 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphWalk: Enabling Reasoning in Large Language Models through Tool-Based Graph Navigation
Apr 02, 2026The use of knowledge graphs for grounding agents in real-world Q&A applications has become increasingly common. Answering complex queries often requires multi-hop reasoning and the ability to navigate vast relational structures. Standard approaches rely on prompting techniques that steer large language models to reason over raw graph context, or retrieval-augmented generation pipelines where relevant subgraphs are injected into the context. These, however, face severe limitations with enterprise-scale KGs that cannot fit in even the largest context windows available today. We present GraphWalk, a problem-agnostic, training-free, tool-based framework that allows off-the-shelf LLMs to reason through sequential graph navigation, dramatically increasing performance across different tasks. Unlike task-specific agent frameworks that encode domain knowledge into specialized tools, GraphWalk equips the LLM with a minimal set of orthogonal graph operations sufficient to traverse any graph structure. We evaluate whether models equipped with GraphWalk can compose these operations into correct multi-step reasoning chains, where each tool call represents a verifiable step creating a transparent execution trace. We first demonstrate our approach on maze traversal, a problem non-reasoning models are completely unable to solve, then present results on graphs resembling real-world enterprise knowledge graphs. To isolate structural reasoning from world knowledge, we evaluate on entirely synthetic graphs with random, non-semantic labels. Our benchmark spans 12 query templates from basic retrieval to compound first-order logic queries. Results show that tool-based traversal yields substantial and consistent gains over in-context baselines across all model families tested, with gains becoming more pronounced as scale increases, precisely where in-context approaches fail catastrophically.
When Iterative RAG Beats Ideal Evidence: A Diagnostic Study in Scientific Multi-hop Question Answering
Jan 27, 2026Retrieval-Augmented Generation (RAG) extends large language models (LLMs) beyond parametric knowledge, yet it is unclear when iterative retrieval-reasoning loops meaningfully outperform static RAG, particularly in scientific domains with multi-hop reasoning, sparse domain knowledge, and heterogeneous evidence. We provide the first controlled, mechanism-level diagnostic study of whether synchronized iterative retrieval and reasoning can surpass an idealized static upper bound (Gold Context) RAG. We benchmark eleven state-of-the-art LLMs under three regimes: (i) No Context, measuring reliance on parametric memory; (ii) Gold Context, where all oracle evidence is supplied at once; and (iii) Iterative RAG, a training-free controller that alternates retrieval, hypothesis refinement, and evidence-aware stopping. Using the chemistry-focused ChemKGMultiHopQA dataset, we isolate questions requiring genuine retrieval and analyze behavior with diagnostics spanning retrieval coverage gaps, anchor-carry drop, query quality, composition fidelity, and control calibration. Across models, Iterative RAG consistently outperforms Gold Context, with gains up to 25.6 percentage points, especially for non-reasoning fine-tuned models. Staged retrieval reduces late-hop failures, mitigates context overload, and enables dynamic correction of early hypothesis drift, but remaining failure modes include incomplete hop coverage, distractor latch trajectories, early stopping miscalibration, and high composition failure rates even with perfect retrieval. Overall, staged retrieval is often more influential than the mere presence of ideal evidence; we provide practical guidance for deploying and diagnosing RAG systems in specialized scientific settings and a foundation for more reliable, controllable iterative retrieval-reasoning frameworks.
Evaluating Multi-Hop Reasoning in Large Language Models: A Chemistry-Centric Case Study
Apr 23, 2025In this study, we introduced a new benchmark consisting of a curated dataset and a defined evaluation process to assess the compositional reasoning capabilities of large language models within the chemistry domain. We designed and validated a fully automated pipeline, verified by subject matter experts, to facilitate this task. Our approach integrates OpenAI reasoning models with named entity recognition (NER) systems to extract chemical entities from recent literature, which are then augmented with external knowledge bases to form a comprehensive knowledge graph. By generating multi-hop questions across these graphs, we assess LLM performance in both context-augmented and non-context augmented settings. Our experiments reveal that even state-of-the-art models face significant challenges in multi-hop compositional reasoning. The results reflect the importance of augmenting LLMs with document retrieval, which can have a substantial impact on improving their performance. However, even perfect retrieval accuracy with full context does not eliminate reasoning errors, underscoring the complexity of compositional reasoning. This work not only benchmarks and highlights the limitations of current LLMs but also presents a novel data generation pipeline capable of producing challenging reasoning datasets across various domains. Overall, this research advances our understanding of reasoning in computational linguistics.
ChemTEB: Chemical Text Embedding Benchmark, an Overview of Embedding Models Performance & Efficiency on a Specific Domain
Nov 30, 2024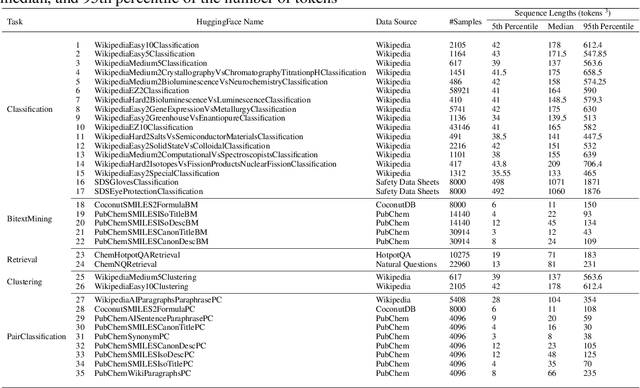
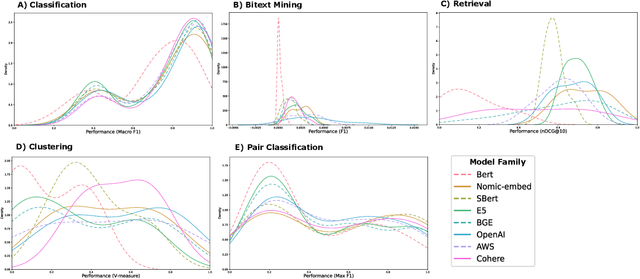
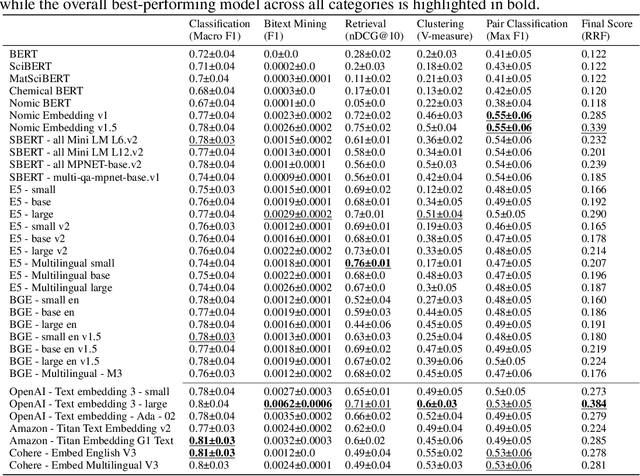
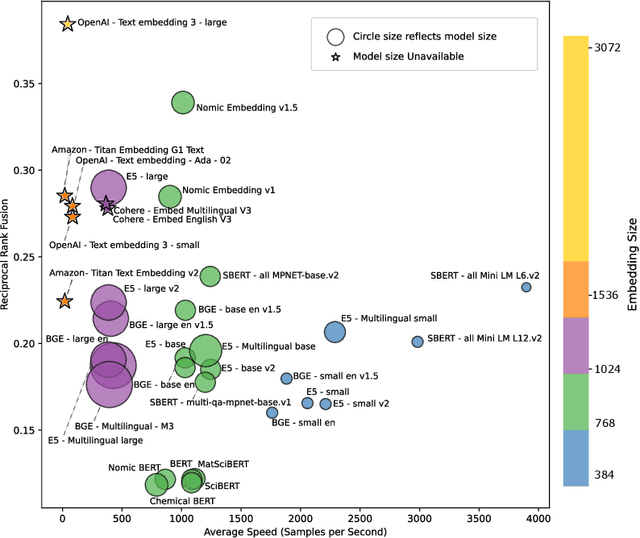
Recent advancements in language models have started a new era of superior information retrieval and content generation, with embedding models playing an important role in optimizing data representation efficiency and performance. While benchmarks like the Massive Text Embedding Benchmark (MTEB) have standardized the evaluation of general domain embedding models, a gap remains in specialized fields such as chemistry, which require tailored approaches due to domain-specific challenges. This paper introduces a novel benchmark, the Chemical Text Embedding Benchmark (ChemTEB), designed specifically for the chemical sciences. ChemTEB addresses the unique linguistic and semantic complexities of chemical literature and data, offering a comprehensive suite of tasks on chemical domain data. Through the evaluation of 34 open-source and proprietary models using this benchmark, we illuminate the strengths and weaknesses of current methodologies in processing and understanding chemical information. Our work aims to equip the research community with a standardized, domain-specific evaluation framework, promoting the development of more precise and efficient NLP models for chemistry-related applications. Furthermore, it provides insights into the performance of generic models in a domain-specific context. ChemTEB comes with open-source code and data, contributing further to its accessibility and utility.
Deep Learning Approaches in Pavement Distress Identification: A Review
Aug 01, 2023



This paper presents a comprehensive review of recent advancements in image processing and deep learning techniques for pavement distress detection and classification, a critical aspect in modern pavement management systems. The conventional manual inspection process conducted by human experts is gradually being superseded by automated solutions, leveraging machine learning and deep learning algorithms to enhance efficiency and accuracy. The ability of these algorithms to discern patterns and make predictions based on extensive datasets has revolutionized the domain of pavement distress identification. The paper investigates the integration of unmanned aerial vehicles (UAVs) for data collection, offering unique advantages such as aerial perspectives and efficient coverage of large areas. By capturing high-resolution images, UAVs provide valuable data that can be processed using deep learning algorithms to detect and classify various pavement distresses effectively. While the primary focus is on 2D image processing, the paper also acknowledges the challenges associated with 3D images, such as sensor limitations and computational requirements. Understanding these challenges is crucial for further advancements in the field. The findings of this review significantly contribute to the evolution of pavement distress detection, fostering the development of efficient pavement management systems. As automated approaches continue to mature, the implementation of deep learning techniques holds great promise in ensuring safer and more durable road infrastructure for the benefit of society.
MLGCN: An Ultra Efficient Graph Convolution Neural Model For 3D Point Cloud Analysis
Mar 31, 2023The analysis of 3D point clouds has diverse applications in robotics, vision and graphics. Processing them presents specific challenges since they are naturally sparse, can vary in spatial resolution and are typically unordered. Graph-based networks to abstract features have emerged as a promising alternative to convolutional neural networks for their analysis, but these can be computationally heavy as well as memory inefficient. To address these limitations we introduce a novel Multi-level Graph Convolution Neural (MLGCN) model, which uses Graph Neural Networks (GNN) blocks to extract features from 3D point clouds at specific locality levels. Our approach employs precomputed graph KNNs, where each KNN graph is shared between GCN blocks inside a GNN block, making it both efficient and effective compared to present models. We demonstrate the efficacy of our approach on point cloud based object classification and part segmentation tasks on benchmark datasets, showing that it produces comparable results to those of state-of-the-art models while requiring up to a thousand times fewer floating-point operations (FLOPs) and having significantly reduced storage requirements. Thus, our MLGCN model could be particular relevant to point cloud based 3D shape analysis in industrial applications when computing resources are scarce.
A Triplet-loss Dilated Residual Network for High-Resolution Representation Learning in Image Retrieval
Mar 15, 2023Content-based image retrieval is the process of retrieving a subset of images from an extensive image gallery based on visual contents, such as color, shape or spatial relations, and texture. In some applications, such as localization, image retrieval is employed as the initial step. In such cases, the accuracy of the top-retrieved images significantly affects the overall system accuracy. The current paper introduces a simple yet efficient image retrieval system with a fewer trainable parameters, which offers acceptable accuracy in top-retrieved images. The proposed method benefits from a dilated residual convolutional neural network with triplet loss. Experimental evaluations show that this model can extract richer information (i.e., high-resolution representations) by enlarging the receptive field, thus improving image retrieval accuracy without increasing the depth or complexity of the model. To enhance the extracted representations' robustness, the current research obtains candidate regions of interest from each feature map and applies Generalized-Mean pooling to the regions. As the choice of triplets in a triplet-based network affects the model training, we employ a triplet online mining method. We test the performance of the proposed method under various configurations on two of the challenging image-retrieval datasets, namely Revisited Paris6k (RPar) and UKBench. The experimental results show an accuracy of 94.54 and 80.23 (mean precision at rank 10) in the RPar medium and hard modes and 3.86 (recall at rank 4) in the UKBench dataset, respectively.
Contour Completion using Deep Structural Priors
Feb 09, 2023



Humans can easily perceive illusory contours and complete missing forms in fragmented shapes. This work investigates whether such capability can arise in convolutional neural networks (CNNs) using deep structural priors computed directly from images. In this work, we present a framework that completes disconnected contours and connects fragmented lines and curves. In our framework, we propose a model that does not even need to know which regions of the contour are eliminated. We introduce an iterative process that completes an incomplete image and we propose novel measures that guide this to find regions it needs to complete. Our model trains on a single image and fills in the contours with no additional training data. Our work builds a robust framework to achieve contour completion using deep structural priors and extensively investigate how such a model could be implemented.
Deep Learning Approaches on Image Captioning: A Review
Jan 31, 2022


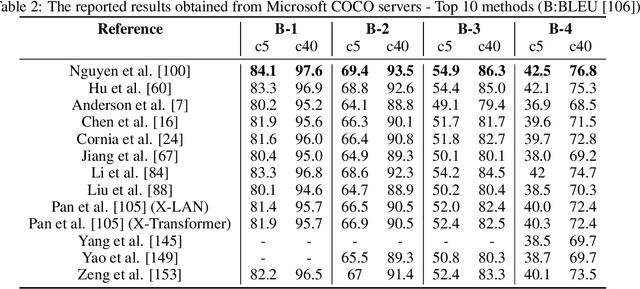
Automatic image captioning, which involves describing the contents of an image, is a challenging problem with many applications in various research fields. One notable example is designing assistants for the visually impaired. Recently, there have been significant advances in image captioning methods owing to the breakthroughs in deep learning. This survey paper aims to provide a structured review of recent image captioning techniques, and their performance, focusing mainly on deep learning methods. We also review widely-used datasets and performance metrics, in addition to the discussions on open problems and unsolved challenges in image captioning.
SMGRL: A Scalable Multi-resolution Graph Representation Learning Framework
Jan 29, 2022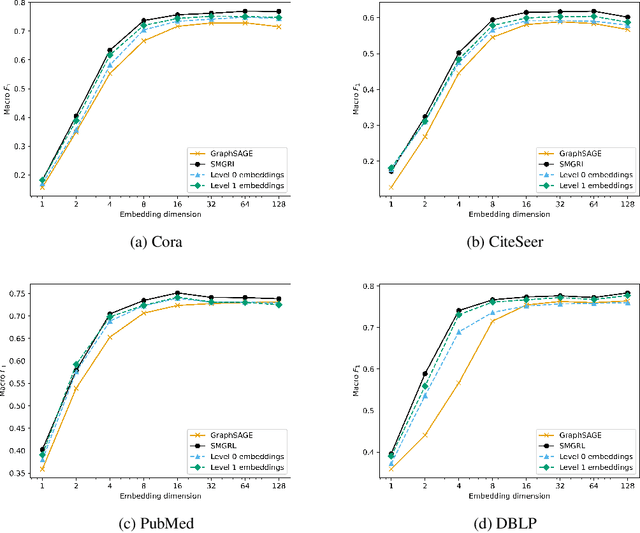
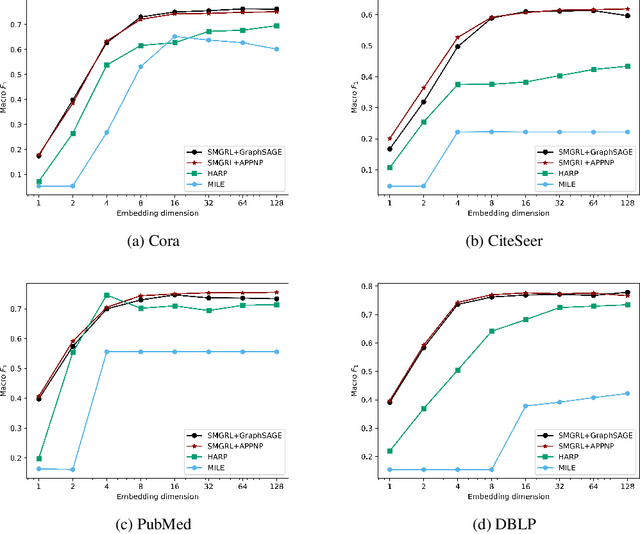
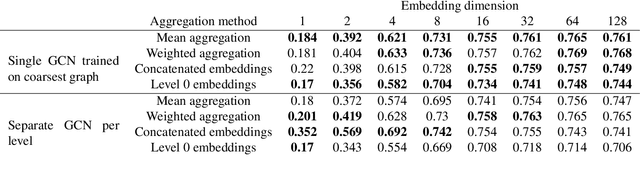
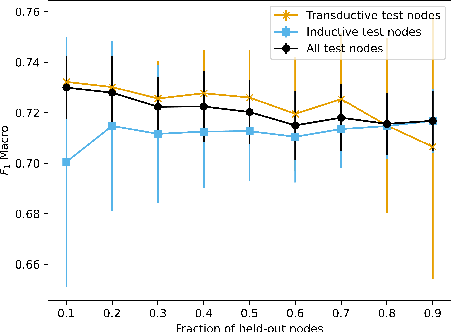
Graph convolutional networks (GCNs) allow us to learn topologically-aware node embeddings, which can be useful for classification or link prediction. However, by construction, they lack positional awareness and are unable to capture long-range dependencies without adding additional layers -- which in turn leads to over-smoothing and increased time and space complexity. Further, the complex dependencies between nodes make mini-batching challenging, limiting their applicability to large graphs. This paper proposes a Scalable Multi-resolution Graph Representation Learning (SMGRL) framework that enables us to learn multi-resolution node embeddings efficiently. Our framework is model-agnostic and can be applied to any existing GCN model. We dramatically reduce training costs by training only on a reduced-dimension coarsening of the original graph, then exploit self-similarity to apply the resulting algorithm at multiple resolutions. Inference of these multi-resolution embeddings can be distributed across multiple machines to reduce computational and memory requirements further. The resulting multi-resolution embeddings can be aggregated to yield high-quality node embeddings that capture both long- and short-range dependencies between nodes. Our experiments show that this leads to improved classification accuracy, without incurring high computational costs.