 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternet of Agentic AI: Incentive-Compatible Distributed Teaming and Workflow
Feb 03, 2026Large language models (LLMs) have enabled a new class of agentic AI systems that reason, plan, and act by invoking external tools. However, most existing agentic architectures remain centralized and monolithic, limiting scalability, specialization, and interoperability. This paper proposes a framework for scalable agentic intelligence, termed the Internet of Agentic AI, in which autonomous, heterogeneous agents distributed across cloud and edge infrastructure dynamically form coalitions to execute task-driven workflows. We formalize a network-native model of agentic collaboration and introduce an incentive-compatible workflow-coalition feasibility framework that integrates capability coverage, network locality, and economic implementability. To enable scalable coordination, we formulate a minimum-effort coalition selection problem and propose a decentralized coalition formation algorithm. The proposed framework can operate as a coordination layer above the Model Context Protocol (MCP). A healthcare case study demonstrates how domain specialization, cloud-edge heterogeneity, and dynamic coalition formation enable scalable, resilient, and economically viable agentic workflows. This work lays the foundation for principled coordination and scalability in the emerging era of Internet of Agentic AI.
Decentralized No-Regret Frequency-Time Scheduling for FMCW Radar Interference Avoidance
Dec 31, 2025Automotive FMCW radars are indispensable to modern ADAS and autonomous-driving systems, but their increasing density has intensified the risk of mutual interference. Existing mitigation techniques, including reactive receiver-side suppression, proactive waveform design, and cooperative scheduling, often face limitations in scalability, reliance on side-channel communication, or degradation of range-Doppler resolution. Building on our earlier work on decentralized Frequency-Domain No-Regret hopping, this paper introduces a unified time-frequency game-theoretic framework that enables radars to adapt across both spectral and temporal resources. We formulate the interference-avoidance problem as a repeated anti-coordination game, in which each radar autonomously updates a mixed strategy over frequency subbands and chirp-level time offsets using regret-minimization dynamics. We show that the proposed Time-Frequency No-Regret Hopping algorithm achieves vanishing external and swap regret, and that the induced empirical play converges to an $\varepsilon$-coarse correlated equilibrium or a correlated equilibrium. Theoretical analysis provides regret bounds in the joint domain, revealing how temporal adaptation implicitly regularizes frequency selection and enhances robustness against asynchronous interference. Numerical experiments with multi-radar scenarios demonstrate substantial improvements in SINR, collision rate, and range-Doppler quality compared with time-frequency random hopping and centralized Nash-based benchmarks.
Agentic AI for Cyber Resilience: A New Security Paradigm and Its System-Theoretic Foundations
Dec 28, 2025Cybersecurity is being fundamentally reshaped by foundation-model-based artificial intelligence. Large language models now enable autonomous planning, tool orchestration, and strategic adaptation at scale, challenging security architectures built on static rules, perimeter defenses, and human-centered workflows. This chapter argues for a shift from prevention-centric security toward agentic cyber resilience. Rather than seeking perfect protection, resilient systems must anticipate disruption, maintain critical functions under attack, recover efficiently, and learn continuously. We situate this shift within the historical evolution of cybersecurity paradigms, culminating in an AI-augmented paradigm where autonomous agents participate directly in sensing, reasoning, action, and adaptation across cyber and cyber-physical systems. We then develop a system-level framework for designing agentic AI workflows. A general agentic architecture is introduced, and attacker and defender workflows are analyzed as coupled adaptive processes, and game-theoretic formulations are shown to provide a unifying design language for autonomy allocation, information flow, and temporal composition. Case studies in automated penetration testing, remediation, and cyber deception illustrate how equilibrium-based design enables system-level resiliency design.
From Texts to Shields: Convergence of Large Language Models and Cybersecurity
May 01, 2025This report explores the convergence of large language models (LLMs) and cybersecurity, synthesizing interdisciplinary insights from network security, artificial intelligence, formal methods, and human-centered design. It examines emerging applications of LLMs in software and network security, 5G vulnerability analysis, and generative security engineering. The report highlights the role of agentic LLMs in automating complex tasks, improving operational efficiency, and enabling reasoning-driven security analytics. Socio-technical challenges associated with the deployment of LLMs -- including trust, transparency, and ethical considerations -- can be addressed through strategies such as human-in-the-loop systems, role-specific training, and proactive robustness testing. The report further outlines critical research challenges in ensuring interpretability, safety, and fairness in LLM-based systems, particularly in high-stakes domains. By integrating technical advances with organizational and societal considerations, this report presents a forward-looking research agenda for the secure and effective adoption of LLMs in cybersecurity.
A Game-Theoretic Approach for High-Resolution Automotive FMCW Radar Interference Avoidance
Mar 04, 2025
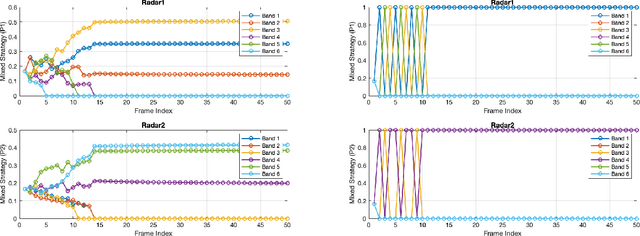
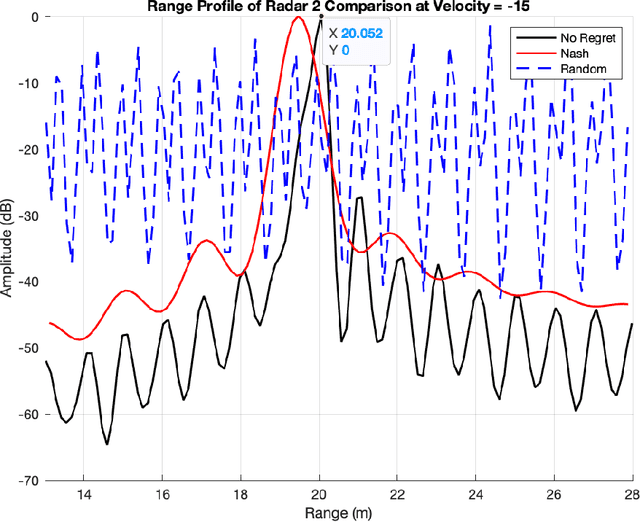
Nonlinear frequency hopping has emerged as a promising approach for mitigating interference and enhancing range resolution in automotive FMCW radar systems. Achieving an optimal balance between high range-resolution and effective interference mitigation remains challenging, especially without centralized frequency scheduling. This paper presents a game-theoretic framework for interference avoidance, in which each radar operates as an independent player, optimizing its performance through decentralized decision-making. We examine two equilibrium concepts--Nash Equilibrium (NE) and Coarse Correlated Equilibrium (CCE)--as strategies for frequency band allocation, with CCE demonstrating particular effectiveness through regret minimization algorithms. We propose two interference avoidance algorithms: Nash Hopping, a model-based approach, and No-Regret Hopping, a model-free adaptive method. Simulation results indicate that both methods effectively reduce interference and enhance the signal-to-interference-plus-noise ratio (SINR). Notably, No-regret Hopping further optimizes frequency spectrum utilization, achieving improved range resolution compared to Nash Hopping.
The Game-Theoretic Symbiosis of Trust and AI in Networked Systems
Nov 19, 2024This chapter explores the symbiotic relationship between Artificial Intelligence (AI) and trust in networked systems, focusing on how these two elements reinforce each other in strategic cybersecurity contexts. AI's capabilities in data processing, learning, and real-time response offer unprecedented support for managing trust in dynamic, complex networks. However, the successful integration of AI also hinges on the trustworthiness of AI systems themselves. Using a game-theoretic framework, this chapter presents approaches to trust evaluation, the strategic role of AI in cybersecurity, and governance frameworks that ensure responsible AI deployment. We investigate how trust, when dynamically managed through AI, can form a resilient security ecosystem. By examining trust as both an AI output and an AI requirement, this chapter sets the foundation for a positive feedback loop where AI enhances network security and the trust placed in AI systems fosters their adoption.
ADAPT: A Game-Theoretic and Neuro-Symbolic Framework for Automated Distributed Adaptive Penetration Testing
Oct 31, 2024The integration of AI into modern critical infrastructure systems, such as healthcare, has introduced new vulnerabilities that can significantly impact workflow, efficiency, and safety. Additionally, the increased connectivity has made traditional human-driven penetration testing insufficient for assessing risks and developing remediation strategies. Consequently, there is a pressing need for a distributed, adaptive, and efficient automated penetration testing framework that not only identifies vulnerabilities but also provides countermeasures to enhance security posture. This work presents ADAPT, a game-theoretic and neuro-symbolic framework for automated distributed adaptive penetration testing, specifically designed to address the unique cybersecurity challenges of AI-enabled healthcare infrastructure networks. We use a healthcare system case study to illustrate the methodologies within ADAPT. The proposed solution enables a learning-based risk assessment. Numerical experiments are used to demonstrate effective countermeasures against various tactical techniques employed by adversarial AI.
Learning from Response not Preference: A Stackelberg Approach for LLM Detoxification using Non-parallel Data
Oct 27, 2024



Text detoxification, a variant of style transfer tasks, finds useful applications in online social media. This work presents a fine-tuning method that only uses non-parallel data to turn large language models (LLM) into a detoxification rewritter. We model the fine-tuning process as a Stackelberg game between an LLM (leader) and a toxicity screener (follower), which is a binary style classifier (toxic or non-toxic). The LLM aims to align its preference according to the screener and generate paraphases passing the screening. The primary challenge of non-parallel data fine-tuning is incomplete preference. In the case of unsuccessful paraphrases, the classifier cannot establish a preference between the input and paraphrase, as they belong to the same toxic style. Hence, preference-alignment fine-tuning methods, such as direct preference optimization (DPO), no longer apply. To address the challenge of incomplete preference, we propose Stackelberg response optimization (SRO), adapted from DPO, to enable the LLM to learn from the follower's response. The gist is that SRO decreases the likelihood of generating the paraphrase if it fails the follower's screening while performing DPO on the pair of the toxic input and its paraphrase when the latter passes the screening. Experiments indicate that the SRO-fine-tunned LLM achieves satisfying performance comparable to state-of-the-art models regarding style accuracy, content similarity, and fluency. The overall detoxification performance surpasses other computing methods and matches the human reference. Additional empirical evidence suggests that SRO is sensitive to the screener's feedback, and a slight perturbation leads to a significant performance drop. We release the code and LLM models at \url{https://github.com/XXXinhong/Detoxification_LLM}.
Meta Stackelberg Game: Robust Federated Learning against Adaptive and Mixed Poisoning Attacks
Oct 22, 2024



Federated learning (FL) is susceptible to a range of security threats. Although various defense mechanisms have been proposed, they are typically non-adaptive and tailored to specific types of attacks, leaving them insufficient in the face of multiple uncertain, unknown, and adaptive attacks employing diverse strategies. This work formulates adversarial federated learning under a mixture of various attacks as a Bayesian Stackelberg Markov game, based on which we propose the meta-Stackelberg defense composed of pre-training and online adaptation. {The gist is to simulate strong attack behavior using reinforcement learning (RL-based attacks) in pre-training and then design meta-RL-based defense to combat diverse and adaptive attacks.} We develop an efficient meta-learning approach to solve the game, leading to a robust and adaptive FL defense. Theoretically, our meta-learning algorithm, meta-Stackelberg learning, provably converges to the first-order $\varepsilon$-meta-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations with $O(\varepsilon^{-4})$ samples per iteration. Experiments show that our meta-Stackelberg framework performs superbly against strong model poisoning and backdoor attacks of uncertain and unknown types.
MEGA-PT: A Meta-Game Framework for Agile Penetration Testing
Sep 21, 2024



Penetration testing is an essential means of proactive defense in the face of escalating cybersecurity incidents. Traditional manual penetration testing methods are time-consuming, resource-intensive, and prone to human errors. Current trends in automated penetration testing are also impractical, facing significant challenges such as the curse of dimensionality, scalability issues, and lack of adaptability to network changes. To address these issues, we propose MEGA-PT, a meta-game penetration testing framework, featuring micro tactic games for node-level local interactions and a macro strategy process for network-wide attack chains. The micro- and macro-level modeling enables distributed, adaptive, collaborative, and fast penetration testing. MEGA-PT offers agile solutions for various security schemes, including optimal local penetration plans, purple teaming solutions, and risk assessment, providing fundamental principles to guide future automated penetration testing. Our experiments demonstrate the effectiveness and agility of our model by providing improved defense strategies and adaptability to changes at both local and network levels.