 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Text-Based Causal Inference to Disentangle Factors Influencing Online Review Ratings
Jun 02, 2026Online reviews provide valuable insights into the perceived quality of facets of a product or service. While aspect-based sentiment analysis has focused on extracting these facets from reviews, there is less work understanding the impact of each aspect on overall perception. This is particularly challenging given correlations among aspects, making it difficult to isolate the effects of each. This paper introduces a methodology based on recent advances in text-based causal analysis, specifically CausalBERT, to disentangle the effect of each factor on overall review ratings. We enhance CausalBERT with three key improvements: temperature scaling for better calibrated treatment assignment estimates; hyperparameter optimization to reduce confound overadjustment; and interpretability methods to characterize discovered confounds. In this work, we treat the textual mentions in reviews as proxies for real-world attributes. We validate our approach on real and semi-synthetic data from over 600K reviews of U.S. K-12 schools. We find that the proposed enhancements result in more reliable estimates, and that perception of school administration and performance on benchmarks are significant drivers of overall school ratings.
* HLT/NAACL 2025
Envy-Free but Still Unfair: Envy-Freeness Up To One Item (EF-1) in Personalized Recommendation
Sep 10, 2025Envy-freeness and the relaxation to Envy-freeness up to one item (EF-1) have been used as fairness concepts in the economics, game theory, and social choice literatures since the 1960s, and have recently gained popularity within the recommendation systems communities. In this short position paper we will give an overview of envy-freeness and its use in economics and recommendation systems; and illustrate why envy is not appropriate to measure fairness for use in settings where personalization plays a role.
The Illusion of Fairness: Auditing Fairness Interventions with Audit Studies
Jul 02, 2025Artificial intelligence systems, especially those using machine learning, are being deployed in domains from hiring to loan issuance in order to automate these complex decisions. Judging both the effectiveness and fairness of these AI systems, and their human decision making counterpart, is a complex and important topic studied across both computational and social sciences. Within machine learning, a common way to address bias in downstream classifiers is to resample the training data to offset disparities. For example, if hiring rates vary by some protected class, then one may equalize the rate within the training set to alleviate bias in the resulting classifier. While simple and seemingly effective, these methods have typically only been evaluated using data obtained through convenience samples, introducing selection bias and label bias into metrics. Within the social sciences, psychology, public health, and medicine, audit studies, in which fictitious ``testers'' (e.g., resumes, emails, patient actors) are sent to subjects (e.g., job openings, businesses, doctors) in randomized control trials, provide high quality data that support rigorous estimates of discrimination. In this paper, we investigate how data from audit studies can be used to improve our ability to both train and evaluate automated hiring algorithms. We find that such data reveals cases where the common fairness intervention method of equalizing base rates across classes appears to achieve parity using traditional measures, but in fact has roughly 10% disparity when measured appropriately. We additionally introduce interventions based on individual treatment effect estimation methods that further reduce algorithmic discrimination using this data.
Social Choice for Heterogeneous Fairness in Recommendation
Oct 06, 2024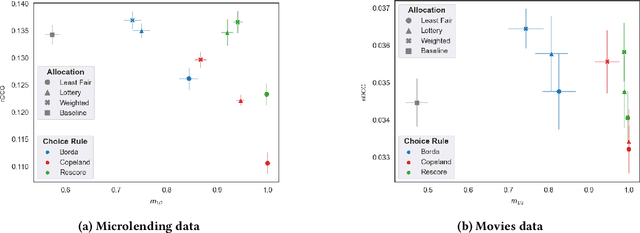
Algorithmic fairness in recommender systems requires close attention to the needs of a diverse set of stakeholders that may have competing interests. Previous work in this area has often been limited by fixed, single-objective definitions of fairness, built into algorithms or optimization criteria that are applied to a single fairness dimension or, at most, applied identically across dimensions. These narrow conceptualizations limit the ability to adapt fairness-aware solutions to the wide range of stakeholder needs and fairness definitions that arise in practice. Our work approaches recommendation fairness from the standpoint of computational social choice, using a multi-agent framework. In this paper, we explore the properties of different social choice mechanisms and demonstrate the successful integration of multiple, heterogeneous fairness definitions across multiple data sets.
Data Generation via Latent Factor Simulation for Fairness-aware Re-ranking
Sep 21, 2024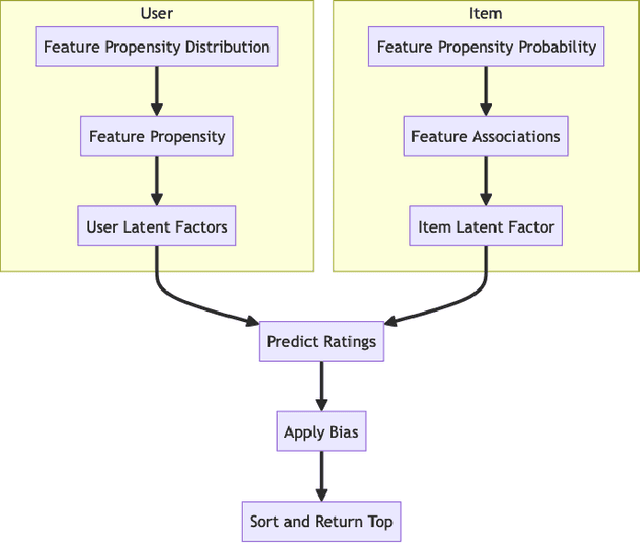

Synthetic data is a useful resource for algorithmic research. It allows for the evaluation of systems under a range of conditions that might be difficult to achieve in real world settings. In recommender systems, the use of synthetic data is somewhat limited; some work has concentrated on building user-item interaction data at large scale. We believe that fairness-aware recommendation research can benefit from simulated data as it allows the study of protected groups and their interactions without depending on sensitive data that needs privacy protection. In this paper, we propose a novel type of data for fairness-aware recommendation: synthetic recommender system outputs that can be used to study re-ranking algorithms.
DeepVoting: Learning Voting Rules with Tailored Embeddings
Aug 24, 2024



Aggregating the preferences of multiple agents into a collective decision is a common step in many important problems across areas of computer science including information retrieval, reinforcement learning, and recommender systems. As Social Choice Theory has shown, the problem of designing algorithms for aggregation rules with specific properties (axioms) can be difficult, or provably impossible in some cases. Instead of designing algorithms by hand, one can learn aggregation rules, particularly voting rules, from data. However, the prior work in this area has required extremely large models, or been limited by the choice of preference representation, i.e., embedding. We recast the problem of designing a good voting rule into one of learning probabilistic versions of voting rules that output distributions over a set of candidates. Specifically, we use neural networks to learn probabilistic social choice functions from the literature. We show that embeddings of preference profiles derived from the social choice literature allows us to learn existing voting rules more efficiently and scale to larger populations of voters more easily than other work if the embedding is tailored to the learning objective. Moreover, we show that rules learned using embeddings can be tweaked to create novel voting rules with improved axiomatic properties. Namely, we show that existing voting rules require only minor modification to combat a probabilistic version of the No Show Paradox.
Exploring Social Choice Mechanisms for Recommendation Fairness in SCRUF
Sep 10, 2023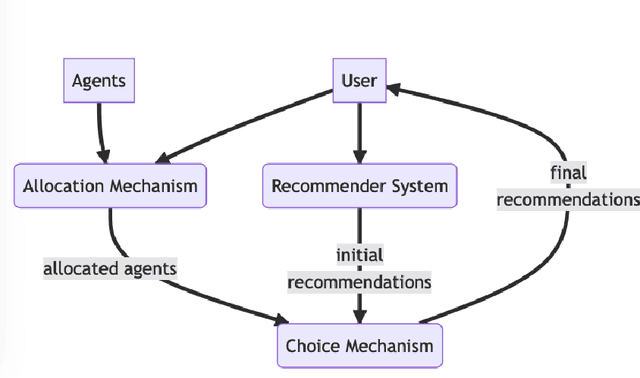
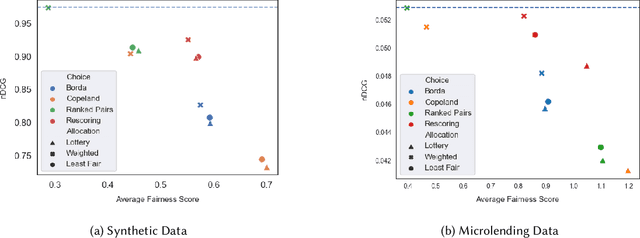
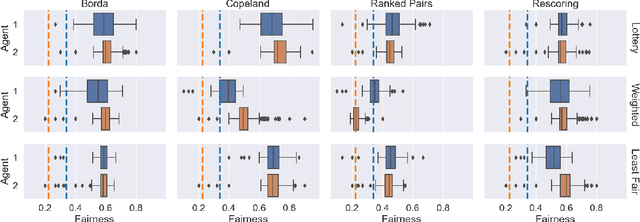
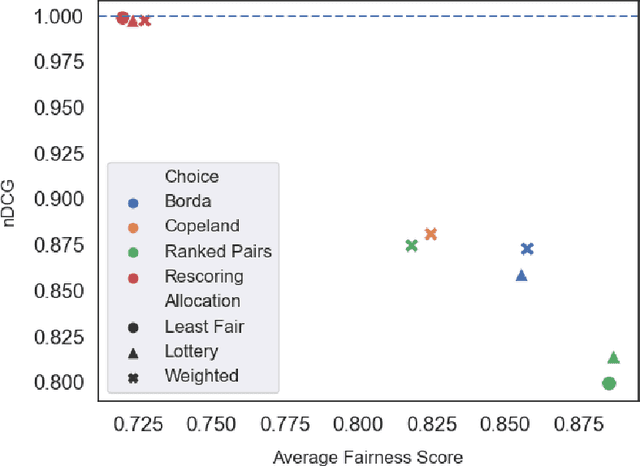
Fairness problems in recommender systems often have a complexity in practice that is not adequately captured in simplified research formulations. A social choice formulation of the fairness problem, operating within a multi-agent architecture of fairness concerns, offers a flexible and multi-aspect alternative to fairness-aware recommendation approaches. Leveraging social choice allows for increased generality and the possibility of tapping into well-studied social choice algorithms for resolving the tension between multiple, competing fairness concerns. This paper explores a range of options for choice mechanisms in multi-aspect fairness applications using both real and synthetic data and shows that different classes of choice and allocation mechanisms yield different but consistent fairness / accuracy tradeoffs. We also show that a multi-agent formulation offers flexibility in adapting to user population dynamics.
Value-based Fast and Slow AI Nudging
Jul 14, 2023



Nudging is a behavioral strategy aimed at influencing people's thoughts and actions. Nudging techniques can be found in many situations in our daily lives, and these nudging techniques can targeted at human fast and unconscious thinking, e.g., by using images to generate fear or the more careful and effortful slow thinking, e.g., by releasing information that makes us reflect on our choices. In this paper, we propose and discuss a value-based AI-human collaborative framework where AI systems nudge humans by proposing decision recommendations. Three different nudging modalities, based on when recommendations are presented to the human, are intended to stimulate human fast thinking, slow thinking, or meta-cognition. Values that are relevant to a specific decision scenario are used to decide when and how to use each of these nudging modalities. Examples of values are decision quality, speed, human upskilling and learning, human agency, and privacy. Several values can be present at the same time, and their priorities can vary over time. The framework treats values as parameters to be instantiated in a specific decision environment.
Dynamic fairness-aware recommendation through multi-agent social choice
Mar 03, 2023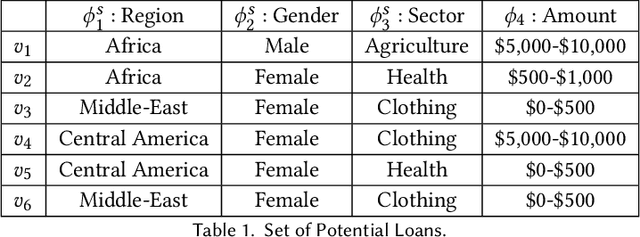


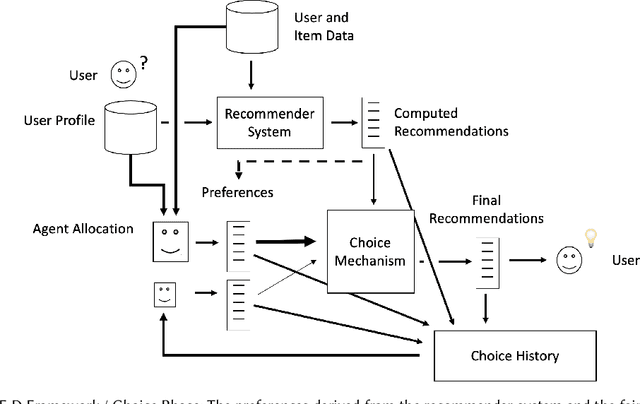
Algorithmic fairness in the context of personalized recommendation presents significantly different challenges to those commonly encountered in classification tasks. Researchers studying classification have generally considered fairness to be a matter of achieving equality of outcomes between a protected and unprotected group, and built algorithmic interventions on this basis. We argue that fairness in real-world application settings in general, and especially in the context of personalized recommendation, is much more complex and multi-faceted, requiring a more general approach. We propose a model to formalize multistakeholder fairness in recommender systems as a two stage social choice problem. In particular, we express recommendation fairness as a novel combination of an allocation and an aggregation problem, which integrate both fairness concerns and personalized recommendation provisions, and derive new recommendation techniques based on this formulation. Simulations demonstrate the ability of the framework to integrate multiple fairness concerns in a dynamic way.
Pandering in a Flexible Representative Democracy
Nov 18, 2022
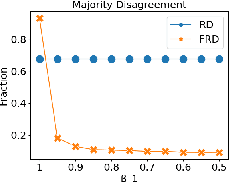

In representative democracies, the election of new representatives in regular election cycles is meant to prevent corruption and other misbehavior by elected officials and to keep them accountable in service of the ``will of the people." This democratic ideal can be undermined when candidates are dishonest when campaigning for election over these multiple cycles or rounds of voting. Much of the work on COMSOC to date has investigated strategic actions in only a single round. We introduce a novel formal model of \emph{pandering}, or strategic preference reporting by candidates seeking to be elected, and examine the resilience of two democratic voting systems to pandering within a single round and across multiple rounds. The two voting systems we compare are Representative Democracy (RD) and Flexible Representative Democracy (FRD). For each voting system, our analysis centers on the types of strategies candidates employ and how voters update their views of candidates based on how the candidates have pandered in the past. We provide theoretical results on the complexity of pandering in our setting for a single cycle, formulate our problem for multiple cycles as a Markov Decision Process, and use reinforcement learning to study the effects of pandering by both single candidates and groups of candidates across a number of rounds.