 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Fairness: Auditing Fairness Interventions with Audit Studies
Jul 02, 2025Artificial intelligence systems, especially those using machine learning, are being deployed in domains from hiring to loan issuance in order to automate these complex decisions. Judging both the effectiveness and fairness of these AI systems, and their human decision making counterpart, is a complex and important topic studied across both computational and social sciences. Within machine learning, a common way to address bias in downstream classifiers is to resample the training data to offset disparities. For example, if hiring rates vary by some protected class, then one may equalize the rate within the training set to alleviate bias in the resulting classifier. While simple and seemingly effective, these methods have typically only been evaluated using data obtained through convenience samples, introducing selection bias and label bias into metrics. Within the social sciences, psychology, public health, and medicine, audit studies, in which fictitious ``testers'' (e.g., resumes, emails, patient actors) are sent to subjects (e.g., job openings, businesses, doctors) in randomized control trials, provide high quality data that support rigorous estimates of discrimination. In this paper, we investigate how data from audit studies can be used to improve our ability to both train and evaluate automated hiring algorithms. We find that such data reveals cases where the common fairness intervention method of equalizing base rates across classes appears to achieve parity using traditional measures, but in fact has roughly 10% disparity when measured appropriately. We additionally introduce interventions based on individual treatment effect estimation methods that further reduce algorithmic discrimination using this data.
Leaders or Followers? A Temporal Analysis of Tweets from IRA Trolls
Apr 04, 2022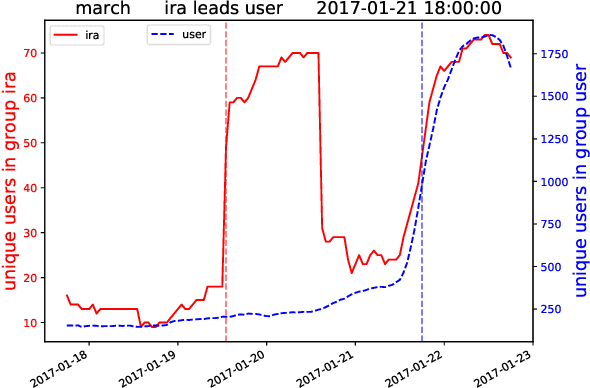
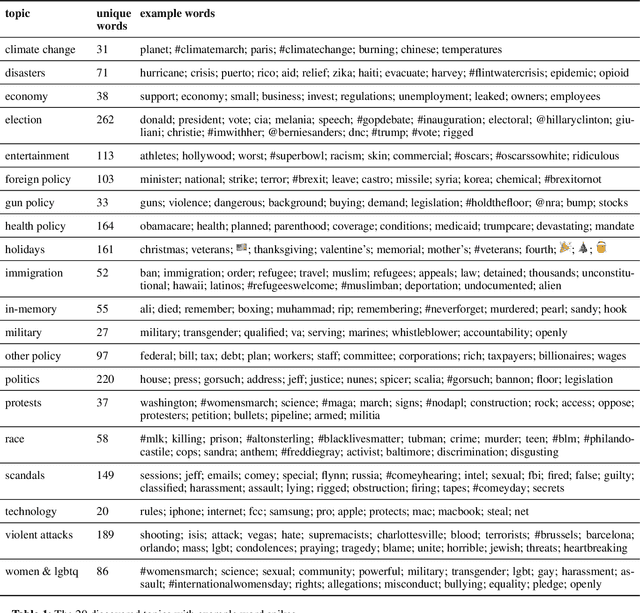
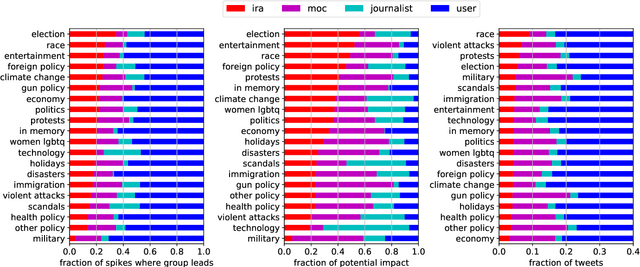
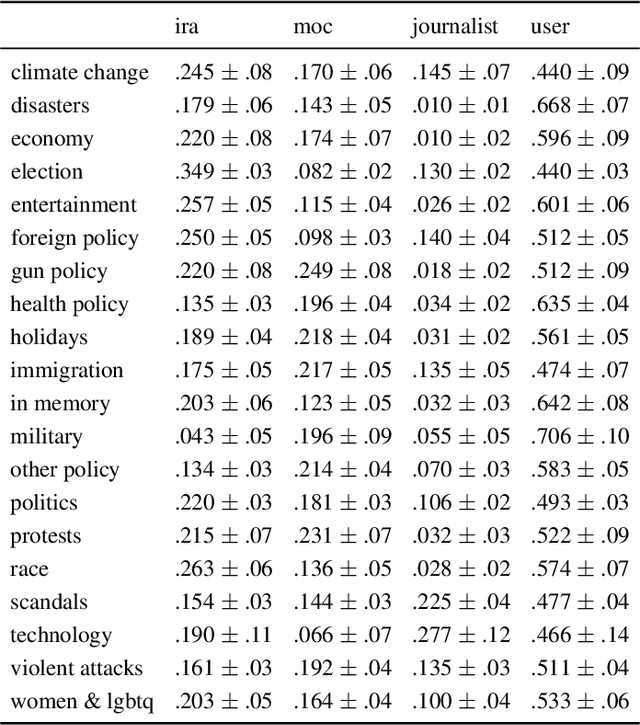
The Internet Research Agency (IRA) influences online political conversations in the United States, exacerbating existing partisan divides and sowing discord. In this paper we investigate the IRA's communication strategies by analyzing trending terms on Twitter to identify cases in which the IRA leads or follows other users. Our analysis focuses on over 38M tweets posted between 2016 and 2017 from IRA users (n=3,613), journalists (n=976), members of Congress (n=526), and politically engaged users from the general public (n=71,128). We find that the IRA tends to lead on topics related to the 2016 election, race, and entertainment, suggesting that these are areas both of strategic importance as well having the highest potential impact. Furthermore, we identify topics where the IRA has been relatively ineffective, such as tweets on military, political scandals, and violent attacks. Despite many tweets on these topics, the IRA rarely leads the conversation and thus has little opportunity to influence it. We offer our proposed methodology as a way to track the strategic choices of future influence operations in real-time.
Enhancing Model Robustness and Fairness with Causality: A Regularization Approach
Oct 03, 2021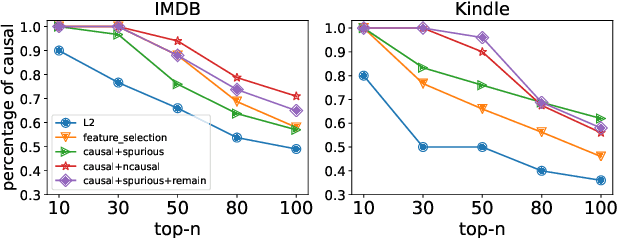
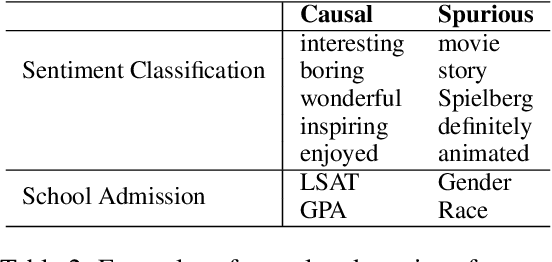

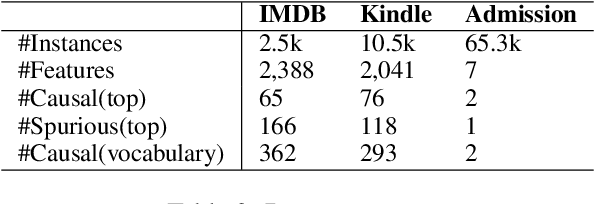
Recent work has raised concerns on the risk of spurious correlations and unintended biases in statistical machine learning models that threaten model robustness and fairness. In this paper, we propose a simple and intuitive regularization approach to integrate causal knowledge during model training and build a robust and fair model by emphasizing causal features and de-emphasizing spurious features. Specifically, we first manually identify causal and spurious features with principles inspired from the counterfactual framework of causal inference. Then, we propose a regularization approach to penalize causal and spurious features separately. By adjusting the strength of the penalty for each type of feature, we build a predictive model that relies more on causal features and less on non-causal features. We conduct experiments to evaluate model robustness and fairness on three datasets with multiple metrics. Empirical results show that the new models built with causal awareness significantly improve model robustness with respect to counterfactual texts and model fairness with respect to sensitive attributes.
Robustness to Spurious Correlations in Text Classification via Automatically Generated Counterfactuals
Dec 18, 2020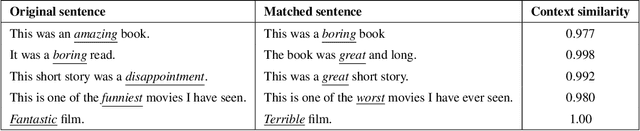
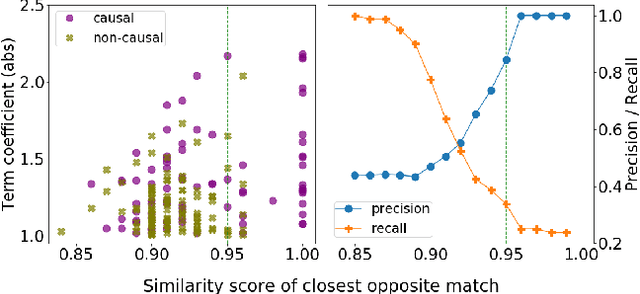


Spurious correlations threaten the validity of statistical classifiers. While model accuracy may appear high when the test data is from the same distribution as the training data, it can quickly degrade when the test distribution changes. For example, it has been shown that classifiers perform poorly when humans make minor modifications to change the label of an example. One solution to increase model reliability and generalizability is to identify causal associations between features and classes. In this paper, we propose to train a robust text classifier by augmenting the training data with automatically generated counterfactual data. We first identify likely causal features using a statistical matching approach. Next, we generate counterfactual samples for the original training data by substituting causal features with their antonyms and then assigning opposite labels to the counterfactual samples. Finally, we combine the original data and counterfactual data to train a robust classifier. Experiments on two classification tasks show that a traditional classifier trained on the original data does very poorly on human-generated counterfactual samples (e.g., 10%-37% drop in accuracy). However, the classifier trained on the combined data is more robust and performs well on both the original test data and the counterfactual test data (e.g., 12%-25% increase in accuracy compared with the traditional classifier). Detailed analysis shows that the robust classifier makes meaningful and trustworthy predictions by emphasizing causal features and de-emphasizing non-causal features.
Are Words Commensurate with Actions? Quantifying Commitment to a Cause from Online Public Messaging
Oct 06, 2020

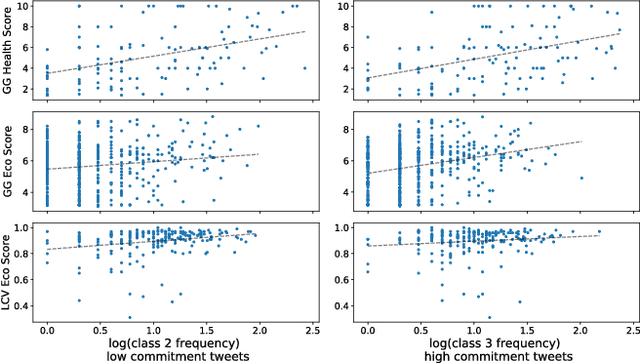

Public entities such as companies and politicians increasingly use online social networks to communicate directly with their constituencies. Often, this public messaging is aimed at aligning the entity with a particular cause or issue, such as the environment or public health. However, as a consumer or voter, it can be difficult to assess an entity's true commitment to a cause based on public messaging. In this paper, we present a text classification approach to categorize a message according to its commitment level toward a cause. We then compare the volume of such messages with external ratings based on entities' actions (e.g., a politician's voting record with respect to the environment or a company's rating from environmental non-profits). We find that by distinguishing between low- and high- level commitment messages, we can more reliably identify truly committed entities. Furthermore, by measuring the discrepancy between classified messages and external ratings, we can identify entities whose public messaging does not align with their actions, thereby providing a methodology to identify potentially "inauthentic" messaging campaigns.
Identifying Spurious Correlations for Robust Text Classification
Oct 06, 2020



The predictions of text classifiers are often driven by spurious correlations -- e.g., the term `Spielberg' correlates with positively reviewed movies, even though the term itself does not semantically convey a positive sentiment. In this paper, we propose a method to distinguish spurious and genuine correlations in text classification. We treat this as a supervised classification problem, using features derived from treatment effect estimators to distinguish spurious correlations from "genuine" ones. Due to the generic nature of these features and their small dimensionality, we find that the approach works well even with limited training examples, and that it is possible to transport the word classifier to new domains. Experiments on four datasets (sentiment classification and toxicity detection) suggest that using this approach to inform feature selection also leads to more robust classification, as measured by improved worst-case accuracy on the samples affected by spurious correlations.
* Findings of EMNLP-2020
When do Words Matter? Understanding the Impact of Lexical Choice on Audience Perception using Individual Treatment Effect Estimation
Nov 15, 2018



Studies across many disciplines have shown that lexical choice can affect audience perception. For example, how users describe themselves in a social media profile can affect their perceived socio-economic status. However, we lack general methods for estimating the causal effect of lexical choice on the perception of a specific sentence. While randomized controlled trials may provide good estimates, they do not scale to the potentially millions of comparisons necessary to consider all lexical choices. Instead, in this paper, we first offer two classes of methods to estimate the effect on perception of changing one word to another in a given sentence. The first class of algorithms builds upon quasi-experimental designs to estimate individual treatment effects from observational data. The second class treats treatment effect estimation as a classification problem. We conduct experiments with three data sources (Yelp, Twitter, and Airbnb), finding that the algorithmic estimates align well with those produced by randomized-control trials. Additionally, we find that it is possible to transfer treatment effect classifiers across domains and still maintain high accuracy.
Forecasting the presence and intensity of hostility on Instagram using linguistic and social features
Apr 18, 2018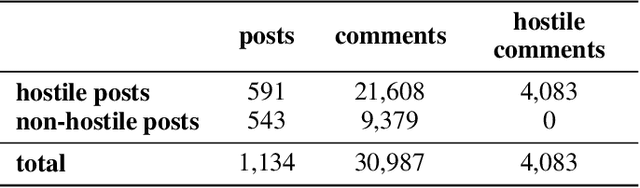

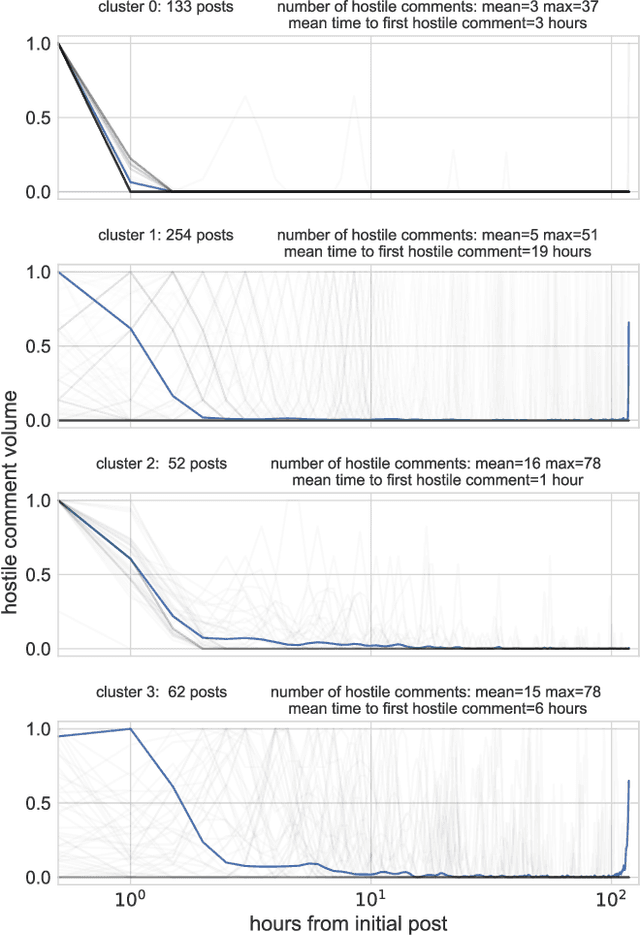

Online antisocial behavior, such as cyberbullying, harassment, and trolling, is a widespread problem that threatens free discussion and has negative physical and mental health consequences for victims and communities. While prior work has proposed automated methods to identify hostile comments in online discussions, these methods work retrospectively on comments that have already been posted, making it difficult to intervene before an interaction escalates. In this paper we instead consider the problem of forecasting future hostilities in online discussions, which we decompose into two tasks: (1) given an initial sequence of non-hostile comments in a discussion, predict whether some future comment will contain hostility; and (2) given the first hostile comment in a discussion, predict whether this will lead to an escalation of hostility in subsequent comments. Thus, we aim to forecast both the presence and intensity of hostile comments based on linguistic and social features from earlier comments. To evaluate our approach, we introduce a corpus of over 30K annotated Instagram comments from over 1,100 posts. Our approach is able to predict the appearance of a hostile comment on an Instagram post ten or more hours in the future with an AUC of .82 (task 1), and can furthermore distinguish between high and low levels of future hostility with an AUC of .91 (task 2).
Controlling for Unobserved Confounds in Classification Using Correlational Constraints
Jan 11, 2018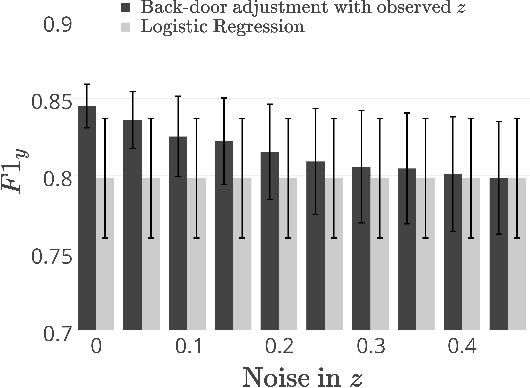

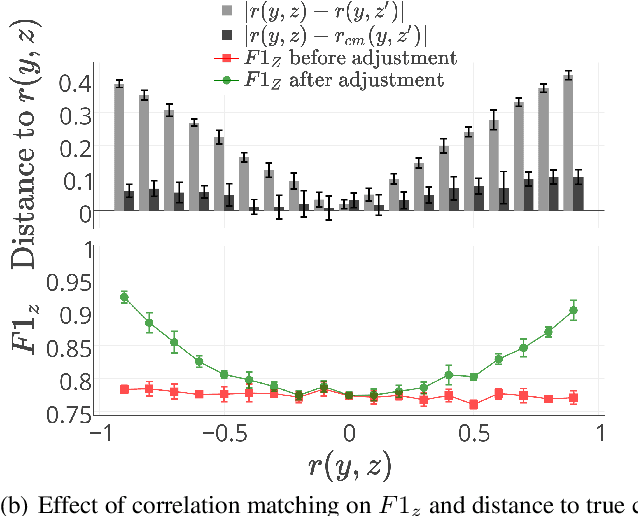
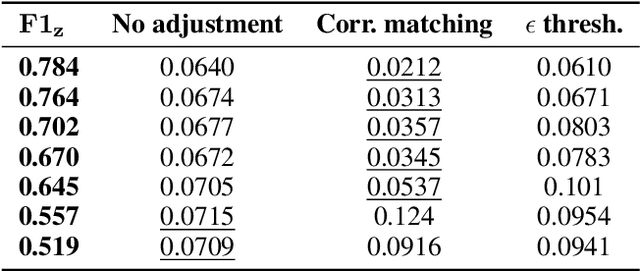
As statistical classifiers become integrated into real-world applications, it is important to consider not only their accuracy but also their robustness to changes in the data distribution. In this paper, we consider the case where there is an unobserved confounding variable $z$ that influences both the features $\mathbf{x}$ and the class variable $y$. When the influence of $z$ changes from training to testing data, we find that the classifier accuracy can degrade rapidly. In our approach, we assume that we can predict the value of $z$ at training time with some error. The prediction for $z$ is then fed to Pearl's back-door adjustment to build our model. Because of the attenuation bias caused by measurement error in $z$, standard approaches to controlling for $z$ are ineffective. In response, we propose a method to properly control for the influence of $z$ by first estimating its relationship with the class variable $y$, then updating predictions for $z$ to match that estimated relationship. By adjusting the influence of $z$, we show that we can build a model that exceeds competing baselines on accuracy as well as on robustness over a range of confounding relationships.
Co-training for Demographic Classification Using Deep Learning from Label Proportions
Sep 13, 2017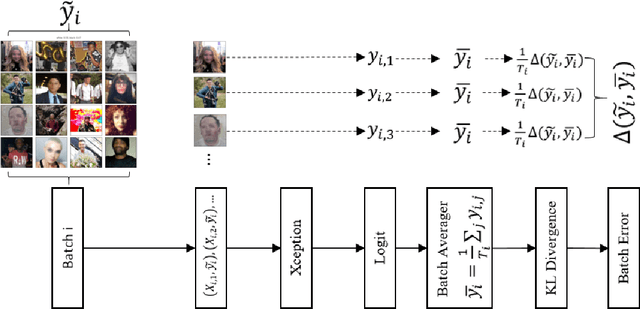


Deep learning algorithms have recently produced state-of-the-art accuracy in many classification tasks, but this success is typically dependent on access to many annotated training examples. For domains without such data, an attractive alternative is to train models with light, or distant supervision. In this paper, we introduce a deep neural network for the Learning from Label Proportion (LLP) setting, in which the training data consist of bags of unlabeled instances with associated label distributions for each bag. We introduce a new regularization layer, Batch Averager, that can be appended to the last layer of any deep neural network to convert it from supervised learning to LLP. This layer can be implemented readily with existing deep learning packages. To further support domains in which the data consist of two conditionally independent feature views (e.g. image and text), we propose a co-training algorithm that iteratively generates pseudo bags and refits the deep LLP model to improve classification accuracy. We demonstrate our models on demographic attribute classification (gender and race/ethnicity), which has many applications in social media analysis, public health, and marketing. We conduct experiments to predict demographics of Twitter users based on their tweets and profile image, without requiring any user-level annotations for training. We find that the deep LLP approach outperforms baselines for both text and image features separately. Additionally, we find that co-training algorithm improves image and text classification by 4% and 8% absolute F1, respectively. Finally, an ensemble of text and image classifiers further improves the absolute F1 measure by 4% on average.