 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLGCN: An Ultra Efficient Graph Convolution Neural Model For 3D Point Cloud Analysis
Mar 31, 2023The analysis of 3D point clouds has diverse applications in robotics, vision and graphics. Processing them presents specific challenges since they are naturally sparse, can vary in spatial resolution and are typically unordered. Graph-based networks to abstract features have emerged as a promising alternative to convolutional neural networks for their analysis, but these can be computationally heavy as well as memory inefficient. To address these limitations we introduce a novel Multi-level Graph Convolution Neural (MLGCN) model, which uses Graph Neural Networks (GNN) blocks to extract features from 3D point clouds at specific locality levels. Our approach employs precomputed graph KNNs, where each KNN graph is shared between GCN blocks inside a GNN block, making it both efficient and effective compared to present models. We demonstrate the efficacy of our approach on point cloud based object classification and part segmentation tasks on benchmark datasets, showing that it produces comparable results to those of state-of-the-art models while requiring up to a thousand times fewer floating-point operations (FLOPs) and having significantly reduced storage requirements. Thus, our MLGCN model could be particular relevant to point cloud based 3D shape analysis in industrial applications when computing resources are scarce.
Contour Completion using Deep Structural Priors
Feb 09, 2023



Humans can easily perceive illusory contours and complete missing forms in fragmented shapes. This work investigates whether such capability can arise in convolutional neural networks (CNNs) using deep structural priors computed directly from images. In this work, we present a framework that completes disconnected contours and connects fragmented lines and curves. In our framework, we propose a model that does not even need to know which regions of the contour are eliminated. We introduce an iterative process that completes an incomplete image and we propose novel measures that guide this to find regions it needs to complete. Our model trains on a single image and fills in the contours with no additional training data. Our work builds a robust framework to achieve contour completion using deep structural priors and extensively investigate how such a model could be implemented.
RxRx1: A Dataset for Evaluating Experimental Batch Correction Methods
Jan 13, 2023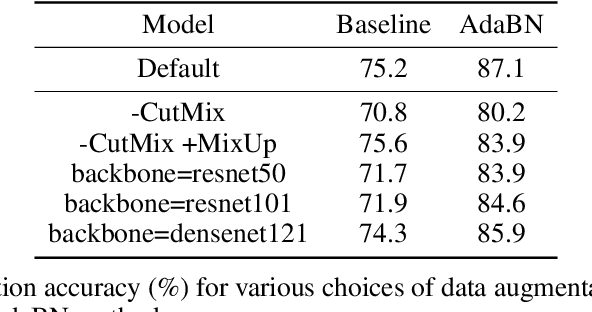



High-throughput screening techniques are commonly used to obtain large quantities of data in many fields of biology. It is well known that artifacts arising from variability in the technical execution of different experimental batches within such screens confound these observations and can lead to invalid biological conclusions. It is therefore necessary to account for these batch effects when analyzing outcomes. In this paper we describe RxRx1, a biological dataset designed specifically for the systematic study of batch effect correction methods. The dataset consists of 125,510 high-resolution fluorescence microscopy images of human cells under 1,138 genetic perturbations in 51 experimental batches across 4 cell types. Visual inspection of the images alone clearly demonstrates significant batch effects. We propose a classification task designed to evaluate the effectiveness of experimental batch correction methods on these images and examine the performance of a number of correction methods on this task. Our goal in releasing RxRx1 is to encourage the development of effective experimental batch correction methods that generalize well to unseen experimental batches. The dataset can be downloaded at https://rxrx.ai.
Medial Spectral Coordinates for 3D Shape Analysis
Nov 30, 2021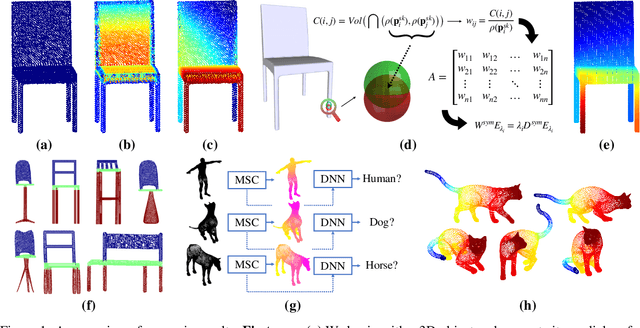
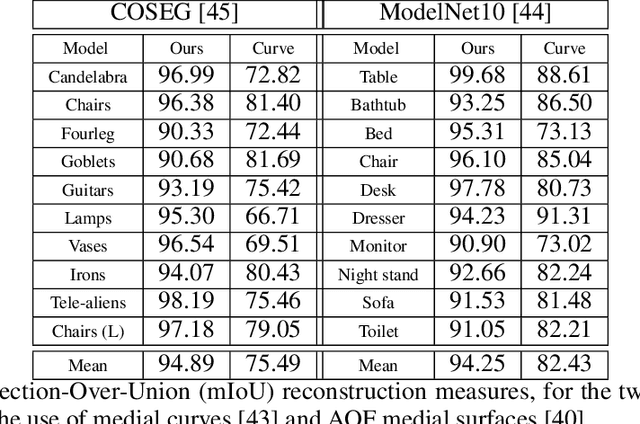
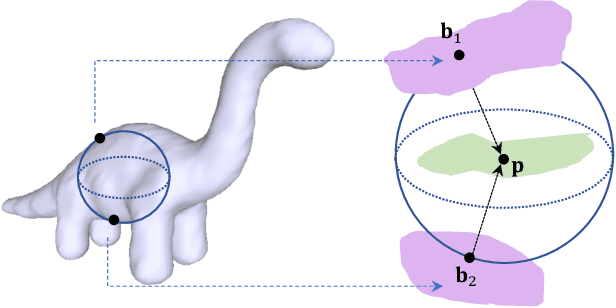
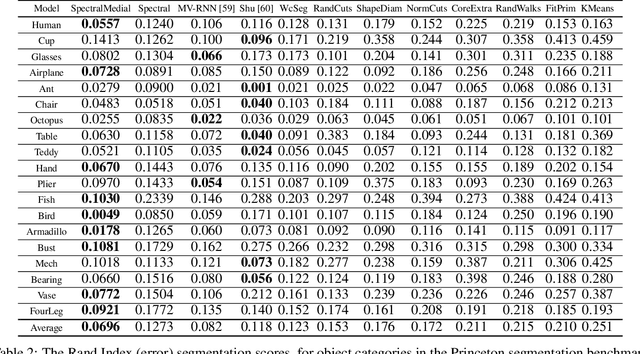
In recent years there has been a resurgence of interest in our community in the shape analysis of 3D objects represented by surface meshes, their voxelized interiors, or surface point clouds. In part, this interest has been stimulated by the increased availability of RGBD cameras, and by applications of computer vision to autonomous driving, medical imaging, and robotics. In these settings, spectral coordinates have shown promise for shape representation due to their ability to incorporate both local and global shape properties in a manner that is qualitatively invariant to isometric transformations. Yet, surprisingly, such coordinates have thus far typically considered only local surface positional or derivative information. In the present article, we propose to equip spectral coordinates with medial (object width) information, so as to enrich them. The key idea is to couple surface points that share a medial ball, via the weights of the adjacency matrix. We develop a spectral feature using this idea, and the algorithms to compute it. The incorporation of object width and medial coupling has direct benefits, as illustrated by our experiments on object classification, object part segmentation, and surface point correspondence.
Average Outward Flux Skeletons for Environment Mapping and Topology Matching
Nov 27, 2021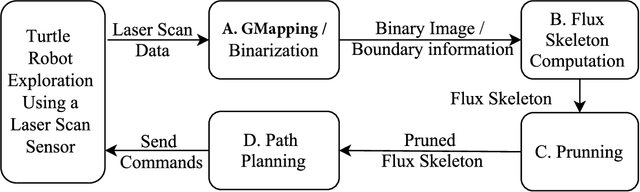
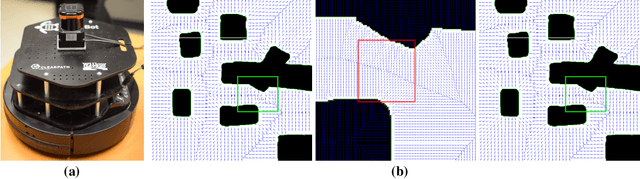
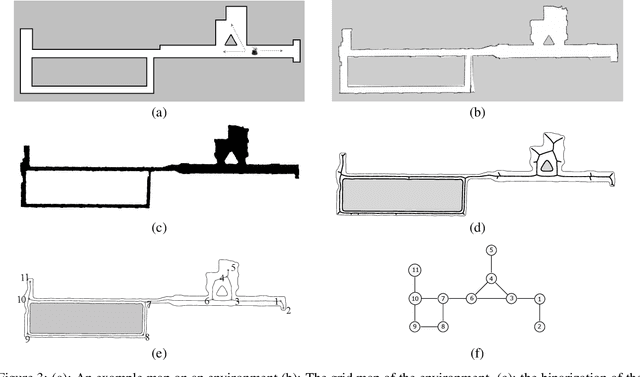
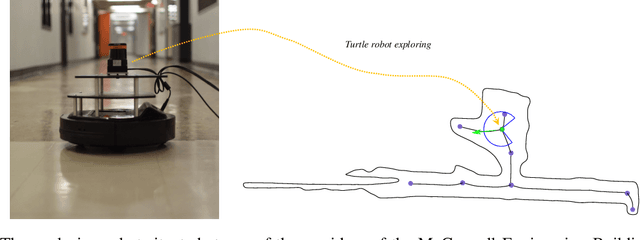
We consider how to directly extract a road map (also known as a topological representation) of an initially-unknown 2-dimensional environment via an online procedure that robustly computes a retraction of its boundaries. In this article, we first present the online construction of a topological map and the implementation of a control law for guiding the robot to the nearest unexplored area, first presented in [1]. The proposed method operates by allowing the robot to localize itself on a partially constructed map, calculate a path to unexplored parts of the environment (frontiers), compute a robust terminating condition when the robot has fully explored the environment, and achieve loop closure detection. The proposed algorithm results in smooth safe paths for the robot's navigation needs. The presented approach is any time algorithm that has the advantage that it allows for the active creation of topological maps from laser scan data, as it is being acquired. We also propose a navigation strategy based on a heuristic where the robot is directed towards nodes in the topological map that open to empty space. We then extend the work in [1] by presenting a topology matching algorithm that leverages the strengths of a particular spectral correspondence method [2], to match the mapped environments generated from our topology-making algorithm. Here, we concentrated on implementing a system that could be used to match the topologies of the mapped environment by using AOF Skeletons. In topology matching between two given maps and their AOF skeletons, we first find correspondences between points on the AOF skeletons of two different environments. We then align the (2D) points of the environments themselves. We also compute a distance measure between two given environments, based on their extracted AOF skeletons and their topology, as the sum of the matching errors between corresponding points.
Contour-guided Image Completion with Perceptual Grouping
Nov 22, 2021
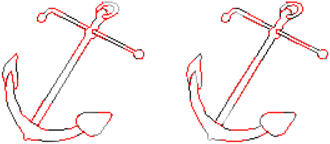

Humans are excellent at perceiving illusory outlines. We are readily able to complete contours, shapes, scenes, and even unseen objects when provided with images that contain broken fragments of a connected appearance. In vision science, this ability is largely explained by perceptual grouping: a foundational set of processes in human vision that describes how separated elements can be grouped. In this paper, we revisit an algorithm called Stochastic Completion Fields (SCFs) that mechanizes a set of such processes -- good continuity, closure, and proximity -- through contour completion. This paper implements a modernized model of the SCF algorithm, and uses it in an image editing framework where we propose novel methods to complete fragmented contours. We show how the SCF algorithm plausibly mimics results in human perception. We use the SCF completed contours as guides for inpainting, and show that our guides improve the performance of state-of-the-art models. Additionally, we show that the SCF aids in finding edges in high-noise environments. Overall, our described algorithms resemble an important mechanism in the human visual system, and offer a novel framework that modern computer vision models can benefit from.
Appearance Shock Grammar for Fast Medial Axis Extraction from Real Images
Apr 06, 2020

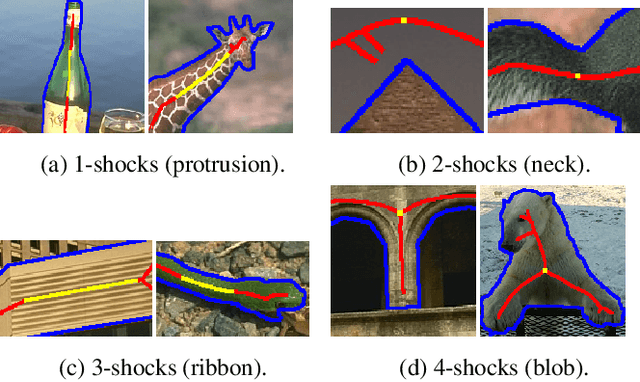
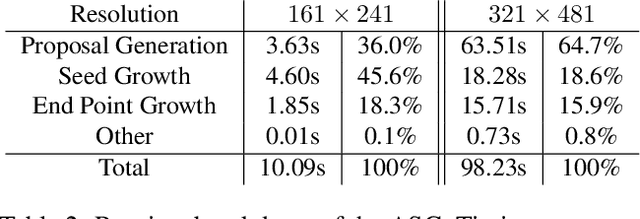
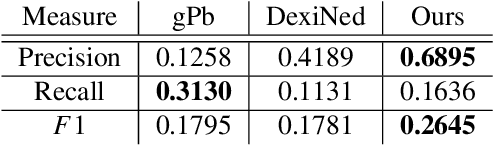
We combine ideas from shock graph theory with more recent appearance-based methods for medial axis extraction from complex natural scenes, improving upon the present best unsupervised method, in terms of efficiency and performance. We make the following specific contributions: i) we extend the shock graph representation to the domain of real images, by generalizing the shock type definitions using local, appearance-based criteria; ii) we then use the rules of a Shock Grammar to guide our search for medial points, drastically reducing run time when compared to other methods, which exhaustively consider all points in the input image;iii) we remove the need for typical post-processing steps including thinning, non-maximum suppression, and grouping, by adhering to the Shock Grammar rules while deriving the medial axis solution; iv) finally, we raise some fundamental concerns with the evaluation scheme used in previous work and propose a more appropriate alternative for assessing the performance of medial axis extraction from scenes. Our experiments on the BMAX500 and SK-LARGE datasets demonstrate the effectiveness of our approach. We outperform the present state-of-the-art, excelling particularly in the high-precision regime, while running an order of magnitude faster and requiring no post-processing.
Scene Categorization from Contours: Medial Axis Based Salience Measures
Nov 26, 2018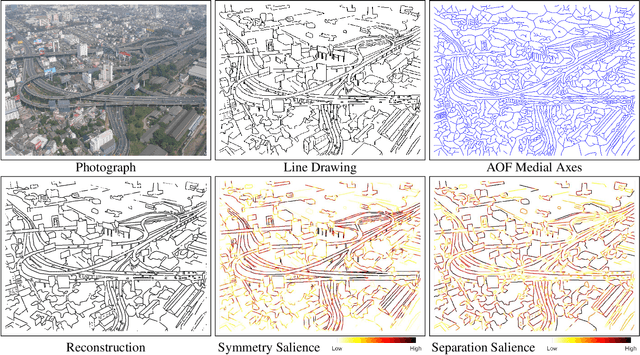

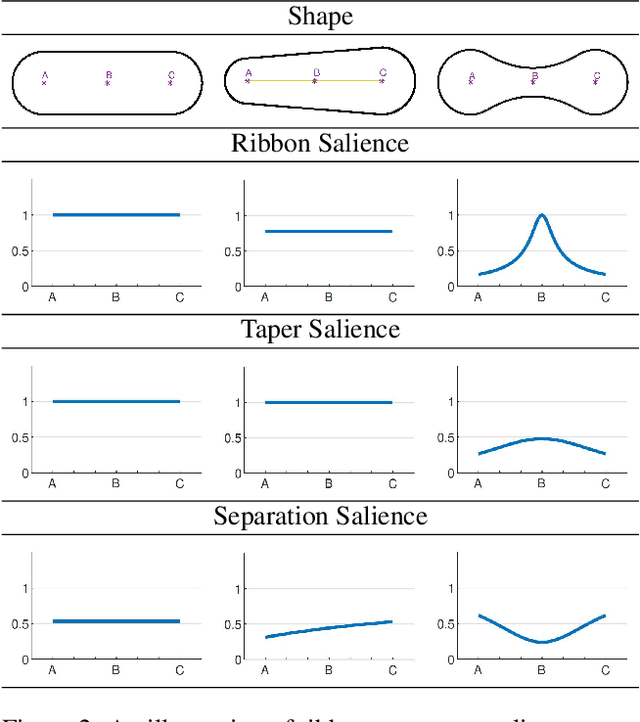

The computer vision community has witnessed recent advances in scene categorization from images, with the state-of-the art systems now achieving impressive recognition rates on challenging benchmarks such as the Places365 dataset. Such systems have been trained on photographs which include color, texture and shading cues. The geometry of shapes and surfaces, as conveyed by scene contours, is not explicitly considered for this task. Remarkably, humans can accurately recognize natural scenes from line drawings, which consist solely of contour-based shape cues. Here we report the first computer vision study on scene categorization of line drawings derived from popular databases including an artist scene database, MIT67, and Places365. Specifically, we use off-the-shelf pre-trained CNNs to perform scene classification given only contour information as input and find performance levels well above chance. We also show that medial-axis based contour salience methods can be used to select more informative subsets of contour pixels and that the variation in CNN classification performance on various choices for these subsets is qualitatively similar to that observed in human performance. Moreover, when the salience measures are used to weight the contours, as opposed to pruning them, we find that these weights boost our CNN performance above that for unweighted contour input. That is, the medial axis based salience weights appear to add useful information that is not available when CNNs are trained to use contours alone.