 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Classical to Quantum Reinforcement Learning and Its Applications in Quantum Control: A Beginner's Tutorial
Jan 13, 2026This tutorial is designed to make reinforcement learning (RL) more accessible to undergraduate students by offering clear, example-driven explanations. It focuses on bridging the gap between RL theory and practical coding applications, addressing common challenges that students face when transitioning from conceptual understanding to implementation. Through hands-on examples and approachable explanations, the tutorial aims to equip students with the foundational skills needed to confidently apply RL techniques in real-world scenarios.
Online Learning with Probing for Sequential User-Centric Selection
Jul 27, 2025

We formalize sequential decision-making with information acquisition as the probing-augmented user-centric selection (PUCS) framework, where a learner first probes a subset of arms to obtain side information on resources and rewards, and then assigns $K$ plays to $M$ arms. PUCS covers applications such as ridesharing, wireless scheduling, and content recommendation, in which both resources and payoffs are initially unknown and probing is costly. For the offline setting with known distributions, we present a greedy probing algorithm with a constant-factor approximation guarantee $\zeta = (e-1)/(2e-1)$. For the online setting with unknown distributions, we introduce OLPA, a stochastic combinatorial bandit algorithm that achieves a regret bound $\mathcal{O}(\sqrt{T} + \ln^{2} T)$. We also prove a lower bound $\Omega(\sqrt{T})$, showing that the upper bound is tight up to logarithmic factors. Experiments on real-world data demonstrate the effectiveness of our solutions.
Fair Algorithms with Probing for Multi-Agent Multi-Armed Bandits
Jun 17, 2025
We propose a multi-agent multi-armed bandit (MA-MAB) framework aimed at ensuring fair outcomes across agents while maximizing overall system performance. A key challenge in this setting is decision-making under limited information about arm rewards. To address this, we introduce a novel probing framework that strategically gathers information about selected arms before allocation. In the offline setting, where reward distributions are known, we leverage submodular properties to design a greedy probing algorithm with a provable performance bound. For the more complex online setting, we develop an algorithm that achieves sublinear regret while maintaining fairness. Extensive experiments on synthetic and real-world datasets show that our approach outperforms baseline methods, achieving better fairness and efficiency.
Meta Stackelberg Game: Robust Federated Learning against Adaptive and Mixed Poisoning Attacks
Oct 22, 2024



Federated learning (FL) is susceptible to a range of security threats. Although various defense mechanisms have been proposed, they are typically non-adaptive and tailored to specific types of attacks, leaving them insufficient in the face of multiple uncertain, unknown, and adaptive attacks employing diverse strategies. This work formulates adversarial federated learning under a mixture of various attacks as a Bayesian Stackelberg Markov game, based on which we propose the meta-Stackelberg defense composed of pre-training and online adaptation. {The gist is to simulate strong attack behavior using reinforcement learning (RL-based attacks) in pre-training and then design meta-RL-based defense to combat diverse and adaptive attacks.} We develop an efficient meta-learning approach to solve the game, leading to a robust and adaptive FL defense. Theoretically, our meta-learning algorithm, meta-Stackelberg learning, provably converges to the first-order $\varepsilon$-meta-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations with $O(\varepsilon^{-4})$ samples per iteration. Experiments show that our meta-Stackelberg framework performs superbly against strong model poisoning and backdoor attacks of uncertain and unknown types.
Belief-Enriched Pessimistic Q-Learning against Adversarial State Perturbations
Mar 06, 2024Reinforcement learning (RL) has achieved phenomenal success in various domains. However, its data-driven nature also introduces new vulnerabilities that can be exploited by malicious opponents. Recent work shows that a well-trained RL agent can be easily manipulated by strategically perturbing its state observations at the test stage. Existing solutions either introduce a regularization term to improve the smoothness of the trained policy against perturbations or alternatively train the agent's policy and the attacker's policy. However, the former does not provide sufficient protection against strong attacks, while the latter is computationally prohibitive for large environments. In this work, we propose a new robust RL algorithm for deriving a pessimistic policy to safeguard against an agent's uncertainty about true states. This approach is further enhanced with belief state inference and diffusion-based state purification to reduce uncertainty. Empirical results show that our approach obtains superb performance under strong attacks and has a comparable training overhead with regularization-based methods. Our code is available at https://github.com/SliencerX/Belief-enriched-robust-Q-learning.
Enhancing LLM Safety via Constrained Direct Preference Optimization
Mar 04, 2024


The rapidly increasing capabilities of large language models (LLMs) raise an urgent need to align AI systems with diverse human preferences to simultaneously enhance their usefulness and safety, despite the often conflicting nature of these goals. To address this important problem, a promising approach is to enforce a safety constraint at the fine-tuning stage through a constrained Reinforcement Learning from Human Feedback (RLHF) framework. This approach, however, is computationally expensive and often unstable. In this work, we introduce Constrained DPO (C-DPO), a novel extension of the recently proposed Direct Preference Optimization (DPO) approach for fine-tuning LLMs that is both efficient and lightweight. By integrating dual gradient descent and DPO, our method identifies a nearly optimal trade-off between helpfulness and harmlessness without using reinforcement learning. Empirically, our approach provides a safety guarantee to LLMs that is missing in DPO while achieving significantly higher rewards under the same safety constraint compared to a recently proposed safe RLHF approach. Warning: This paper contains example data that may be offensive or harmful.
A First Order Meta Stackelberg Method for Robust Federated Learning
Jul 16, 2023Previous research has shown that federated learning (FL) systems are exposed to an array of security risks. Despite the proposal of several defensive strategies, they tend to be non-adaptive and specific to certain types of attacks, rendering them ineffective against unpredictable or adaptive threats. This work models adversarial federated learning as a Bayesian Stackelberg Markov game (BSMG) to capture the defender's incomplete information of various attack types. We propose meta-Stackelberg learning (meta-SL), a provably efficient meta-learning algorithm, to solve the equilibrium strategy in BSMG, leading to an adaptable FL defense. We demonstrate that meta-SL converges to the first-order $\varepsilon$-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations, with $O(\varepsilon^{-4})$ samples needed per iteration, matching the state of the art. Empirical evidence indicates that our meta-Stackelberg framework performs exceptionally well against potent model poisoning and backdoor attacks of an uncertain nature.
Learning to Backdoor Federated Learning
Mar 06, 2023In a federated learning (FL) system, malicious participants can easily embed backdoors into the aggregated model while maintaining the model's performance on the main task. To this end, various defenses, including training stage aggregation-based defenses and post-training mitigation defenses, have been proposed recently. While these defenses obtain reasonable performance against existing backdoor attacks, which are mainly heuristics based, we show that they are insufficient in the face of more advanced attacks. In particular, we propose a general reinforcement learning-based backdoor attack framework where the attacker first trains a (non-myopic) attack policy using a simulator built upon its local data and common knowledge on the FL system, which is then applied during actual FL training. Our attack framework is both adaptive and flexible and achieves strong attack performance and durability even under state-of-the-art defenses.
Online Learning for Adaptive Probing and Scheduling in Dense WLANs
Dec 27, 2022Existing solutions to network scheduling typically assume that the instantaneous link rates are completely known before a scheduling decision is made or consider a bandit setting where the accurate link quality is discovered only after it has been used for data transmission. In practice, the decision maker can obtain (relatively accurate) channel information, e.g., through beamforming in mmWave networks, right before data transmission. However, frequent beamforming incurs a formidable overhead in densely deployed mmWave WLANs. In this paper, we consider the important problem of throughput optimization with joint link probing and scheduling. The problem is challenging even when the link rate distributions are pre-known (the offline setting) due to the necessity of balancing the information gains from probing and the cost of reducing the data transmission opportunity. We develop an approximation algorithm with guaranteed performance when the probing decision is non-adaptive, and a dynamic programming based solution for the more challenging adaptive setting. We further extend our solutions to the online setting with unknown link rate distributions and develop a contextual-bandit based algorithm and derive its regret bound. Numerical results using data traces collected from real-world mmWave deployments demonstrate the efficiency of our solutions.
Pandering in a Flexible Representative Democracy
Nov 18, 2022
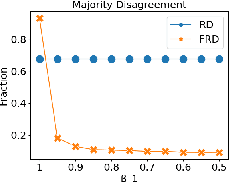

In representative democracies, the election of new representatives in regular election cycles is meant to prevent corruption and other misbehavior by elected officials and to keep them accountable in service of the ``will of the people." This democratic ideal can be undermined when candidates are dishonest when campaigning for election over these multiple cycles or rounds of voting. Much of the work on COMSOC to date has investigated strategic actions in only a single round. We introduce a novel formal model of \emph{pandering}, or strategic preference reporting by candidates seeking to be elected, and examine the resilience of two democratic voting systems to pandering within a single round and across multiple rounds. The two voting systems we compare are Representative Democracy (RD) and Flexible Representative Democracy (FRD). For each voting system, our analysis centers on the types of strategies candidates employ and how voters update their views of candidates based on how the candidates have pandered in the past. We provide theoretical results on the complexity of pandering in our setting for a single cycle, formulate our problem for multiple cycles as a Markov Decision Process, and use reinforcement learning to study the effects of pandering by both single candidates and groups of candidates across a number of rounds.