 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness to Spurious Correlations in Text Classification via Automatically Generated Counterfactuals
Paper and Code
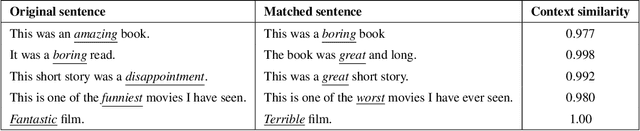
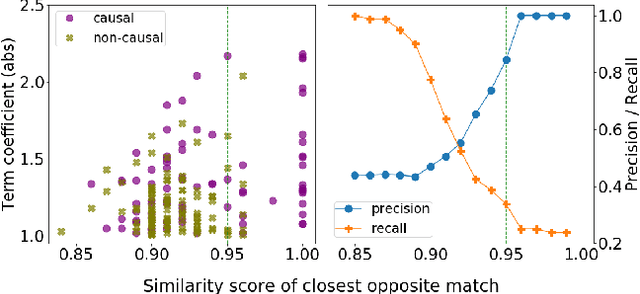


Spurious correlations threaten the validity of statistical classifiers. While model accuracy may appear high when the test data is from the same distribution as the training data, it can quickly degrade when the test distribution changes. For example, it has been shown that classifiers perform poorly when humans make minor modifications to change the label of an example. One solution to increase model reliability and generalizability is to identify causal associations between features and classes. In this paper, we propose to train a robust text classifier by augmenting the training data with automatically generated counterfactual data. We first identify likely causal features using a statistical matching approach. Next, we generate counterfactual samples for the original training data by substituting causal features with their antonyms and then assigning opposite labels to the counterfactual samples. Finally, we combine the original data and counterfactual data to train a robust classifier. Experiments on two classification tasks show that a traditional classifier trained on the original data does very poorly on human-generated counterfactual samples (e.g., 10%-37% drop in accuracy). However, the classifier trained on the combined data is more robust and performs well on both the original test data and the counterfactual test data (e.g., 12%-25% increase in accuracy compared with the traditional classifier). Detailed analysis shows that the robust classifier makes meaningful and trustworthy predictions by emphasizing causal features and de-emphasizing non-causal features.