 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater Dense Mapping with the First Compact 3D Sonar
Oct 21, 2025In the past decade, the adoption of compact 3D range sensors, such as LiDARs, has driven the developments of robust state-estimation pipelines, making them a standard sensor for aerial, ground, and space autonomy. Unfortunately, poor propagation of electromagnetic waves underwater, has limited the visibility-independent sensing options of underwater state-estimation to acoustic range sensors, which provide 2D information including, at-best, spatially ambiguous information. This paper, to the best of our knowledge, is the first study examining the performance, capacity, and opportunities arising from the recent introduction of the first compact 3D sonar. Towards that purpose, we introduce calibration procedures for extracting the extrinsics between the 3D sonar and a camera and we provide a study on acoustic response in different surfaces and materials. Moreover, we provide novel mapping and SLAM pipelines tested in deployments in underwater cave systems and other geometrically and acoustically challenging underwater environments. Our assessment showcases the unique capacity of 3D sonars to capture consistent spatial information allowing for detailed reconstructions and localization in datasets expanding to hundreds of meters. At the same time it highlights remaining challenges related to acoustic propagation, as found also in other acoustic sensors. Datasets collected for our evaluations would be released and shared with the community to enable further research advancements.
Mapping the Catacombs: An Underwater Cave Segment of the Devil's Eye System
Jul 08, 2025



This paper presents a framework for mapping underwater caves. Underwater caves are crucial for fresh water resource management, underwater archaeology, and hydrogeology. Mapping the cave's outline and dimensions, as well as creating photorealistic 3D maps, is critical for enabling a better understanding of this underwater domain. In this paper, we present the mapping of an underwater cave segment (the catacombs) of the Devil's Eye cave system at Ginnie Springs, FL. We utilized a set of inexpensive action cameras in conjunction with a dive computer to estimate the trajectories of the cameras together with a sparse point cloud. The resulting reconstructions are utilized to produce a one-dimensional retract of the cave passages in the form of the average trajectory together with the boundaries (top, bottom, left, and right). The use of the dive computer enables the observability of the z-dimension in addition to the roll and pitch in a visual/inertial framework (SVIn2). In addition, the keyframes generated by SVIn2 together with the estimated camera poses for select areas are used as input to a global optimization (bundle adjustment) framework -- COLMAP -- in order to produce a dense reconstruction of those areas. The same cave segment is manually surveyed using the MNemo V2 instrument, providing an additional set of measurements validating the proposed approach. It is worth noting that with the use of action cameras, the primary components of a cave map can be constructed. Furthermore, with the utilization of a global optimization framework guided by the results of VI-SLAM package SVIn2, photorealistic dense 3D representations of selected areas can be reconstructed.
Demonstrating CavePI: Autonomous Exploration of Underwater Caves by Semantic Guidance
Feb 07, 2025Enabling autonomous robots to safely and efficiently navigate, explore, and map underwater caves is of significant importance to water resource management, hydrogeology, archaeology, and marine robotics. In this work, we demonstrate the system design and algorithmic integration of a visual servoing framework for semantically guided autonomous underwater cave exploration. We present the hardware and edge-AI design considerations to deploy this framework on a novel AUV (Autonomous Underwater Vehicle) named CavePI. The guided navigation is driven by a computationally light yet robust deep visual perception module, delivering a rich semantic understanding of the environment. Subsequently, a robust control mechanism enables CavePI to track the semantic guides and navigate within complex cave structures. We evaluate the system through field experiments in natural underwater caves and spring-water sites and further validate its ROS (Robot Operating System)-based digital twin in a simulation environment. Our results highlight how these integrated design choices facilitate reliable navigation under feature-deprived, GPS-denied, and low-visibility conditions.
AquaFuse: Waterbody Fusion for Physics Guided View Synthesis of Underwater Scenes
Nov 02, 2024We introduce the idea of AquaFuse, a physics-based method for synthesizing waterbody properties in underwater imagery. We formulate a closed-form solution for waterbody fusion that facilitates realistic data augmentation and geometrically consistent underwater scene rendering. AquaFuse leverages the physical characteristics of light propagation underwater to synthesize the waterbody from one scene to the object contents of another. Unlike data-driven style transfer, AquaFuse preserves the depth consistency and object geometry in an input scene. We validate this unique feature by comprehensive experiments over diverse underwater scenes. We find that the AquaFused images preserve over 94% depth consistency and 90-95% structural similarity of the input scenes. We also demonstrate that it generates accurate 3D view synthesis by preserving object geometry while adapting to the inherent waterbody fusion process. AquaFuse opens up a new research direction in data augmentation by geometry-preserving style transfer for underwater imaging and robot vision applications.
Enhancing Visual Inertial SLAM with Magnetic Measurements
Sep 16, 2024This paper presents an extension to visual inertial odometry (VIO) by introducing tightly-coupled fusion of magnetometer measurements. A sliding window of keyframes is optimized by minimizing re-projection errors, relative inertial errors, and relative magnetometer orientation errors. The results of IMU orientation propagation are used to efficiently transform magnetometer measurements between frames producing relative orientation constraints between consecutive frames. The soft and hard iron effects are calibrated using an ellipsoid fitting algorithm. The introduction of magnetometer data results in significant reductions in the orientation error and also in recovery of the true yaw orientation with respect to the magnetic north. The proposed framework operates in all environments with slow-varying magnetic fields, mainly outdoors and underwater. We have focused our work on the underwater domain, especially in underwater caves, as the narrow passage and turbulent flow make it difficult to perform loop closures and reset the localization drift. The underwater caves present challenges to VIO due to the absence of ambient light and the confined nature of the environment, while also being a crucial source of fresh water and providing valuable historical records. Experimental results from underwater caves demonstrate the improvements in accuracy and robustness introduced by the proposed VIO extension.
ODYSSEE: Oyster Detection Yielded by Sensor Systems on Edge Electronics
Sep 11, 2024
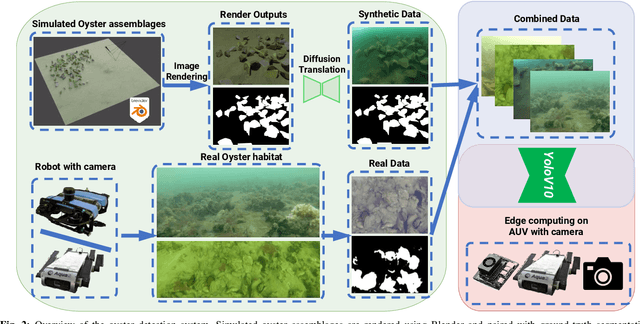

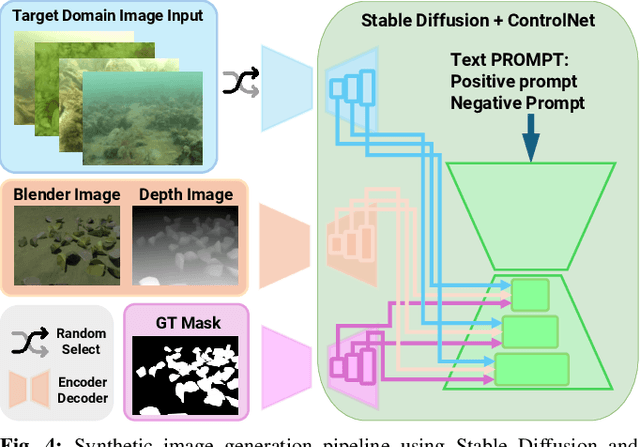
Oysters are a keystone species in coastal ecosystems, offering significant economic, environmental, and cultural benefits. However, current monitoring systems are often destructive, typically involving dredging to physically collect and count oysters. A nondestructive alternative is manual identification from video footage collected by divers, which is time-consuming and labor-intensive with expert input. An alternative to human monitoring is the deployment of a system with trained object detection models that performs real-time, on edge oyster detection in the field. One such platform is the Aqua2 robot. Effective training of these models requires extensive high-quality data, which is difficult to obtain in marine settings. To address these complications, we introduce a novel method that leverages stable diffusion to generate high-quality synthetic data for the marine domain. We exploit diffusion models to create photorealistic marine imagery, using ControlNet inputs to ensure consistency with the segmentation ground-truth mask, the geometry of the scene, and the target domain of real underwater images for oysters. The resulting dataset is used to train a YOLOv10-based vision model, achieving a state-of-the-art 0.657 mAP@50 for oyster detection on the Aqua2 platform. The system we introduce not only improves oyster habitat monitoring, but also paves the way to autonomous surveillance for various tasks in marine contexts, improving aquaculture and conservation efforts.
Ego-to-Exo: Interfacing Third Person Visuals from Egocentric Views in Real-time for Improved ROV Teleoperation
Jun 30, 2024



Underwater ROVs (Remotely Operated Vehicles) are unmanned submersible vehicles designed for exploring and operating in the depths of the ocean. Despite using high-end cameras, typical teleoperation engines based on first-person (egocentric) views limit a surface operator's ability to maneuver and navigate the ROV in complex deep-water missions. In this paper, we present an interactive teleoperation interface that (i) offers on-demand "third"-person (exocentric) visuals from past egocentric views, and (ii) facilitates enhanced peripheral information with augmented ROV pose in real-time. We achieve this by integrating a 3D geometry-based Ego-to-Exo view synthesis algorithm into a monocular SLAM system for accurate trajectory estimation. The proposed closed-form solution only uses past egocentric views from the ROV and a SLAM backbone for pose estimation, which makes it portable to existing ROV platforms. Unlike data-driven solutions, it is invariant to applications and waterbody-specific scenes. We validate the geometric accuracy of the proposed framework through extensive experiments of 2-DOF indoor navigation and 6-DOF underwater cave exploration in challenging low-light conditions. We demonstrate the benefits of dynamic Ego-to-Exo view generation and real-time pose rendering for remote ROV teleoperation by following navigation guides such as cavelines inside underwater caves. This new way of interactive ROV teleoperation opens up promising opportunities for future research in underwater telerobotics.
Real-Time Dense 3D Mapping of Underwater Environments
Apr 05, 2023



This paper addresses real-time dense 3D reconstruction for a resource-constrained Autonomous Underwater Vehicle (AUV). Underwater vision-guided operations are among the most challenging as they combine 3D motion in the presence of external forces, limited visibility, and absence of global positioning. Obstacle avoidance and effective path planning require online dense reconstructions of the environment. Autonomous operation is central to environmental monitoring, marine archaeology, resource utilization, and underwater cave exploration. To address this problem, we propose to use SVIn2, a robust VIO method, together with a real-time 3D reconstruction pipeline. We provide extensive evaluation on four challenging underwater datasets. Our pipeline produces comparable reconstruction with that of COLMAP, the state-of-the-art offline 3D reconstruction method, at high frame rates on a single CPU.
SM/VIO: Robust Underwater State Estimation Switching Between Model-based and Visual Inertial Odometry
Apr 04, 2023This paper addresses the robustness problem of visual-inertial state estimation for underwater operations. Underwater robots operating in a challenging environment are required to know their pose at all times. All vision-based localization schemes are prone to failure due to poor visibility conditions, color loss, and lack of features. The proposed approach utilizes a model of the robot's kinematics together with proprioceptive sensors to maintain the pose estimate during visual-inertial odometry (VIO) failures. Furthermore, the trajectories from successful VIO and the ones from the model-driven odometry are integrated in a coherent set that maintains a consistent pose at all times. Health-monitoring tracks the VIO process ensuring timely switches between the two estimators. Finally, loop closure is implemented on the overall trajectory. The resulting framework is a robust estimator switching between model-based and visual-inertial odometry (SM/VIO). Experimental results from numerous deployments of the Aqua2 vehicle demonstrate the robustness of our approach over coral reefs and a shipwreck.
Weakly Supervised Caveline Detection For AUV Navigation Inside Underwater Caves
Mar 07, 2023Underwater caves are challenging environments that are crucial for water resource management, and for our understanding of hydro-geology and history. Mapping underwater caves is a time-consuming, labor-intensive, and hazardous operation. For autonomous cave mapping by underwater robots, the major challenge lies in vision-based estimation in the complete absence of ambient light, which results in constantly moving shadows due to the motion of the camera-light setup. Thus, detecting and following the caveline as navigation guidance is paramount for robots in autonomous cave mapping missions. In this paper, we present a computationally light caveline detection model based on a novel Vision Transformer (ViT)-based learning pipeline. We address the problem of scarce annotated training data by a weakly supervised formulation where the learning is reinforced through a series of noisy predictions from intermediate sub-optimal models. We validate the utility and effectiveness of such weak supervision for caveline detection and tracking in three different cave locations: USA, Mexico, and Spain. Experimental results demonstrate that our proposed model, CL-ViT, balances the robustness-efficiency trade-off, ensuring good generalization performance while offering 10+ FPS on single-board (Jetson TX2) devices.