 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring the Origin Locations of Tweets with Quantitative Confidence
Paper and Code
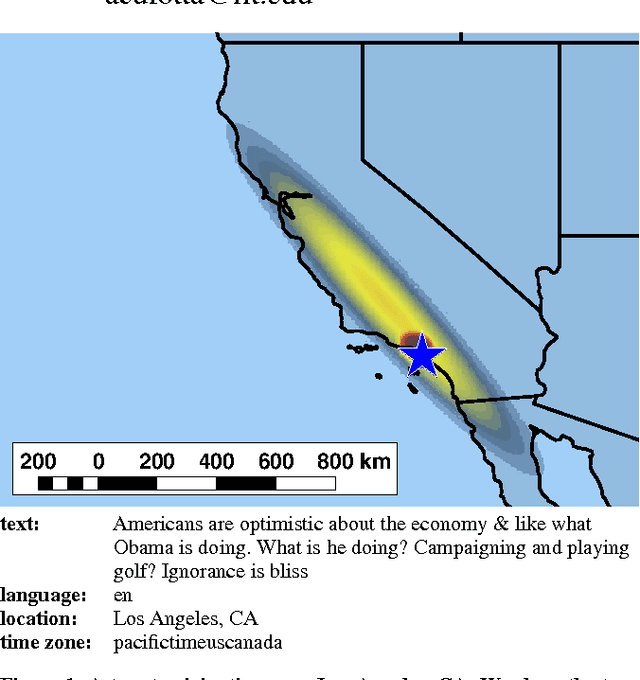
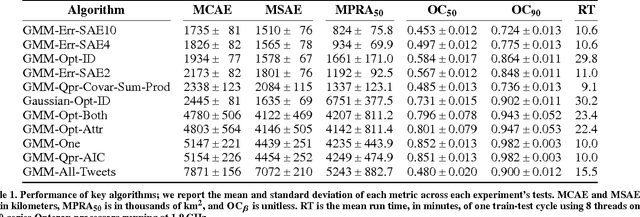
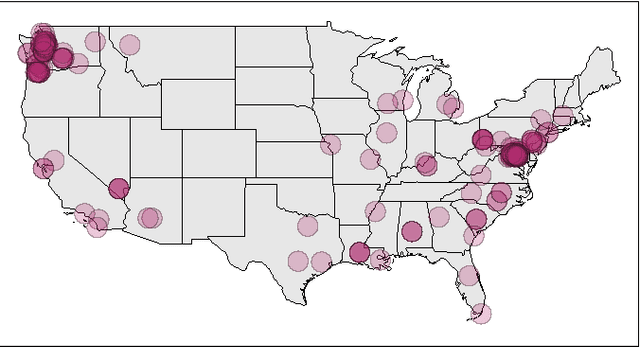
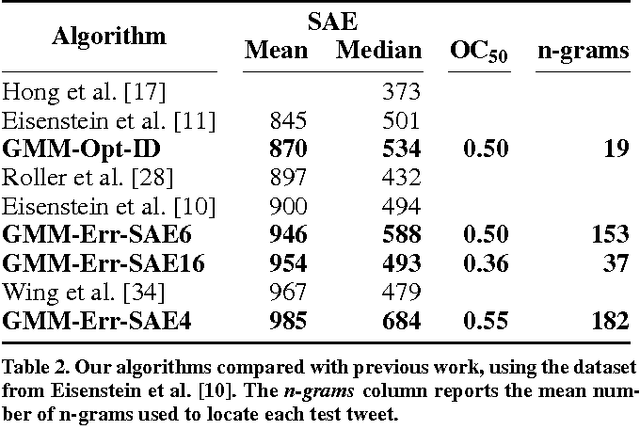
Social Internet content plays an increasingly critical role in many domains, including public health, disaster management, and politics. However, its utility is limited by missing geographic information; for example, fewer than 1.6% of Twitter messages (tweets) contain a geotag. We propose a scalable, content-based approach to estimate the location of tweets using a novel yet simple variant of gaussian mixture models. Further, because real-world applications depend on quantified uncertainty for such estimates, we propose novel metrics of accuracy, precision, and calibration, and we evaluate our approach accordingly. Experiments on 13 million global, comprehensively multi-lingual tweets show that our approach yields reliable, well-calibrated results competitive with previous computationally intensive methods. We also show that a relatively small number of training data are required for good estimates (roughly 30,000 tweets) and models are quite time-invariant (effective on tweets many weeks newer than the training set). Finally, we show that toponyms and languages with small geographic footprint provide the most useful location signals.