 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Large Language Models In Embodied Environment With Imperfect World Models
Oct 03, 2024

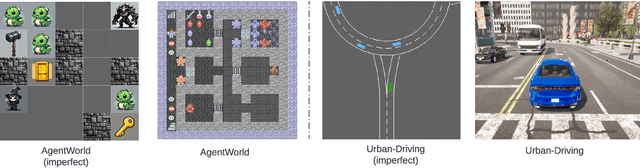
Despite a widespread success in various applications, large language models (LLMs) often stumble when tackling basic physical reasoning or executing robotics tasks, due to a lack of direct experience with the physical nuances of the real world. To address these issues, we propose a Grounding Large language model with Imperfect world MOdel (GLIMO), which utilizes proxy world models such as simulators to collect and synthesize trining data. GLIMO incorporates an LLM agent-based data generator to automatically create high-quality and diverse instruction datasets. The generator includes an iterative self-refining module for temporally consistent experience sampling, a diverse set of question-answering instruction seeds, and a retrieval-augmented generation module for reflecting on prior experiences. Comprehensive experiments show that our approach improve the performance of strong open-source LLMs like LLaMA-3 with a performance boost of 2.04 $\times$, 1.54 $\times$, and 1.82 $\times$ across three different benchmarks, respectively. The performance is able to compete with or surpass their larger counterparts such as GPT-4.
Interpretable and Flexible Target-Conditioned Neural Planners For Autonomous Vehicles
Sep 23, 2023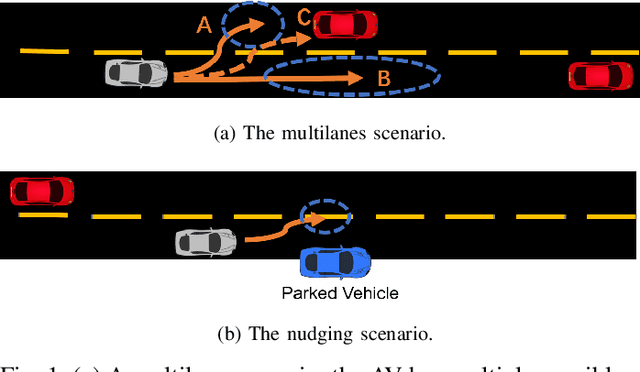



Learning-based approaches to autonomous vehicle planners have the potential to scale to many complicated real-world driving scenarios by leveraging huge amounts of driver demonstrations. However, prior work only learns to estimate a single planning trajectory, while there may be multiple acceptable plans in real-world scenarios. To solve the problem, we propose an interpretable neural planner to regress a heatmap, which effectively represents multiple potential goals in the bird's-eye view of an autonomous vehicle. The planner employs an adaptive Gaussian kernel and relaxed hourglass loss to better capture the uncertainty of planning problems. We also use a negative Gaussian kernel to add supervision to the heatmap regression, enabling the model to learn collision avoidance effectively. Our systematic evaluation on the Lyft Open Dataset across a diverse range of real-world driving scenarios shows that our model achieves a safer and more flexible driving performance than prior works.
Deep Learning Approaches in Pavement Distress Identification: A Review
Aug 01, 2023



This paper presents a comprehensive review of recent advancements in image processing and deep learning techniques for pavement distress detection and classification, a critical aspect in modern pavement management systems. The conventional manual inspection process conducted by human experts is gradually being superseded by automated solutions, leveraging machine learning and deep learning algorithms to enhance efficiency and accuracy. The ability of these algorithms to discern patterns and make predictions based on extensive datasets has revolutionized the domain of pavement distress identification. The paper investigates the integration of unmanned aerial vehicles (UAVs) for data collection, offering unique advantages such as aerial perspectives and efficient coverage of large areas. By capturing high-resolution images, UAVs provide valuable data that can be processed using deep learning algorithms to detect and classify various pavement distresses effectively. While the primary focus is on 2D image processing, the paper also acknowledges the challenges associated with 3D images, such as sensor limitations and computational requirements. Understanding these challenges is crucial for further advancements in the field. The findings of this review significantly contribute to the evolution of pavement distress detection, fostering the development of efficient pavement management systems. As automated approaches continue to mature, the implementation of deep learning techniques holds great promise in ensuring safer and more durable road infrastructure for the benefit of society.
Safety-Critical Scenario Generation Via Reinforcement Learning Based Editing
Jun 25, 2023



Generating safety-critical scenarios is essential for testing and verifying the safety of autonomous vehicles. Traditional optimization techniques suffer from the curse of dimensionality and limit the search space to fixed parameter spaces. To address these challenges, we propose a deep reinforcement learning approach that generates scenarios by sequential editing, such as adding new agents or modifying the trajectories of the existing agents. Our framework employs a reward function consisting of both risk and plausibility objectives. The plausibility objective leverages generative models, such as a variational autoencoder, to learn the likelihood of the generated parameters from the training datasets; It penalizes the generation of unlikely scenarios. Our approach overcomes the dimensionality challenge and explores a wide range of safety-critical scenarios. Our evaluation demonstrates that the proposed method generates safety-critical scenarios of higher quality compared with previous approaches.
COLA: Characterizing and Optimizing the Tail Latency for Safe Level-4 Autonomous Vehicle Systems
May 11, 2023



Autonomous vehicles (AVs) are envisioned to revolutionize our life by providing safe, relaxing, and convenient ground transportation. The computing systems in such vehicles are required to interpret various sensor data and generate responses to the environment in a timely manner to ensure driving safety. However, such timing-related safety requirements are largely unexplored in prior works. In this paper, we conduct a systematic study to understand the timing requirements of AV systems. We focus on investigating and mitigating the sources of tail latency in Level-4 AV computing systems. We observe that the performance of AV algorithms is not uniformly distributed -- instead, the latency is susceptible to vehicle environment fluctuations, such as traffic density. This contributes to burst computation and memory access in response to the traffic, and further leads to tail latency in the system. Furthermore, we observe that tail latency also comes from a mismatch between the pre-configured AV computation pipeline and the dynamic latency requirements in real-world driving scenarios. Based on these observations, we propose a set of system designs to mitigate AV tail latency. We demonstrate our design on widely-used industrial Level-4 AV systems, Baidu Apollo and Autoware. The evaluation shows that our design achieves 1.65 X improvement over the worst-case latency and 1.3 X over the average latency, and avoids 93% of accidents on Apollo.
A Neural-based Program Decompiler
Jun 28, 2019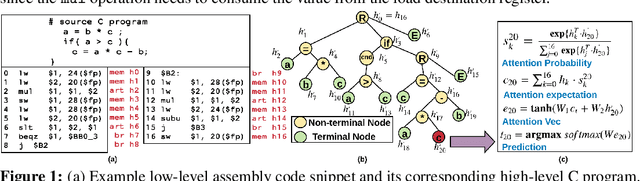
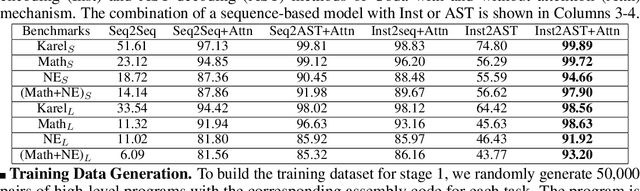

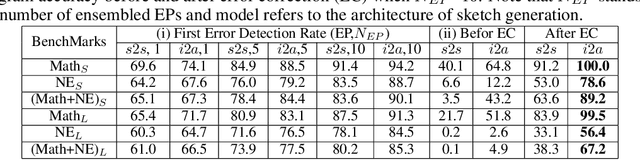
Reverse engineering of binary executables is a critical problem in the computer security domain. On the one hand, malicious parties may recover interpretable source codes from the software products to gain commercial advantages. On the other hand, binary decompilation can be leveraged for code vulnerability analysis and malware detection. However, efficient binary decompilation is challenging. Conventional decompilers have the following major limitations: (i) they are only applicable to specific source-target language pair, hence incurs undesired development cost for new language tasks; (ii) their output high-level code cannot effectively preserve the correct functionality of the input binary; (iii) their output program does not capture the semantics of the input and the reversed program is hard to interpret. To address the above problems, we propose Coda, the first end-to-end neural-based framework for code decompilation. Coda decomposes the decompilation task into two key phases: First, Coda employs an instruction type-aware encoder and a tree decoder for generating an abstract syntax tree (AST) with attention feeding during the code sketch generation stage. Second, Coda then updates the code sketch using an iterative error correction machine guided by an ensembled neural error predictor. By finding a good approximate candidate and then fixing it towards perfect, Coda achieves superior performance compared to baseline approaches. We assess Coda's performance with extensive experiments on various benchmarks. Evaluation results show that Coda achieves an average of 82\% program recovery accuracy on unseen binary samples, where the state-of-the-art decompilers yield 0\% accuracy. Furthermore, Coda outperforms the sequence-to-sequence model with attention by a margin of 70\% program accuracy.