 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Memory from a Computer Architecture Perspective: Visions and Challenges Ahead
Mar 09, 2026As LLM agents evolve into collaborative multi-agent systems, their memory requirements grow rapidly in complexity. This position paper frames multi-agent memory as a computer architecture problem. We distinguish shared and distributed memory paradigms, propose a three-layer memory hierarchy (I/O, cache, and memory), and identify two critical protocol gaps: cache sharing across agents and structured memory access control. We argue that the most pressing open challenge is multi-agent memory consistency. Our architectural framing provides a foundation for building reliable, scalable multi-agent systems.
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications
Feb 26, 2026Large Language Models (LLMs) are deployed as autonomous agents in increasingly complex applications, where enabling long-horizon memory is critical for achieving strong performance. However, a significant gap exists between practical applications and current evaluation standards for agent memory: existing benchmarks primarily focus on dialogue-centric, human-agent interactions. In reality, agent memory consists of a continuous stream of agent-environment interactions that are primarily composed of machine-generated representations. To bridge this gap, we introduce AMA-Bench (Agent Memory with Any length), which evaluates long-horizon memory for LLMs in real agentic applications. It features two key components: (1) a set of real-world agentic trajectories across representative agentic applications, paired with expert-curated QA, and (2) a set of synthetic agentic trajectories that scale to arbitrary horizons, paired with rule-based QA. Our comprehensive study shows that existing memory systems underperform on AMA-Bench primarily because they lack causality and objective information and are constrained by the lossy nature of similarity-based retrieval employed by many memory systems. To address these limitations, we propose AMA-Agent, an effective memory system featuring a causality graph and tool-augmented retrieval. Our results demonstrate that AMA-Agent achieves 57.22% average accuracy on AMA-Bench, surpassing the strongest memory system baselines by 11.16%.
LLM4Cov: Execution-Aware Agentic Learning for High-coverage Testbench Generation
Feb 18, 2026Execution-aware LLM agents offer a promising paradigm for learning from tool feedback, but such feedback is often expensive and slow to obtain, making online reinforcement learning (RL) impractical. High-coverage hardware verification exemplifies this challenge due to its reliance on industrial simulators and non-differentiable execution signals. We propose LLM4Cov, an offline agent-learning framework that models verification as memoryless state transitions guided by deterministic evaluators. Building on this formulation, we introduce execution-validated data curation, policy-aware agentic data synthesis, and worst-state-prioritized sampling to enable scalable learning under execution constraints. We further curate a reality-aligned benchmark adapted from an existing verification suite through a revised evaluation protocol. Using the proposed pipeline, a compact 4B-parameter model achieves 69.2% coverage pass rate under agentic evaluation, outperforming its teacher by 5.3% and demonstrating competitive performance against models an order of magnitude larger.
Double-P: Hierarchical Top-P Sparse Attention for Long-Context LLMs
Feb 05, 2026As long-context inference becomes central to large language models (LLMs), attention over growing key-value caches emerges as a dominant decoding bottleneck, motivating sparse attention for scalable inference. Fixed-budget top-k sparse attention cannot adapt to heterogeneous attention distributions across heads and layers, whereas top-p sparse attention directly preserves attention mass and provides stronger accuracy guarantees. Existing top-p methods, however, fail to jointly optimize top-p accuracy, selection overhead, and sparse attention cost, which limits their overall efficiency. We present Double-P, a hierarchical sparse attention framework that optimizes all three stages. Double-P first performs coarse-grained top-p estimation at the cluster level using size-weighted centroids, then adaptively refines computation through a second top-p stage that allocates token-level attention only when needed. Across long-context benchmarks, Double-P consistently achieves near-zero accuracy drop, reducing attention computation overhead by up to 1.8x and delivers up to 1.3x end-to-end decoding speedup over state-of-the-art fixed-budget sparse attention methods.
ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
Jan 29, 2026While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs' performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical structures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the-art Claude-4.5-opus achieving only 30.74\% on Verilog generation and 13.33\% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95\% pass rates. Additionally, to help enhance LLM reference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git.
PRO-V: An Efficient Program Generation Multi-Agent System for Automatic RTL Verification
Jun 13, 2025LLM-assisted hardware verification is gaining substantial attention due to its potential to significantly reduce the cost and effort of crafting effective testbenches. It also serves as a critical enabler for LLM-aided end-to-end hardware language design. However, existing current LLMs often struggle with Register Transfer Level (RTL) code generation, resulting in testbenches that exhibit functional errors in Hardware Description Languages (HDL) logic. Motivated by the strong performance of LLMs in Python code generation under inference-time sampling strategies, and their promising capabilities as judge agents, we propose PRO-V a fully program generation multi-agent system for robust RTL verification. Pro-V incorporates an efficient best-of-n iterative sampling strategy to enhance the correctness of generated testbenches. Moreover, it introduces an LLM-as-a-judge aid validation framework featuring an automated prompt generation pipeline. By converting rule-based static analysis from the compiler into natural language through in-context learning, this pipeline enables LLMs to assist the compiler in determining whether verification failures stem from errors in the RTL design or the testbench. PRO-V attains a verification accuracy of 87.17% on golden RTL implementations and 76.28% on RTL mutants. Our code is open-sourced at https://github.com/stable-lab/Pro-V.
SHARP: Accelerating Language Model Inference by SHaring Adjacent layers with Recovery Parameters
Feb 11, 2025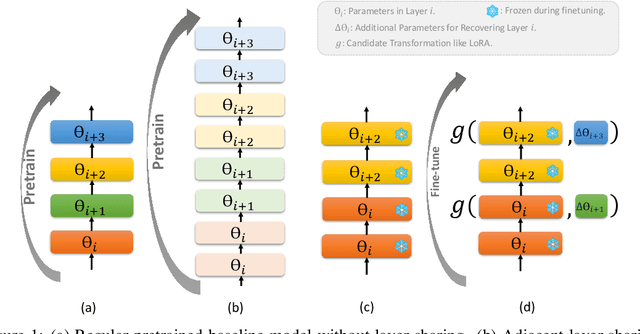

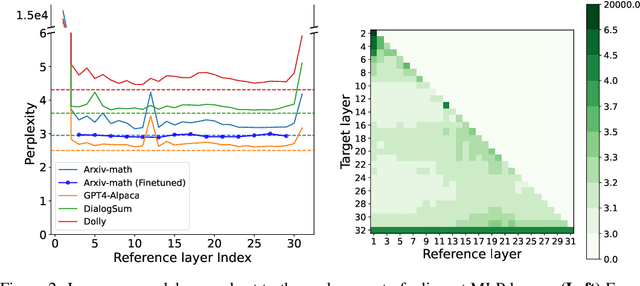
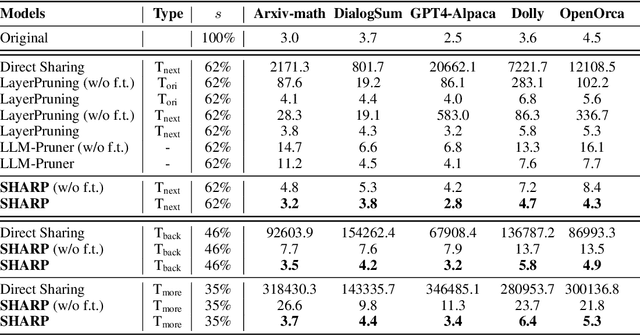
While Large language models (LLMs) have advanced natural language processing tasks, their growing computational and memory demands make deployment on resource-constrained devices like mobile phones increasingly challenging. In this paper, we propose SHARP (SHaring Adjacent Layers with Recovery Parameters), a novel approach to accelerate LLM inference by sharing parameters across adjacent layers, thus reducing memory load overhead, while introducing low-rank recovery parameters to maintain performance. Inspired by observations that consecutive layers have similar outputs, SHARP employs a two-stage recovery process: Single Layer Warmup (SLW), and Supervised Fine-Tuning (SFT). The SLW stage aligns the outputs of the shared layers using L_2 loss, providing a good initialization for the following SFT stage to further restore the model performance. Extensive experiments demonstrate that SHARP can recover the model's perplexity on various in-distribution tasks using no more than 50k fine-tuning data while reducing the number of stored MLP parameters by 38% to 65%. We also conduct several ablation studies of SHARP and show that replacing layers towards the later parts of the model yields better performance retention, and that different recovery parameterizations perform similarly when parameter counts are matched. Furthermore, SHARP saves 42.8% in model storage and reduces the total inference time by 42.2% compared to the original Llama2-7b model on mobile devices. Our results highlight SHARP as an efficient solution for reducing inference costs in deploying LLMs without the need for pretraining-scale resources.
MAGE: A Multi-Agent Engine for Automated RTL Code Generation
Dec 10, 2024



The automatic generation of RTL code (e.g., Verilog) through natural language instructions has emerged as a promising direction with the advancement of large language models (LLMs). However, producing RTL code that is both syntactically and functionally correct remains a significant challenge. Existing single-LLM-agent approaches face substantial limitations because they must navigate between various programming languages and handle intricate generation, verification, and modification tasks. To address these challenges, this paper introduces MAGE, the first open-source multi-agent AI system designed for robust and accurate Verilog RTL code generation. We propose a novel high-temperature RTL candidate sampling and debugging system that effectively explores the space of code candidates and significantly improves the quality of the candidates. Furthermore, we design a novel Verilog-state checkpoint checking mechanism that enables early detection of functional errors and delivers precise feedback for targeted fixes, significantly enhancing the functional correctness of the generated RTL code. MAGE achieves a 95.7% rate of syntactic and functional correctness code generation on VerilogEval-Human 2 benchmark, surpassing the state-of-the-art Claude-3.5-sonnet by 23.3 %, demonstrating a robust and reliable approach for AI-driven RTL design workflows.
A Step Towards Mixture of Grader: Statistical Analysis of Existing Automatic Evaluation Metrics
Oct 13, 2024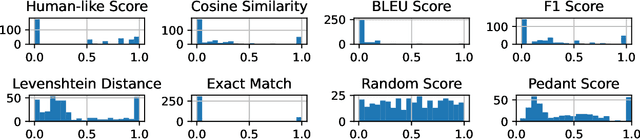
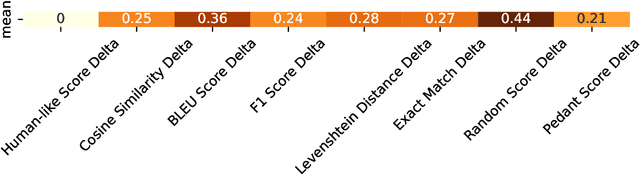
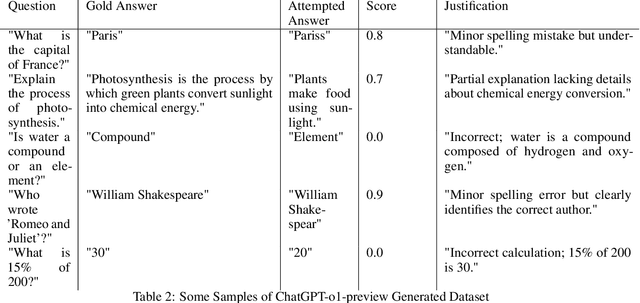
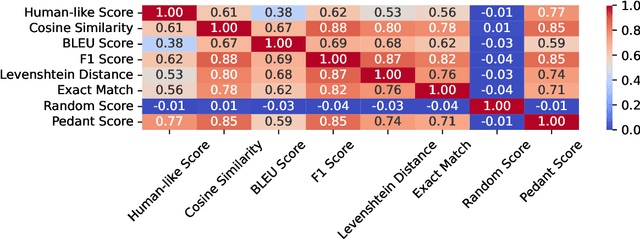
The explosion of open-sourced models and Question-Answering (QA) datasets emphasizes the importance of automated QA evaluation. We studied the statistics of the existing evaluation metrics for a better understanding of their limitations. By measuring the correlation coefficients of each evaluation metric concerning human-like evaluation score, we observed the following: (1) existing metrics have a high correlation among them concerning the question type (e.g., single word, single phrase, etc.), (2) no single metric can adequately estimate the human-like evaluation. As a potential solution, we discuss how a Mixture Of Grader could potentially improve the auto QA evaluator quality.
Grounding Large Language Models In Embodied Environment With Imperfect World Models
Oct 03, 2024

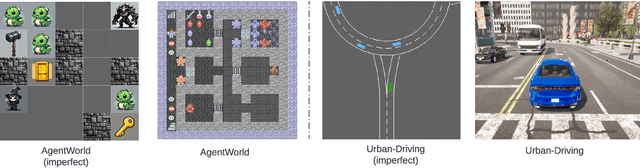
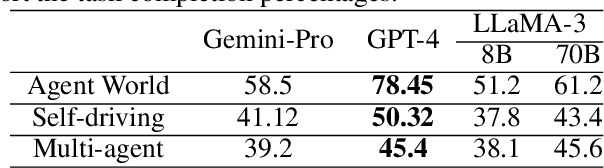
Despite a widespread success in various applications, large language models (LLMs) often stumble when tackling basic physical reasoning or executing robotics tasks, due to a lack of direct experience with the physical nuances of the real world. To address these issues, we propose a Grounding Large language model with Imperfect world MOdel (GLIMO), which utilizes proxy world models such as simulators to collect and synthesize trining data. GLIMO incorporates an LLM agent-based data generator to automatically create high-quality and diverse instruction datasets. The generator includes an iterative self-refining module for temporally consistent experience sampling, a diverse set of question-answering instruction seeds, and a retrieval-augmented generation module for reflecting on prior experiences. Comprehensive experiments show that our approach improve the performance of strong open-source LLMs like LLaMA-3 with a performance boost of 2.04 $\times$, 1.54 $\times$, and 1.82 $\times$ across three different benchmarks, respectively. The performance is able to compete with or surpass their larger counterparts such as GPT-4.