 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPT+: A Parameter and Memory Efficient Transfer Learning Method for High-resolution Medical Image Classification
Aug 05, 2024



The success of large-scale pre-trained models has established fine-tuning as a standard method for achieving significant improvements in downstream tasks. However, fine-tuning the entire parameter set of a pre-trained model is costly. Parameter-efficient transfer learning (PETL) has recently emerged as a cost-effective alternative for adapting pre-trained models to downstream tasks. Despite its advantages, the increasing model size and input resolution present challenges for PETL, as the training memory consumption is not reduced as effectively as the parameter usage. In this paper, we introduce Fine-grained Prompt Tuning plus (FPT+), a PETL method designed for high-resolution medical image classification, which significantly reduces memory consumption compared to other PETL methods. FPT+ performs transfer learning by training a lightweight side network and accessing pre-trained knowledge from a large pre-trained model (LPM) through fine-grained prompts and fusion modules. Specifically, we freeze the LPM and construct a learnable lightweight side network. The frozen LPM processes high-resolution images to extract fine-grained features, while the side network employs the corresponding down-sampled low-resolution images to minimize the memory usage. To enable the side network to leverage pre-trained knowledge, we propose fine-grained prompts and fusion modules, which collaborate to summarize information through the LPM's intermediate activations. We evaluate FPT+ on eight medical image datasets of varying sizes, modalities, and complexities. Experimental results demonstrate that FPT+ outperforms other PETL methods, using only 1.03% of the learnable parameters and 3.18% of the memory required for fine-tuning an entire ViT-B model. Our code is available at https://github.com/YijinHuang/FPT.
Saliency-guided and Patch-based Mixup for Long-tailed Skin Cancer Image Classification
Jun 16, 2024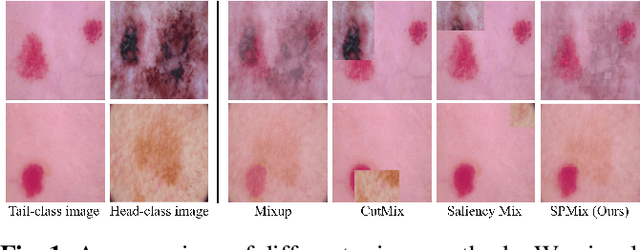



Medical image datasets often exhibit long-tailed distributions due to the inherent challenges in medical data collection and annotation. In long-tailed contexts, some common disease categories account for most of the data, while only a few samples are available in the rare disease categories, resulting in poor performance of deep learning methods. To address this issue, previous approaches have employed class re-sampling or re-weighting techniques, which often encounter challenges such as overfitting to tail classes or difficulties in optimization during training. In this work, we propose a novel approach, namely \textbf{S}aliency-guided and \textbf{P}atch-based \textbf{Mix}up (SPMix) for long-tailed skin cancer image classification. Specifically, given a tail-class image and a head-class image, we generate a new tail-class image by mixing them under the guidance of saliency mapping, which allows for preserving and augmenting the discriminative features of the tail classes without any interference of the head-class features. Extensive experiments are conducted on the ISIC2018 dataset, demonstrating the superiority of SPMix over existing state-of-the-art methods.
FPT: Fine-grained Prompt Tuning for Parameter and Memory Efficient Fine Tuning in High-resolution Medical Image Classification
Mar 12, 2024Parameter-efficient fine-tuning (PEFT) is proposed as a cost-effective way to transfer pre-trained models to downstream tasks, avoiding the high cost of updating entire large-scale pre-trained models (LPMs). In this work, we present Fine-grained Prompt Tuning (FPT), a novel PEFT method for medical image classification. FPT significantly reduces memory consumption compared to other PEFT methods, especially in high-resolution contexts. To achieve this, we first freeze the weights of the LPM and construct a learnable lightweight side network. The frozen LPM takes high-resolution images as input to extract fine-grained features, while the side network is fed low-resolution images to reduce memory usage. To allow the side network to access pre-trained knowledge, we introduce fine-grained prompts that summarize information from the LPM through a fusion module. Important tokens selection and preloading techniques are employed to further reduce training cost and memory requirements. We evaluate FPT on four medical datasets with varying sizes, modalities, and complexities. Experimental results demonstrate that FPT achieves comparable performance to fine-tuning the entire LPM while using only 1.8% of the learnable parameters and 13% of the memory costs of an encoder ViT-B model with a 512 x 512 input resolution.
PRIOR: Prototype Representation Joint Learning from Medical Images and Reports
Jul 24, 2023



Contrastive learning based vision-language joint pre-training has emerged as a successful representation learning strategy. In this paper, we present a prototype representation learning framework incorporating both global and local alignment between medical images and reports. In contrast to standard global multi-modality alignment methods, we employ a local alignment module for fine-grained representation. Furthermore, a cross-modality conditional reconstruction module is designed to interchange information across modalities in the training phase by reconstructing masked images and reports. For reconstructing long reports, a sentence-wise prototype memory bank is constructed, enabling the network to focus on low-level localized visual and high-level clinical linguistic features. Additionally, a non-auto-regressive generation paradigm is proposed for reconstructing non-sequential reports. Experimental results on five downstream tasks, including supervised classification, zero-shot classification, image-to-text retrieval, semantic segmentation, and object detection, show the proposed method outperforms other state-of-the-art methods across multiple datasets and under different dataset size settings. The code is available at https://github.com/QtacierP/PRIOR.
Learning Enhancement From Degradation: A Diffusion Model For Fundus Image Enhancement
Mar 08, 2023

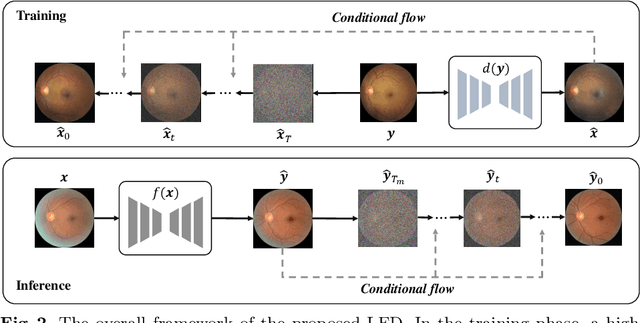

The quality of a fundus image can be compromised by numerous factors, many of which are challenging to be appropriately and mathematically modeled. In this paper, we introduce a novel diffusion model based framework, named Learning Enhancement from Degradation (LED), for enhancing fundus images. Specifically, we first adopt a data-driven degradation framework to learn degradation mappings from unpaired high-quality to low-quality images. We then apply a conditional diffusion model to learn the inverse enhancement process in a paired manner. The proposed LED is able to output enhancement results that maintain clinically important features with better clarity. Moreover, in the inference phase, LED can be easily and effectively integrated with any existing fundus image enhancement framework. We evaluate the proposed LED on several downstream tasks with respect to various clinically-relevant metrics, successfully demonstrating its superiority over existing state-of-the-art methods both quantitatively and qualitatively. The source code is available at https://github.com/QtacierP/LED.
UNO-QA: An Unsupervised Anomaly-Aware Framework with Test-Time Clustering for OCTA Image Quality Assessment
Dec 20, 2022



Medical image quality assessment (MIQA) is a vital prerequisite in various medical image analysis applications. Most existing MIQA algorithms are fully supervised that request a large amount of annotated data. However, annotating medical images is time-consuming and labor-intensive. In this paper, we propose an unsupervised anomaly-aware framework with test-time clustering for optical coherence tomography angiography (OCTA) image quality assessment in a setting wherein only a set of high-quality samples are accessible in the training phase. Specifically, a feature-embedding-based low-quality representation module is proposed to quantify the quality of OCTA images and then to discriminate between outstanding quality and non-outstanding quality. Within the non-outstanding quality class, to further distinguish gradable images from ungradable ones, we perform dimension reduction and clustering of multi-scale image features extracted by the trained OCTA quality representation network. Extensive experiments are conducted on one publicly accessible dataset sOCTA-3*3-10k, with superiority of our proposed framework being successfully established.
AADG: Automatic Augmentation for Domain Generalization on Retinal Image Segmentation
Jul 27, 2022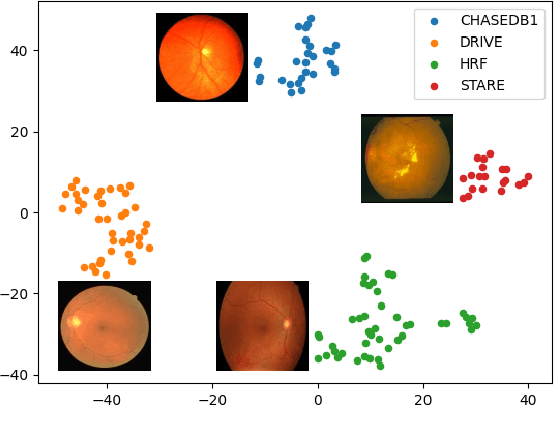
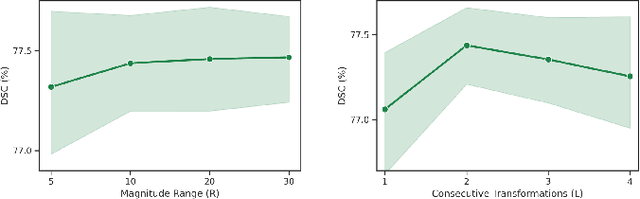
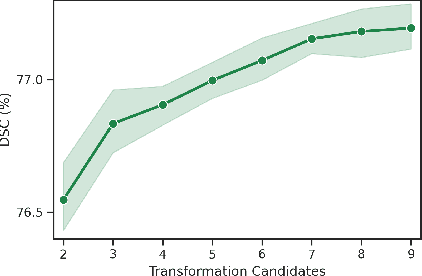
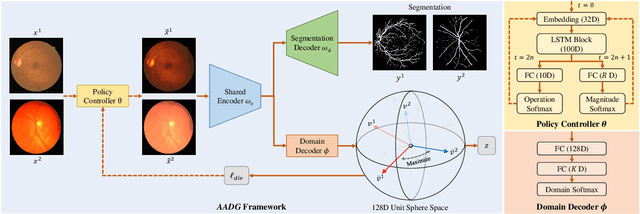
Convolutional neural networks have been widely applied to medical image segmentation and have achieved considerable performance. However, the performance may be significantly affected by the domain gap between training data (source domain) and testing data (target domain). To address this issue, we propose a data manipulation based domain generalization method, called Automated Augmentation for Domain Generalization (AADG). Our AADG framework can effectively sample data augmentation policies that generate novel domains and diversify the training set from an appropriate search space. Specifically, we introduce a novel proxy task maximizing the diversity among multiple augmented novel domains as measured by the Sinkhorn distance in a unit sphere space, making automated augmentation tractable. Adversarial training and deep reinforcement learning are employed to efficiently search the objectives. Quantitative and qualitative experiments on 11 publicly-accessible fundus image datasets (four for retinal vessel segmentation, four for optic disc and cup (OD/OC) segmentation and three for retinal lesion segmentation) are comprehensively performed. Two OCTA datasets for retinal vasculature segmentation are further involved to validate cross-modality generalization. Our proposed AADG exhibits state-of-the-art generalization performance and outperforms existing approaches by considerable margins on retinal vessel, OD/OC and lesion segmentation tasks. The learned policies are empirically validated to be model-agnostic and can transfer well to other models. The source code is available at https://github.com/CRazorback/AADG.
LesionPaste: One-Shot Anomaly Detection for Medical Images
Mar 12, 2022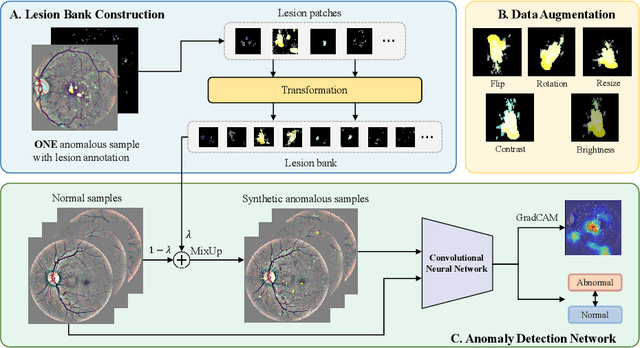

Due to the high cost of manually annotating medical images, especially for large-scale datasets, anomaly detection has been explored through training models with only normal data. Lacking prior knowledge of true anomalies is the main reason for the limited application of previous anomaly detection methods, especially in the medical image analysis realm. In this work, we propose a one-shot anomaly detection framework, namely LesionPaste, that utilizes true anomalies from a single annotated sample and synthesizes artificial anomalous samples for anomaly detection. First, a lesion bank is constructed by applying augmentation to randomly selected lesion patches. Then, MixUp is adopted to paste patches from the lesion bank at random positions in normal images to synthesize anomalous samples for training. Finally, a classification network is trained using the synthetic abnormal samples and the true normal data. Extensive experiments are conducted on two publicly-available medical image datasets with different types of abnormalities. On both datasets, our proposed LesionPaste largely outperforms several state-of-the-art unsupervised and semi-supervised anomaly detection methods, and is on a par with the fully-supervised counterpart. To note, LesionPaste is even better than the fully-supervised method in detecting early-stage diabetic retinopathy.
Identifying the key components in ResNet-50 for diabetic retinopathy grading from fundus images: a systematic investigation
Oct 27, 2021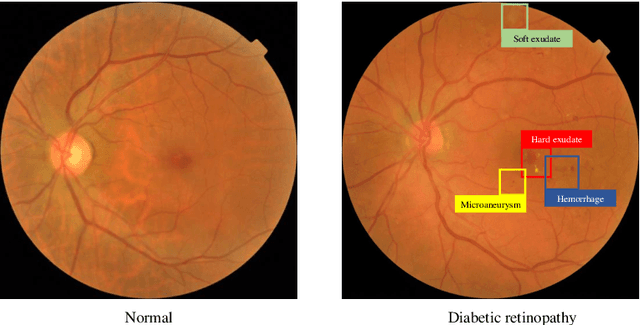
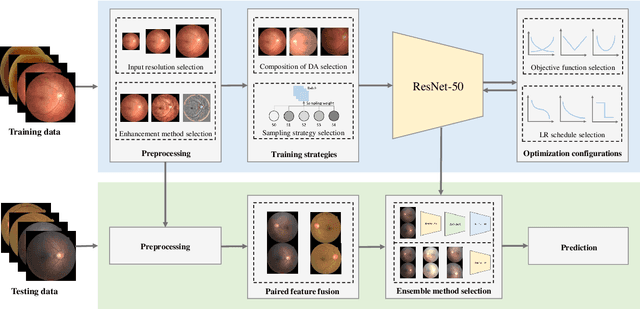

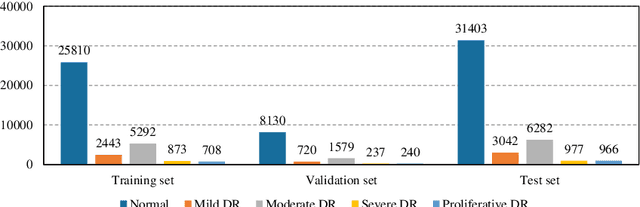
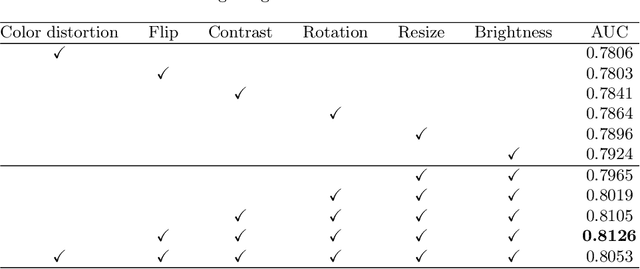
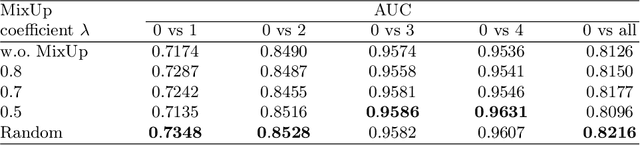
Although deep learning based diabetic retinopathy (DR) classification methods typically benefit from well-designed architectures of convolutional neural networks, the training setting also has a non-negligible impact on the prediction performance. The training setting includes various interdependent components, such as objective function, data sampling strategy and data augmentation approach. To identify the key components in a standard deep learning framework (ResNet-50) for DR grading, we systematically analyze the impact of several major components. Extensive experiments are conducted on a publicly-available dataset EyePACS. We demonstrate that (1) the ResNet-50 framework for DR grading is sensitive to input resolution, objective function, and composition of data augmentation, (2) using mean square error as the loss function can effectively improve the performance with respect to a task-specific evaluation metric, namely the quadratically-weighted Kappa, (3) utilizing eye pairs boosts the performance of DR grading and (4) using data resampling to address the problem of imbalanced data distribution in EyePACS hurts the performance. Based on these observations and an optimal combination of the investigated components, our framework, without any specialized network design, achieves the state-of-the-art result (0.8631 for Kappa) on the EyePACS test set (a total of 42670 fundus images) with only image-level labels. Our codes and pre-trained model are available at https://github.com/YijinHuang/pytorch-classification
Lesion-based Contrastive Learning for Diabetic Retinopathy Grading from Fundus Images
Jul 17, 2021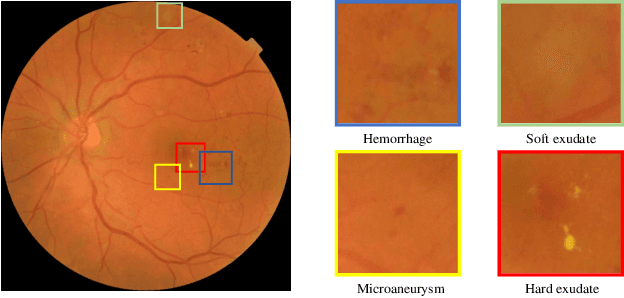

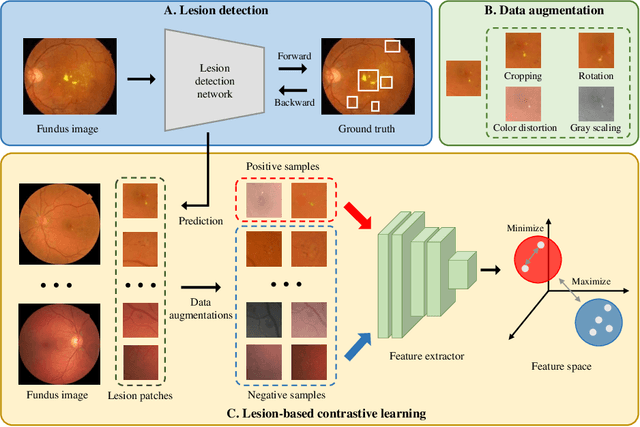
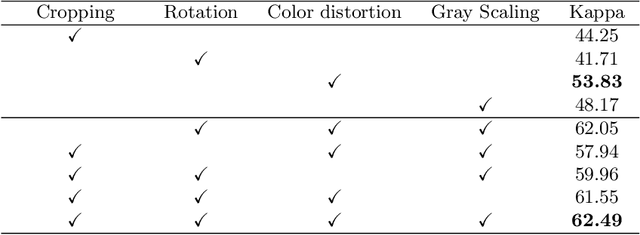
Manually annotating medical images is extremely expensive, especially for large-scale datasets. Self-supervised contrastive learning has been explored to learn feature representations from unlabeled images. However, unlike natural images, the application of contrastive learning to medical images is relatively limited. In this work, we propose a self-supervised framework, namely lesion-based contrastive learning for automated diabetic retinopathy (DR) grading. Instead of taking entire images as the input in the common contrastive learning scheme, lesion patches are employed to encourage the feature extractor to learn representations that are highly discriminative for DR grading. We also investigate different data augmentation operations in defining our contrastive prediction task. Extensive experiments are conducted on the publicly-accessible dataset EyePACS, demonstrating that our proposed framework performs outstandingly on DR grading in terms of both linear evaluation and transfer capacity evaluation.