 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVL-SAM2: A unified 3D medical vision-language model for multimodal reasoning and prompt-driven segmentation
Jan 14, 2026Recent progress in medical vision-language models (VLMs) has achieved strong performance on image-level text-centric tasks such as report generation and visual question answering (VQA). However, achieving fine-grained visual grounding and volumetric spatial reasoning in 3D medical VLMs remains challenging, particularly when aiming to unify these capabilities within a single, generalizable framework. To address this challenge, we proposed MedVL-SAM2, a unified 3D medical multimodal model that concurrently supports report generation, VQA, and multi-paradigm segmentation, including semantic, referring, and interactive segmentation. MedVL-SAM2 integrates image-level reasoning and pixel-level perception through a cohesive architecture tailored for 3D medical imaging, and incorporates a SAM2-based volumetric segmentation module to enable precise multi-granular spatial reasoning. The model is trained in a multi-stage pipeline: it is first pre-trained on a large-scale corpus of 3D CT image-text pairs to align volumetric visual features with radiology-language embeddings. It is then jointly optimized with both language-understanding and segmentation objectives using a comprehensive 3D CT segmentation dataset. This joint training enables flexible interaction via language, point, or box prompts, thereby unifying high-level visual reasoning with spatially precise localization. Our unified architecture delivers state-of-the-art performance across report generation, VQA, and multiple 3D segmentation tasks. Extensive analyses further show that the model provides reliable 3D visual grounding, controllable interactive segmentation, and robust cross-modal reasoning, demonstrating that high-level semantic reasoning and precise 3D localization can be jointly achieved within a unified 3D medical VLM.
SAM2-SGP: Enhancing SAM2 for Medical Image Segmentation via Support-Set Guided Prompting
Jun 24, 2025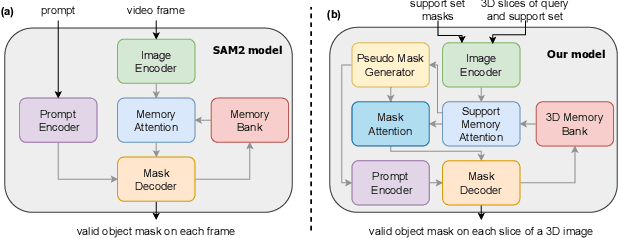



Although new vision foundation models such as Segment Anything Model 2 (SAM2) have significantly enhanced zero-shot image segmentation capabilities, reliance on human-provided prompts poses significant challenges in adapting SAM2 to medical image segmentation tasks. Moreover, SAM2's performance in medical image segmentation was limited by the domain shift issue, since it was originally trained on natural images and videos. To address these challenges, we proposed SAM2 with support-set guided prompting (SAM2-SGP), a framework that eliminated the need for manual prompts. The proposed model leveraged the memory mechanism of SAM2 to generate pseudo-masks using image-mask pairs from a support set via a Pseudo-mask Generation (PMG) module. We further introduced a novel Pseudo-mask Attention (PMA) module, which used these pseudo-masks to automatically generate bounding boxes and enhance localized feature extraction by guiding attention to relevant areas. Furthermore, a low-rank adaptation (LoRA) strategy was adopted to mitigate the domain shift issue. The proposed framework was evaluated on both 2D and 3D datasets across multiple medical imaging modalities, including fundus photography, X-ray, computed tomography (CT), magnetic resonance imaging (MRI), positron emission tomography (PET), and ultrasound. The results demonstrated a significant performance improvement over state-of-the-art models, such as nnUNet and SwinUNet, as well as foundation models, such as SAM2 and MedSAM2, underscoring the effectiveness of the proposed approach. Our code is publicly available at https://github.com/astlian9/SAM_Support.
CDPDNet: Integrating Text Guidance with Hybrid Vision Encoders for Medical Image Segmentation
May 25, 2025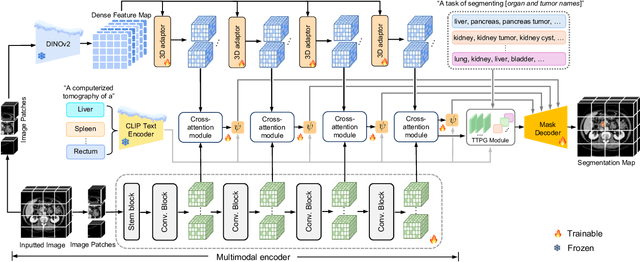



Most publicly available medical segmentation datasets are only partially labeled, with annotations provided for a subset of anatomical structures. When multiple datasets are combined for training, this incomplete annotation poses challenges, as it limits the model's ability to learn shared anatomical representations among datasets. Furthermore, vision-only frameworks often fail to capture complex anatomical relationships and task-specific distinctions, leading to reduced segmentation accuracy and poor generalizability to unseen datasets. In this study, we proposed a novel CLIP-DINO Prompt-Driven Segmentation Network (CDPDNet), which combined a self-supervised vision transformer with CLIP-based text embedding and introduced task-specific text prompts to tackle these challenges. Specifically, the framework was constructed upon a convolutional neural network (CNN) and incorporated DINOv2 to extract both fine-grained and global visual features, which were then fused using a multi-head cross-attention module to overcome the limited long-range modeling capability of CNNs. In addition, CLIP-derived text embeddings were projected into the visual space to help model complex relationships among organs and tumors. To further address the partial label challenge and enhance inter-task discriminative capability, a Text-based Task Prompt Generation (TTPG) module that generated task-specific prompts was designed to guide the segmentation. Extensive experiments on multiple medical imaging datasets demonstrated that CDPDNet consistently outperformed existing state-of-the-art segmentation methods. Code and pretrained model are available at: https://github.com/wujiong-hub/CDPDNet.git.
PET Image Denoising via Text-Guided Diffusion: Integrating Anatomical Priors through Text Prompts
Feb 28, 2025Low-dose Positron Emission Tomography (PET) imaging presents a significant challenge due to increased noise and reduced image quality, which can compromise its diagnostic accuracy and clinical utility. Denoising diffusion probabilistic models (DDPMs) have demonstrated promising performance for PET image denoising. However, existing DDPM-based methods typically overlook valuable metadata such as patient demographics, anatomical information, and scanning parameters, which should further enhance the denoising performance if considered. Recent advances in vision-language models (VLMs), particularly the pre-trained Contrastive Language-Image Pre-training (CLIP) model, have highlighted the potential of incorporating text-based information into visual tasks to improve downstream performance. In this preliminary study, we proposed a novel text-guided DDPM for PET image denoising that integrated anatomical priors through text prompts. Anatomical text descriptions were encoded using a pre-trained CLIP text encoder to extract semantic guidance, which was then incorporated into the diffusion process via the cross-attention mechanism. Evaluations based on paired 1/20 low-dose and normal-dose 18F-FDG PET datasets demonstrated that the proposed method achieved better quantitative performance than conventional UNet and standard DDPM methods at both the whole-body and organ levels. These results underscored the potential of leveraging VLMs to integrate rich metadata into the diffusion framework to enhance the image quality of low-dose PET scans.
LDM-Morph: Latent diffusion model guided deformable image registration
Nov 23, 2024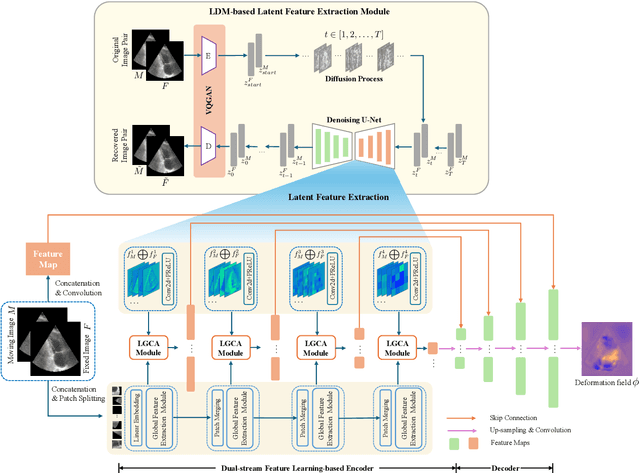
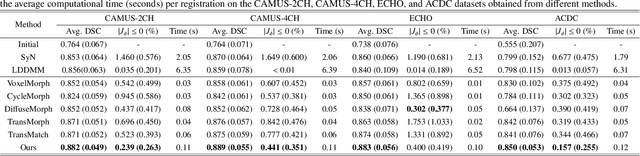
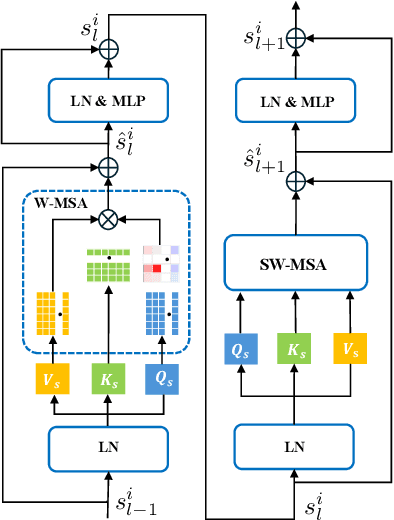
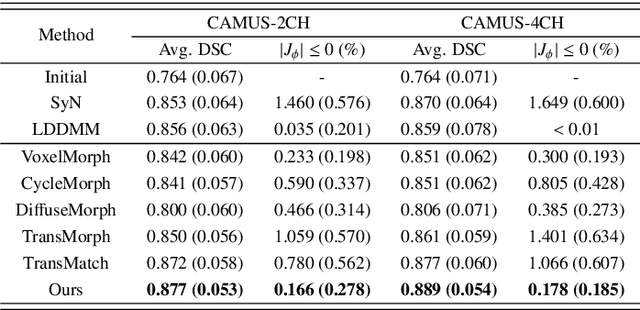
Deformable image registration plays an essential role in various medical image tasks. Existing deep learning-based deformable registration frameworks primarily utilize convolutional neural networks (CNNs) or Transformers to learn features to predict the deformations. However, the lack of semantic information in the learned features limits the registration performance. Furthermore, the similarity metric of the loss function is often evaluated only in the pixel space, which ignores the matching of high-level anatomical features and can lead to deformation folding. To address these issues, in this work, we proposed LDM-Morph, an unsupervised deformable registration algorithm for medical image registration. LDM-Morph integrated features extracted from the latent diffusion model (LDM) to enrich the semantic information. Additionally, a latent and global feature-based cross-attention module (LGCA) was designed to enhance the interaction of semantic information from LDM and global information from multi-head self-attention operations. Finally, a hierarchical metric was proposed to evaluate the similarity of image pairs in both the original pixel space and latent-feature space, enhancing topology preservation while improving registration accuracy. Extensive experiments on four public 2D cardiac image datasets show that the proposed LDM-Morph framework outperformed existing state-of-the-art CNNs- and Transformers-based registration methods regarding accuracy and topology preservation with comparable computational efficiency. Our code is publicly available at https://github.com/wujiong-hub/LDM-Morph.
DiffOp-net: A Differential Operator-based Fully Convolutional Network for Unsupervised Deformable Image Registration
Apr 05, 2024


Existing unsupervised deformable image registration methods usually rely on metrics applied to the gradients of predicted displacement or velocity fields as a regularization term to ensure transformation smoothness, which potentially limits registration accuracy. In this study, we propose a novel approach to enhance unsupervised deformable image registration by introducing a new differential operator into the registration framework. This operator, acting on the velocity field and mapping it to a dual space, ensures the smoothness of the velocity field during optimization, facilitating accurate deformable registration. In addition, to tackle the challenge of capturing large deformations inside image pairs, we introduce a Cross-Coordinate Attention module (CCA) and embed it into a proposed Fully Convolutional Networks (FCNs)-based multi-resolution registration architecture. Evaluation experiments are conducted on two magnetic resonance imaging (MRI) datasets. Compared to various state-of-the-art registration approaches, including a traditional algorithm and three representative unsupervised learning-based methods, our method achieves superior accuracies, maintaining desirable diffeomorphic properties, and exhibiting promising registration speed.
HNAS-reg: hierarchical neural architecture search for deformable medical image registration
Aug 23, 2023Convolutional neural networks (CNNs) have been widely used to build deep learning models for medical image registration, but manually designed network architectures are not necessarily optimal. This paper presents a hierarchical NAS framework (HNAS-Reg), consisting of both convolutional operation search and network topology search, to identify the optimal network architecture for deformable medical image registration. To mitigate the computational overhead and memory constraints, a partial channel strategy is utilized without losing optimization quality. Experiments on three datasets, consisting of 636 T1-weighted magnetic resonance images (MRIs), have demonstrated that the proposal method can build a deep learning model with improved image registration accuracy and reduced model size, compared with state-of-the-art image registration approaches, including one representative traditional approach and two unsupervised learning-based approaches.
BSDA-Net: A Boundary Shape and Distance Aware Joint Learning Framework for Segmenting and Classifying OCTA Images
Jul 13, 2021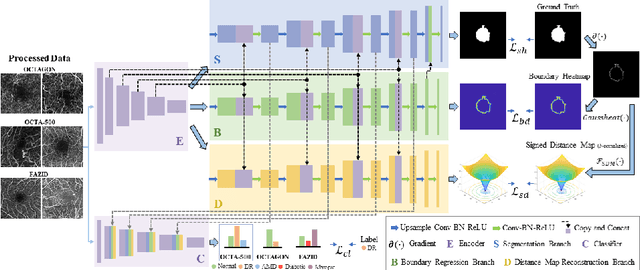

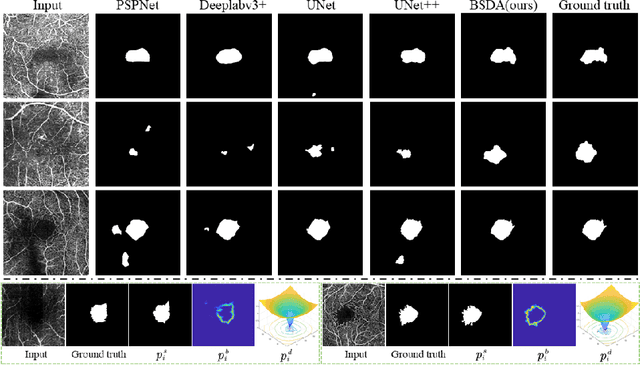
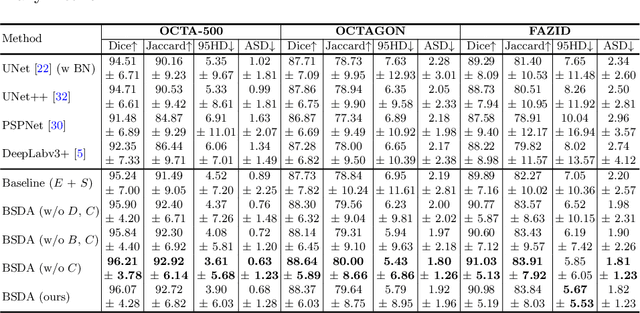
Optical coherence tomography angiography (OCTA) is a novel non-invasive imaging technique that allows visualizations of vasculature and foveal avascular zone (FAZ) across retinal layers. Clinical researches suggest that the morphology and contour irregularity of FAZ are important biomarkers of various ocular pathologies. Therefore, precise segmentation of FAZ has great clinical interest. Also, there is no existing research reporting that FAZ features can improve the performance of deep diagnostic classification networks. In this paper, we propose a novel multi-level boundary shape and distance aware joint learning framework, named BSDA-Net, for FAZ segmentation and diagnostic classification from OCTA images. Two auxiliary branches, namely boundary heatmap regression and signed distance map reconstruction branches, are constructed in addition to the segmentation branch to improve the segmentation performance, resulting in more accurate FAZ contours and fewer outliers. Moreover, both low-level and high-level features from the aforementioned three branches, including shape, size, boundary, and signed directional distance map of FAZ, are fused hierarchically with features from the diagnostic classifier. Through extensive experiments, the proposed BSDA-Net is found to yield state-of-the-art segmentation and classification results on the OCTA-500, OCTAGON, and FAZID datasets.
Brain segmentation based on multi-atlas guided 3D fully convolutional network ensembles
Jan 05, 2019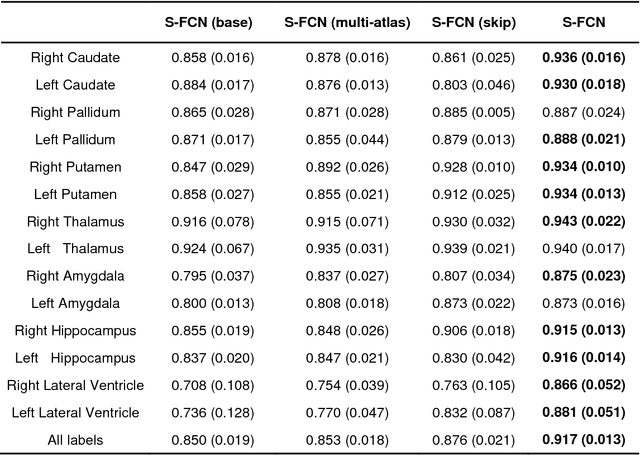

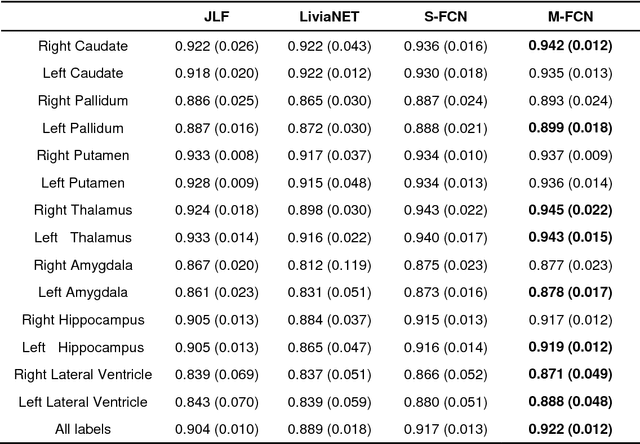

In this study, we proposed and validated a multi-atlas guided 3D fully convolutional network (FCN) ensemble model (M-FCN) for segmenting brain regions of interest (ROIs) from structural magnetic resonance images (MRIs). One major limitation of existing state-of-the-art 3D FCN segmentation models is that they often apply image patches of fixed size throughout training and testing, which may miss some complex tissue appearance patterns of different brain ROIs. To address this limitation, we trained a 3D FCN model for each ROI using patches of adaptive size and embedded outputs of the convolutional layers in the deconvolutional layers to further capture the local and global context patterns. In addition, with an introduction of multi-atlas based guidance in M-FCN, our segmentation was generated by combining the information of images and labels, which is highly robust. To reduce over-fitting of the FCN model on the training data, we adopted an ensemble strategy in the learning procedure. Evaluation was performed on two brain MRI datasets, aiming respectively at segmenting 14 subcortical and ventricular structures and 54 brain ROIs. The segmentation results of the proposed method were compared with those of a state-of-the-art multi-atlas based segmentation method and an existing 3D FCN segmentation model. Our results suggested that the proposed method had a superior segmentation performance.