 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Safety via Constrained Direct Preference Optimization
Paper and Code



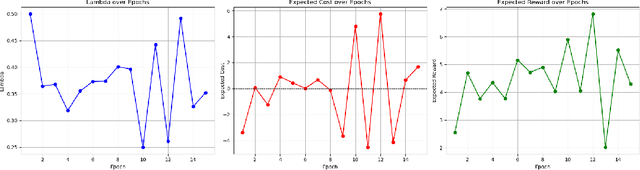
The rapidly increasing capabilities of large language models (LLMs) raise an urgent need to align AI systems with diverse human preferences to simultaneously enhance their usefulness and safety, despite the often conflicting nature of these goals. To address this important problem, a promising approach is to enforce a safety constraint at the fine-tuning stage through a constrained Reinforcement Learning from Human Feedback (RLHF) framework. This approach, however, is computationally expensive and often unstable. In this work, we introduce Constrained DPO (C-DPO), a novel extension of the recently proposed Direct Preference Optimization (DPO) approach for fine-tuning LLMs that is both efficient and lightweight. By integrating dual gradient descent and DPO, our method identifies a nearly optimal trade-off between helpfulness and harmlessness without using reinforcement learning. Empirically, our approach provides a safety guarantee to LLMs that is missing in DPO while achieving significantly higher rewards under the same safety constraint compared to a recently proposed safe RLHF approach. Warning: This paper contains example data that may be offensive or harmful.