 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Guided Adversarial State Perturbations in Reinforcement Learning
Nov 10, 2025
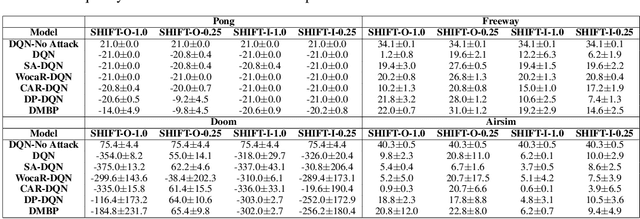


Reinforcement learning (RL) systems, while achieving remarkable success across various domains, are vulnerable to adversarial attacks. This is especially a concern in vision-based environments where minor manipulations of high-dimensional image inputs can easily mislead the agent's behavior. To this end, various defenses have been proposed recently, with state-of-the-art approaches achieving robust performance even under large state perturbations. However, after closer investigation, we found that the effectiveness of the current defenses is due to a fundamental weakness of the existing $l_p$ norm-constrained attacks, which can barely alter the semantics of image input even under a relatively large perturbation budget. In this work, we propose SHIFT, a novel policy-agnostic diffusion-based state perturbation attack to go beyond this limitation. Our attack is able to generate perturbed states that are semantically different from the true states while remaining realistic and history-aligned to avoid detection. Evaluations show that our attack effectively breaks existing defenses, including the most sophisticated ones, significantly outperforming existing attacks while being more perceptually stealthy. The results highlight the vulnerability of RL agents to semantics-aware adversarial perturbations, indicating the importance of developing more robust policies.
Belief-Enriched Pessimistic Q-Learning against Adversarial State Perturbations
Mar 06, 2024Reinforcement learning (RL) has achieved phenomenal success in various domains. However, its data-driven nature also introduces new vulnerabilities that can be exploited by malicious opponents. Recent work shows that a well-trained RL agent can be easily manipulated by strategically perturbing its state observations at the test stage. Existing solutions either introduce a regularization term to improve the smoothness of the trained policy against perturbations or alternatively train the agent's policy and the attacker's policy. However, the former does not provide sufficient protection against strong attacks, while the latter is computationally prohibitive for large environments. In this work, we propose a new robust RL algorithm for deriving a pessimistic policy to safeguard against an agent's uncertainty about true states. This approach is further enhanced with belief state inference and diffusion-based state purification to reduce uncertainty. Empirical results show that our approach obtains superb performance under strong attacks and has a comparable training overhead with regularization-based methods. Our code is available at https://github.com/SliencerX/Belief-enriched-robust-Q-learning.
Enhancing LLM Safety via Constrained Direct Preference Optimization
Mar 04, 2024


The rapidly increasing capabilities of large language models (LLMs) raise an urgent need to align AI systems with diverse human preferences to simultaneously enhance their usefulness and safety, despite the often conflicting nature of these goals. To address this important problem, a promising approach is to enforce a safety constraint at the fine-tuning stage through a constrained Reinforcement Learning from Human Feedback (RLHF) framework. This approach, however, is computationally expensive and often unstable. In this work, we introduce Constrained DPO (C-DPO), a novel extension of the recently proposed Direct Preference Optimization (DPO) approach for fine-tuning LLMs that is both efficient and lightweight. By integrating dual gradient descent and DPO, our method identifies a nearly optimal trade-off between helpfulness and harmlessness without using reinforcement learning. Empirically, our approach provides a safety guarantee to LLMs that is missing in DPO while achieving significantly higher rewards under the same safety constraint compared to a recently proposed safe RLHF approach. Warning: This paper contains example data that may be offensive or harmful.
Pandering in a Flexible Representative Democracy
Nov 18, 2022
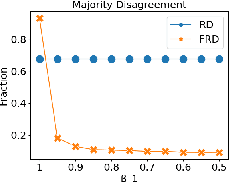

In representative democracies, the election of new representatives in regular election cycles is meant to prevent corruption and other misbehavior by elected officials and to keep them accountable in service of the ``will of the people." This democratic ideal can be undermined when candidates are dishonest when campaigning for election over these multiple cycles or rounds of voting. Much of the work on COMSOC to date has investigated strategic actions in only a single round. We introduce a novel formal model of \emph{pandering}, or strategic preference reporting by candidates seeking to be elected, and examine the resilience of two democratic voting systems to pandering within a single round and across multiple rounds. The two voting systems we compare are Representative Democracy (RD) and Flexible Representative Democracy (FRD). For each voting system, our analysis centers on the types of strategies candidates employ and how voters update their views of candidates based on how the candidates have pandered in the past. We provide theoretical results on the complexity of pandering in our setting for a single cycle, formulate our problem for multiple cycles as a Markov Decision Process, and use reinforcement learning to study the effects of pandering by both single candidates and groups of candidates across a number of rounds.
An exact solution in Markov decision process with multiplicative rewards as a general framework
Dec 15, 2020We develop an exactly solvable framework of Markov decision process with a finite horizon, and continuous state and action spaces. We first review the exact solution of conventional linear quadratic regulation with a linear transition and a Gaussian noise, whose optimal policy does not depend on the Gaussian noise, which is an undesired feature in the presence of significant noises. It motivates us to investigate exact solutions which depend on noise. To do so, we generalize the reward accumulation to be a general binary commutative and associative operation. By a new multiplicative accumulation, we obtain an exact solution of optimization assuming linear transitions with a Gaussian noise and the optimal policy is noise dependent in contrast to the additive accumulation. Furthermore, we also show that the multiplicative scheme is a general framework that covers the additive one with an arbitrary precision, which is a model-independent principle.
Leveraging Legacy Data to Accelerate Materials Design via Preference Learning
Oct 25, 2019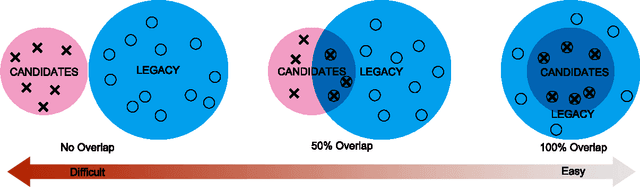
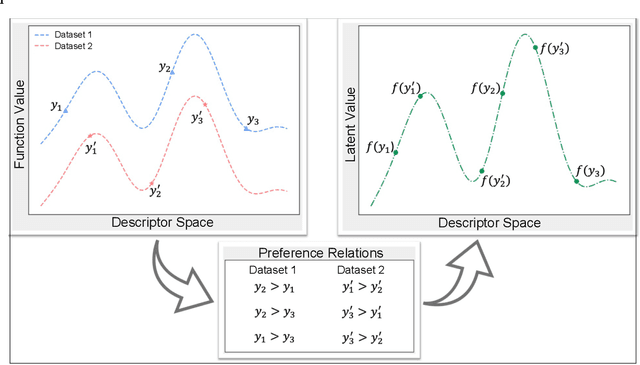

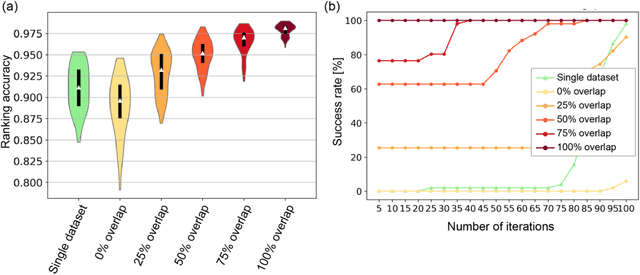
Machine learning applications in materials science are often hampered by shortage of experimental data. Integration with legacy data from past experiments is a viable way to solve the problem, but complex calibration is often necessary to use the data obtained under different conditions. In this paper, we present a novel calibration-free strategy to enhance the performance of Bayesian optimization with preference learning. The entire learning process is solely based on pairwise comparison of quantities (i.e., higher or lower) in the same dataset, and experimental design can be done without comparing quantities in different datasets. We demonstrate that Bayesian optimization is significantly enhanced via addition of legacy data for organic molecules and inorganic solid-state materials.