 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatlak Parametric Image Estimation from Dynamic PET Using Diffusion Model Prior
Dec 22, 2025Dynamic PET enables the quantitative estimation of physiology-related parameters and is widely utilized in research and increasingly adopted in clinical settings. Parametric imaging in dynamic PET requires kinetic modeling to estimate voxel-wise physiological parameters based on specific kinetic models. However, parametric images estimated through kinetic model fitting often suffer from low image quality due to the inherently ill-posed nature of the fitting process and the limited counts resulting from non-continuous data acquisition across multiple bed positions in whole-body PET. In this work, we proposed a diffusion model-based kinetic modeling framework for parametric image estimation, using the Patlak model as an example. The score function of the diffusion model was pre-trained on static total-body PET images and served as a prior for both Patlak slope and intercept images by leveraging their patch-wise similarity. During inference, the kinetic model was incorporated as a data-consistency constraint to guide the parametric image estimation. The proposed framework was evaluated on total-body dynamic PET datasets with different dose levels, demonstrating the feasibility and promising performance of the proposed framework in improving parametric image quality.
CDPDNet: Integrating Text Guidance with Hybrid Vision Encoders for Medical Image Segmentation
May 25, 2025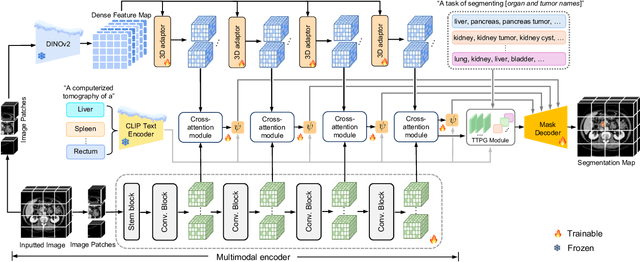



Most publicly available medical segmentation datasets are only partially labeled, with annotations provided for a subset of anatomical structures. When multiple datasets are combined for training, this incomplete annotation poses challenges, as it limits the model's ability to learn shared anatomical representations among datasets. Furthermore, vision-only frameworks often fail to capture complex anatomical relationships and task-specific distinctions, leading to reduced segmentation accuracy and poor generalizability to unseen datasets. In this study, we proposed a novel CLIP-DINO Prompt-Driven Segmentation Network (CDPDNet), which combined a self-supervised vision transformer with CLIP-based text embedding and introduced task-specific text prompts to tackle these challenges. Specifically, the framework was constructed upon a convolutional neural network (CNN) and incorporated DINOv2 to extract both fine-grained and global visual features, which were then fused using a multi-head cross-attention module to overcome the limited long-range modeling capability of CNNs. In addition, CLIP-derived text embeddings were projected into the visual space to help model complex relationships among organs and tumors. To further address the partial label challenge and enhance inter-task discriminative capability, a Text-based Task Prompt Generation (TTPG) module that generated task-specific prompts was designed to guide the segmentation. Extensive experiments on multiple medical imaging datasets demonstrated that CDPDNet consistently outperformed existing state-of-the-art segmentation methods. Code and pretrained model are available at: https://github.com/wujiong-hub/CDPDNet.git.
PET Image Denoising via Text-Guided Diffusion: Integrating Anatomical Priors through Text Prompts
Feb 28, 2025Low-dose Positron Emission Tomography (PET) imaging presents a significant challenge due to increased noise and reduced image quality, which can compromise its diagnostic accuracy and clinical utility. Denoising diffusion probabilistic models (DDPMs) have demonstrated promising performance for PET image denoising. However, existing DDPM-based methods typically overlook valuable metadata such as patient demographics, anatomical information, and scanning parameters, which should further enhance the denoising performance if considered. Recent advances in vision-language models (VLMs), particularly the pre-trained Contrastive Language-Image Pre-training (CLIP) model, have highlighted the potential of incorporating text-based information into visual tasks to improve downstream performance. In this preliminary study, we proposed a novel text-guided DDPM for PET image denoising that integrated anatomical priors through text prompts. Anatomical text descriptions were encoded using a pre-trained CLIP text encoder to extract semantic guidance, which was then incorporated into the diffusion process via the cross-attention mechanism. Evaluations based on paired 1/20 low-dose and normal-dose 18F-FDG PET datasets demonstrated that the proposed method achieved better quantitative performance than conventional UNet and standard DDPM methods at both the whole-body and organ levels. These results underscored the potential of leveraging VLMs to integrate rich metadata into the diffusion framework to enhance the image quality of low-dose PET scans.
Adaptive Whole-Body PET Image Denoising Using 3D Diffusion Models with ControlNet
Nov 08, 2024


Positron Emission Tomography (PET) is a vital imaging modality widely used in clinical diagnosis and preclinical research but faces limitations in image resolution and signal-to-noise ratio due to inherent physical degradation factors. Current deep learning-based denoising methods face challenges in adapting to the variability of clinical settings, influenced by factors such as scanner types, tracer choices, dose levels, and acquisition times. In this work, we proposed a novel 3D ControlNet-based denoising method for whole-body PET imaging. We first pre-trained a 3D Denoising Diffusion Probabilistic Model (DDPM) using a large dataset of high-quality normal-dose PET images. Following this, we fine-tuned the model on a smaller set of paired low- and normal-dose PET images, integrating low-dose inputs through a 3D ControlNet architecture, thereby making the model adaptable to denoising tasks in diverse clinical settings. Experimental results based on clinical PET datasets show that the proposed framework outperformed other state-of-the-art PET image denoising methods both in visual quality and quantitative metrics. This plug-and-play approach allows large diffusion models to be fine-tuned and adapted to PET images from diverse acquisition protocols.
Weakly Supervised Caveline Detection For AUV Navigation Inside Underwater Caves
Mar 07, 2023Underwater caves are challenging environments that are crucial for water resource management, and for our understanding of hydro-geology and history. Mapping underwater caves is a time-consuming, labor-intensive, and hazardous operation. For autonomous cave mapping by underwater robots, the major challenge lies in vision-based estimation in the complete absence of ambient light, which results in constantly moving shadows due to the motion of the camera-light setup. Thus, detecting and following the caveline as navigation guidance is paramount for robots in autonomous cave mapping missions. In this paper, we present a computationally light caveline detection model based on a novel Vision Transformer (ViT)-based learning pipeline. We address the problem of scarce annotated training data by a weakly supervised formulation where the learning is reinforced through a series of noisy predictions from intermediate sub-optimal models. We validate the utility and effectiveness of such weak supervision for caveline detection and tracking in three different cave locations: USA, Mexico, and Spain. Experimental results demonstrate that our proposed model, CL-ViT, balances the robustness-efficiency trade-off, ensuring good generalization performance while offering 10+ FPS on single-board (Jetson TX2) devices.
UDepth: Fast Monocular Depth Estimation for Visually-guided Underwater Robots
Sep 26, 2022

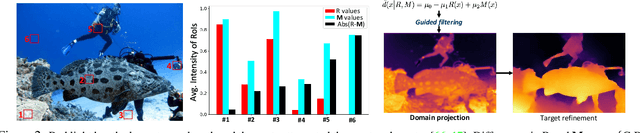

In this paper, we present a fast monocular depth estimation method for enabling 3D perception capabilities of low-cost underwater robots. We formulate a novel end-to-end deep visual learning pipeline named UDepth, which incorporates domain knowledge of image formation characteristics of natural underwater scenes. First, we adapt a new input space from raw RGB image space by exploiting underwater light attenuation prior, and then devise a least-squared formulation for coarse pixel-wise depth prediction. Subsequently, we extend this into a domain projection loss that guides the end-to-end learning of UDepth on over 9K RGB-D training samples. UDepth is designed with a computationally light MobileNetV2 backbone and a Transformer-based optimizer for ensuring fast inference rates on embedded systems. By domain-aware design choices and through comprehensive experimental analyses, we demonstrate that it is possible to achieve state-of-the-art depth estimation performance while ensuring a small computational footprint. Specifically, with 70%-80% less network parameters than existing benchmarks, UDepth achieves comparable and often better depth estimation performance. While the full model offers over 66 FPS (13 FPS) inference rates on a single GPU (CPU core), our domain projection for coarse depth prediction runs at 51.5 FPS rates on single-board NVIDIA Jetson TX2s. The inference pipelines are available at https://github.com/uf-robopi/UDepth.