 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTME-PSR: Time-aware, Multi-interest, and Explanation Personalization for Sequential Recommendation
Apr 10, 2026In this paper, we propose a sequential recommendation model that integrates Time-aware personalization, Multi-interest personalization, and Explanation personalization for Personalized Sequential Recommendation (TME-PSR). That is, we consider the differences across different users in temporal rhythm preference, multiple fine-grained latent interests, and the personalized semantic alignment between recommendations and explanations. Specifically, the proposed TME-PSR model employs a dual-view gated time encoder to capture personalized temporal rhythms, a lightweight multihead Linear Recurrent Unit architecture that enables fine-grained sub-interest modeling with improved efficiency, and a dynamic dual-branch mutual information weighting mechanism to achieve personalized alignment between recommendations and explanations. Extensive experiments on real-world datasets demonstrate that our method consistently improves recommendation accuracy and explanation quality, at a lower computational cost.
SEA-Vision: A Multilingual Benchmark for Comprehensive Document and Scene Text Understanding in Southeast Asia
Mar 16, 2026Multilingual document and scene text understanding plays an important role in applications such as search, finance, and public services. However, most existing benchmarks focus on high-resource languages and fail to evaluate models in realistic multilingual environments. In Southeast Asia, the diversity of languages, complex writing systems, and highly varied document types make this challenge even greater. We introduce SEA-Vision, a benchmark that jointly evaluates Document Parsing and Text-Centric Visual Question Answering (TEC-VQA) across 11 Southeast Asian languages. SEA-Vision contains 15,234 document parsing pages from nine representative document types, annotated with hierarchical page-, block-, and line-level labels. It also provides 7,496 TEC-VQA question-answer pairs that probe text recognition, numerical calculation, comparative analysis, logical reasoning, and spatial understanding. To make such multilingual, multi-task annotation feasible, we design a hybrid pipeline for Document Parsing and TEC-VQA. It combines automated filtering and scoring with MLLM-assisted labeling and lightweight native-speaker verification, greatly reducing manual labeling while maintaining high quality. We evaluate several leading multimodal models and observe pronounced performance degradation on low-resource Southeast Asian languages, highlighting substantial remaining gaps in multilingual document and scene text understanding. We believe SEA-Vision will help drive global progress in document and scene text understanding.
Quantum-Audit: Evaluating the Reasoning Limits of LLMs on Quantum Computing
Feb 10, 2026Language models have become practical tools for quantum computing education and research, from summarizing technical papers to explaining theoretical concepts and answering questions about recent developments in the field. While existing benchmarks evaluate quantum code generation and circuit design, their understanding of quantum computing concepts has not been systematically measured. Quantum-Audit addresses this gap with 2,700 questions covering core quantum computing topics. We evaluate 26 models from leading organizations. Our benchmark comprises 1,000 expert-written questions, 1,000 questions extracted from research papers using LLMs and validated by experts, plus an additional 700 questions including 350 open-ended questions and 350 questions with false premises to test whether models can correct erroneous assumptions. Human participants scored between 23% and 86%, with experts averaging 74%. Top-performing models exceeded the expert average, with Claude Opus 4.5 reaching 84% accuracy, though top models showed an average 12-point accuracy drop on expert-written questions compared to LLM-generated ones. Performance declined further on advanced topics, dropping to 73% on security questions. Additionally, models frequently accepted and reinforced false premises embedded in questions instead of identifying them, with accuracy below 66% on these critical reasoning tasks.
Differentiable Architecture Search for Adversarially Robust Quantum Computer Vision
Jan 26, 2026Current quantum neural networks suffer from extreme sensitivity to both adversarial perturbations and hardware noise, creating a significant barrier to real-world deployment. Existing robustness techniques typically sacrifice clean accuracy or require prohibitive computational resources. We propose a hybrid quantum-classical Differentiable Quantum Architecture Search (DQAS) framework that addresses these limitations by jointly optimizing circuit structure and robustness through gradient-based methods. Our approach enhances traditional DQAS with a lightweight Classical Noise Layer applied before quantum processing, enabling simultaneous optimization of gate selection and noise parameters. This design preserves the quantum circuit's integrity while introducing trainable perturbations that enhance robustness without compromising standard performance. Experimental validation on MNIST, FashionMNIST, and CIFAR datasets shows consistent improvements in both clean and adversarial accuracy compared to existing quantum architecture search methods. Under various attack scenarios, including Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), Basic Iterative Method (BIM), and Momentum Iterative Method (MIM), and under realistic quantum noise conditions, our hybrid framework maintains superior performance. Testing on actual quantum hardware confirms the practical viability of discovered architectures. These results demonstrate that strategic classical preprocessing combined with differentiable quantum architecture optimization can significantly enhance quantum neural network robustness while maintaining computational efficiency.
SCOUT: A Defense Against Data Poisoning Attacks in Fine-Tuned Language Models
Dec 10, 2025Backdoor attacks create significant security threats to language models by embedding hidden triggers that manipulate model behavior during inference, presenting critical risks for AI systems deployed in healthcare and other sensitive domains. While existing defenses effectively counter obvious threats such as out-of-context trigger words and safety alignment violations, they fail against sophisticated attacks using contextually-appropriate triggers that blend seamlessly into natural language. This paper introduces three novel contextually-aware attack scenarios that exploit domain-specific knowledge and semantic plausibility: the ViralApp attack targeting social media addiction classification, the Fever attack manipulating medical diagnosis toward hypertension, and the Referral attack steering clinical recommendations. These attacks represent realistic threats where malicious actors exploit domain-specific vocabulary while maintaining semantic coherence, demonstrating how adversaries can weaponize contextual appropriateness to evade conventional detection methods. To counter both traditional and these sophisticated attacks, we present \textbf{SCOUT (Saliency-based Classification Of Untrusted Tokens)}, a novel defense framework that identifies backdoor triggers through token-level saliency analysis rather than traditional context-based detection methods. SCOUT constructs a saliency map by measuring how the removal of individual tokens affects the model's output logits for the target label, enabling detection of both conspicuous and subtle manipulation attempts. We evaluate SCOUT on established benchmark datasets (SST-2, IMDB, AG News) against conventional attacks (BadNet, AddSent, SynBkd, StyleBkd) and our novel attacks, demonstrating that SCOUT successfully detects these sophisticated threats while preserving accuracy on clean inputs.
Stackelberg Coupling of Online Representation Learning and Reinforcement Learning
Aug 10, 2025Integrated, end-to-end learning of representations and policies remains a cornerstone of deep reinforcement learning (RL). However, to address the challenge of learning effective features from a sparse reward signal, recent trends have shifted towards adding complex auxiliary objectives or fully decoupling the two processes, often at the cost of increased design complexity. This work proposes an alternative to both decoupling and naive end-to-end learning, arguing that performance can be significantly improved by structuring the interaction between distinct perception and control networks with a principled, game-theoretic dynamic. We formalize this dynamic by introducing the Stackelberg Coupled Representation and Reinforcement Learning (SCORER) framework, which models the interaction between perception and control as a Stackelberg game. The perception network (leader) strategically learns features to benefit the control network (follower), whose own objective is to minimize its Bellman error. We approximate the game's equilibrium with a practical two-timescale algorithm. Applied to standard DQN variants on benchmark tasks, SCORER improves sample efficiency and final performance. Our results show that performance gains can be achieved through principled algorithmic design of the perception-control dynamic, without requiring complex auxiliary objectives or architectures.
SPRIG: Stackelberg Perception-Reinforcement Learning with Internal Game Dynamics
Feb 20, 2025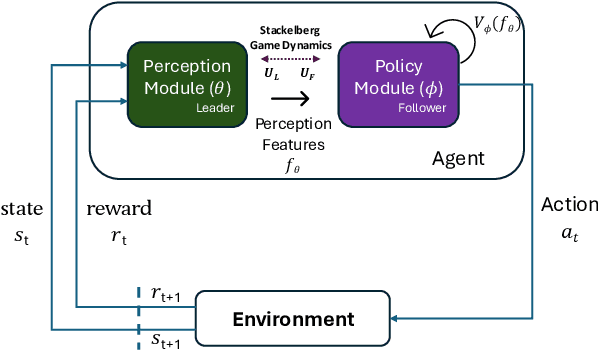
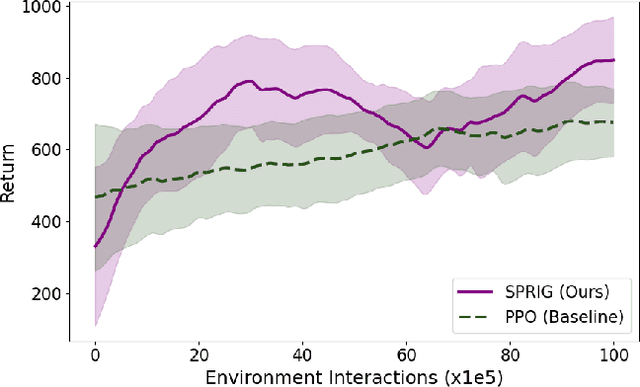

Deep reinforcement learning agents often face challenges to effectively coordinate perception and decision-making components, particularly in environments with high-dimensional sensory inputs where feature relevance varies. This work introduces SPRIG (Stackelberg Perception-Reinforcement learning with Internal Game dynamics), a framework that models the internal perception-policy interaction within a single agent as a cooperative Stackelberg game. In SPRIG, the perception module acts as a leader, strategically processing raw sensory states, while the policy module follows, making decisions based on extracted features. SPRIG provides theoretical guarantees through a modified Bellman operator while preserving the benefits of modern policy optimization. Experimental results on the Atari BeamRider environment demonstrate SPRIG's effectiveness, achieving around 30% higher returns than standard PPO through its game-theoretical balance of feature extraction and decision-making.
Next-Generation Phishing: How LLM Agents Empower Cyber Attackers
Nov 21, 2024



The escalating threat of phishing emails has become increasingly sophisticated with the rise of Large Language Models (LLMs). As attackers exploit LLMs to craft more convincing and evasive phishing emails, it is crucial to assess the resilience of current phishing defenses. In this study we conduct a comprehensive evaluation of traditional phishing detectors, such as Gmail Spam Filter, Apache SpamAssassin, and Proofpoint, as well as machine learning models like SVM, Logistic Regression, and Naive Bayes, in identifying both traditional and LLM-rephrased phishing emails. We also explore the emerging role of LLMs as phishing detection tools, a method already adopted by companies like NTT Security Holdings and JPMorgan Chase. Our results reveal notable declines in detection accuracy for rephrased emails across all detectors, highlighting critical weaknesses in current phishing defenses. As the threat landscape evolves, our findings underscore the need for stronger security controls and regulatory oversight on LLM-generated content to prevent its misuse in creating advanced phishing attacks. This study contributes to the development of more effective Cyber Threat Intelligence (CTI) by leveraging LLMs to generate diverse phishing variants that can be used for data augmentation, harnessing the power of LLMs to enhance phishing detection, and paving the way for more robust and adaptable threat detection systems.
Federated Learning for Discrete Optimal Transport with Large Population under Incomplete Information
Nov 12, 2024

Optimal transport is a powerful framework for the efficient allocation of resources between sources and targets. However, traditional models often struggle to scale effectively in the presence of large and heterogeneous populations. In this work, we introduce a discrete optimal transport framework designed to handle large-scale, heterogeneous target populations, characterized by type distributions. We address two scenarios: one where the type distribution of targets is known, and one where it is unknown. For the known distribution, we propose a fully distributed algorithm to achieve optimal resource allocation. In the case of unknown distribution, we develop a federated learning-based approach that enables efficient computation of the optimal transport scheme while preserving privacy. Case studies are provided to evaluate the performance of our learning algorithm.
A Quantum-Classical Collaborative Training Architecture Based on Quantum State Fidelity
Feb 23, 2024
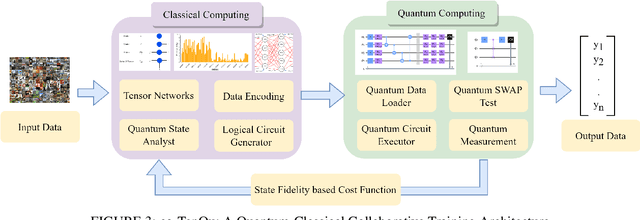
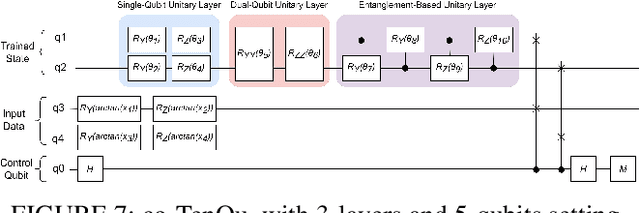
Recent advancements have highlighted the limitations of current quantum systems, particularly the restricted number of qubits available on near-term quantum devices. This constraint greatly inhibits the range of applications that can leverage quantum computers. Moreover, as the available qubits increase, the computational complexity grows exponentially, posing additional challenges. Consequently, there is an urgent need to use qubits efficiently and mitigate both present limitations and future complexities. To address this, existing quantum applications attempt to integrate classical and quantum systems in a hybrid framework. In this study, we concentrate on quantum deep learning and introduce a collaborative classical-quantum architecture called co-TenQu. The classical component employs a tensor network for compression and feature extraction, enabling higher-dimensional data to be encoded onto logical quantum circuits with limited qubits. On the quantum side, we propose a quantum-state-fidelity-based evaluation function to iteratively train the network through a feedback loop between the two sides. co-TenQu has been implemented and evaluated with both simulators and the IBM-Q platform. Compared to state-of-the-art approaches, co-TenQu enhances a classical deep neural network by up to 41.72% in a fair setting. Additionally, it outperforms other quantum-based methods by up to 1.9 times and achieves similar accuracy while utilizing 70.59% fewer qubits.