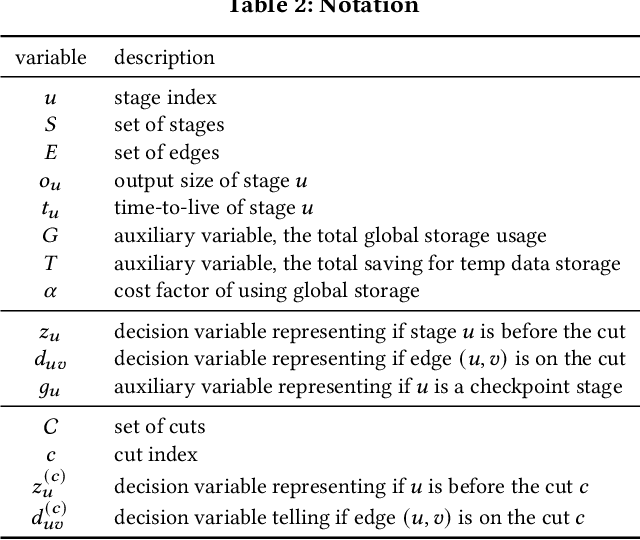
Easy-to-use programming interfaces paired with cloud-scale processing engines have enabled big data system users to author arbitrarily complex analytical jobs over massive volumes of data. However, as the complexity and scale of analytical jobs increase, they encounter a number of unforeseen problems, hotspots with large intermediate data on temporary storage, longer job recovery time after failures, and worse query optimizer estimates being examples of issues that we are facing at Microsoft. To address these issues, we propose Phoebe, an efficient learning-based checkpoint optimizer. Given a set of constraints and an objective function at compile-time, Phoebe is able to determine the decomposition of job plans, and the optimal set of checkpoints to preserve their outputs to durable global storage. Phoebe consists of three machine learning predictors and one optimization module. For each stage of a job, Phoebe makes accurate predictions for: (1) the execution time, (2) the output size, and (3) the start/end time taking into account the inter-stage dependencies. Using these predictions, we formulate checkpoint optimization as an integer programming problem and propose a scalable heuristic algorithm that meets the latency requirement of the production environment. We demonstrate the effectiveness of Phoebe in production workloads, and show that we can free the temporary storage on hotspots by more than 70% and restart failed jobs 68% faster on average with minimum performance impact. Phoebe also illustrates that adding multiple sets of checkpoints is not cost-efficient, which dramatically reduces the complexity of the optimization.
Optimal Resource Allocation for Serverless Queries
Jul 19, 2021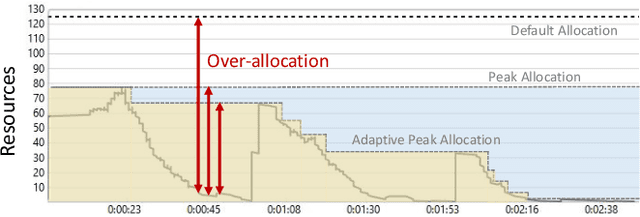
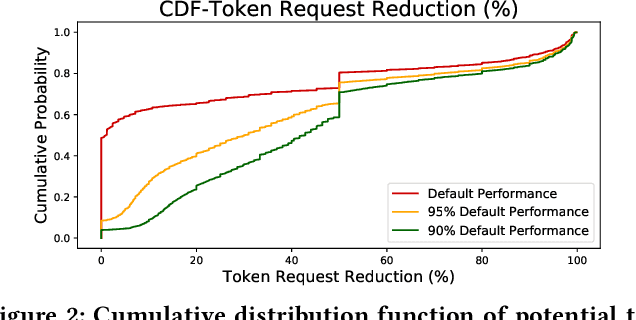

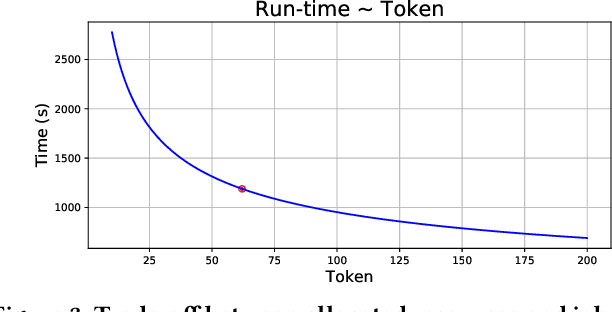
Optimizing resource allocation for analytical workloads is vital for reducing costs of cloud-data services. At the same time, it is incredibly hard for users to allocate resources per query in serverless processing systems, and they frequently misallocate by orders of magnitude. Unfortunately, prior work focused on predicting peak allocation while ignoring aggressive trade-offs between resource allocation and run-time. Additionally, these methods fail to predict allocation for queries that have not been observed in the past. In this paper, we tackle both these problems. We introduce a system for optimal resource allocation that can predict performance with aggressive trade-offs, for both new and past observed queries. We introduce the notion of a performance characteristic curve (PCC) as a parameterized representation that can compactly capture the relationship between resources and performance. To tackle training data sparsity, we introduce a novel data augmentation technique to efficiently synthesize the entire PCC using a single run of the query. Lastly, we demonstrate the advantages of a constrained loss function coupled with GNNs, over traditional ML methods, for capturing the domain specific behavior through an extensive experimental evaluation over SCOPE big data workloads at Microsoft.
Seagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020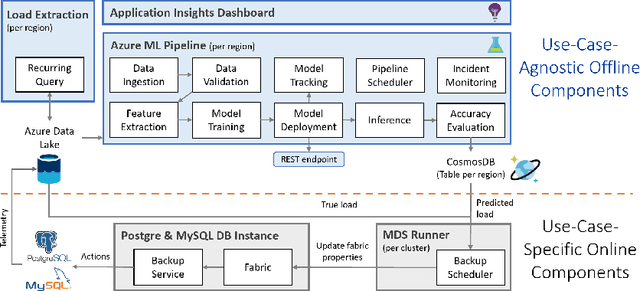
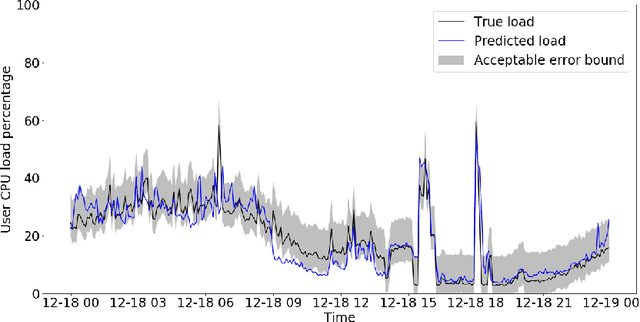
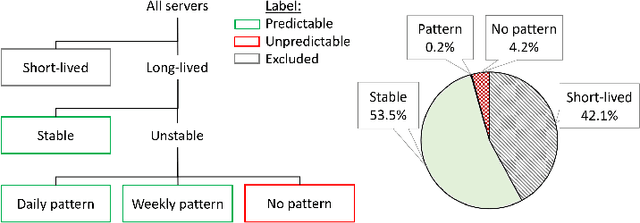
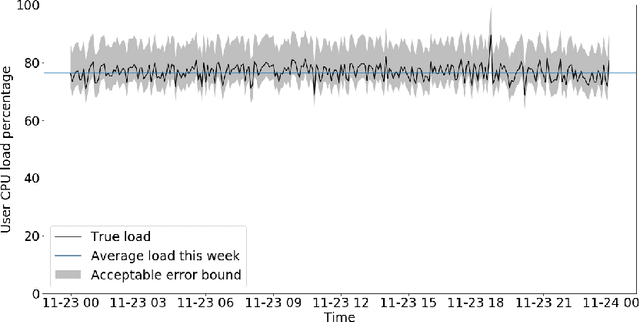
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019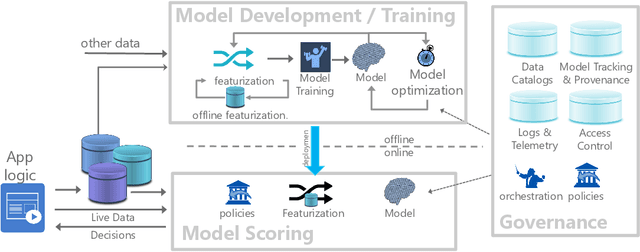
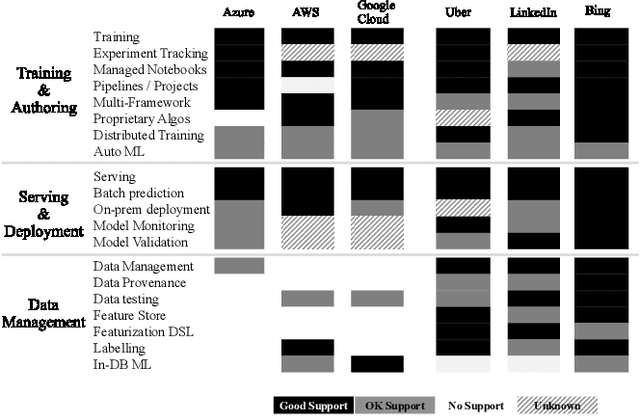
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.