 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of COVID-19 Policies and Misinformation on Social Unrest
Oct 07, 2021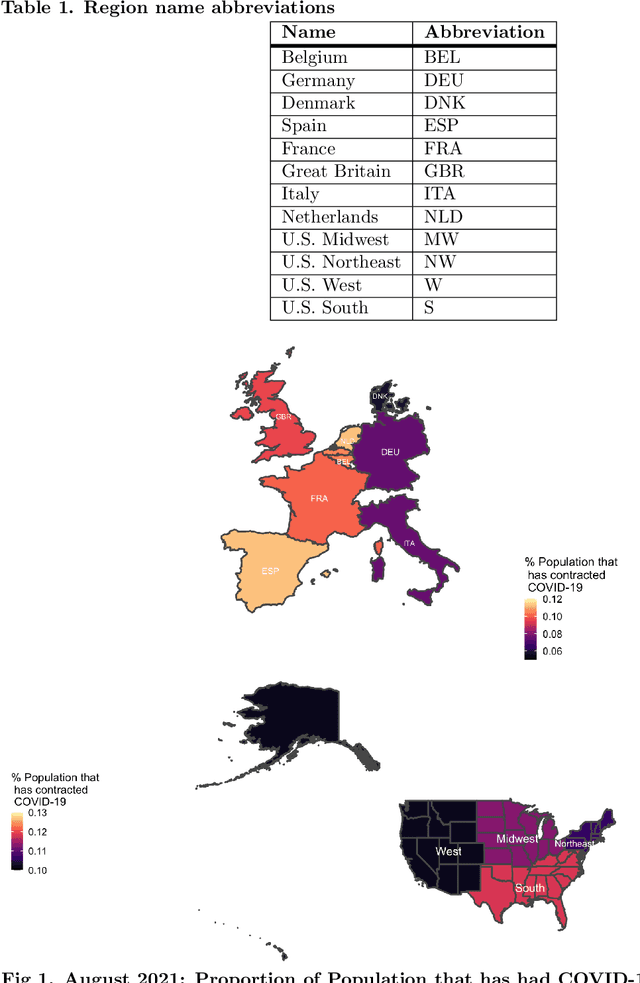
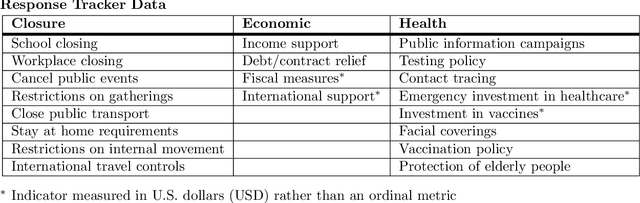
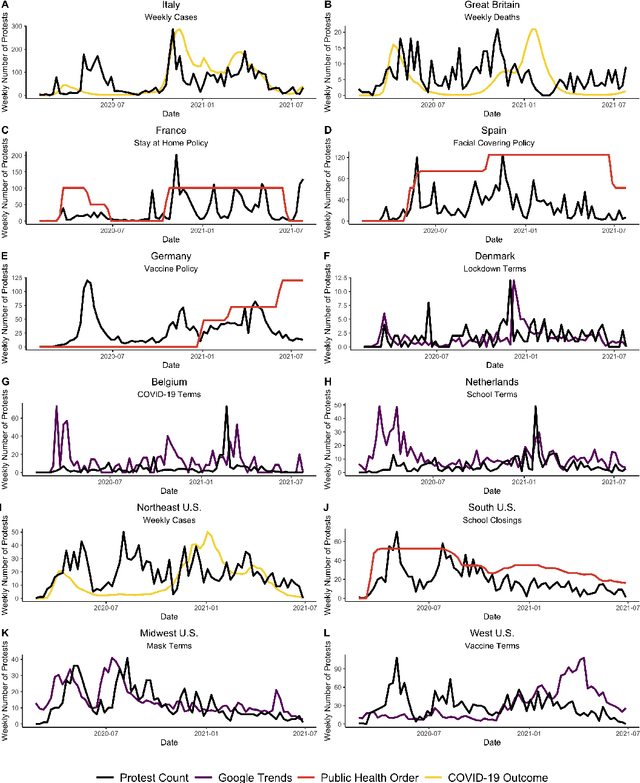
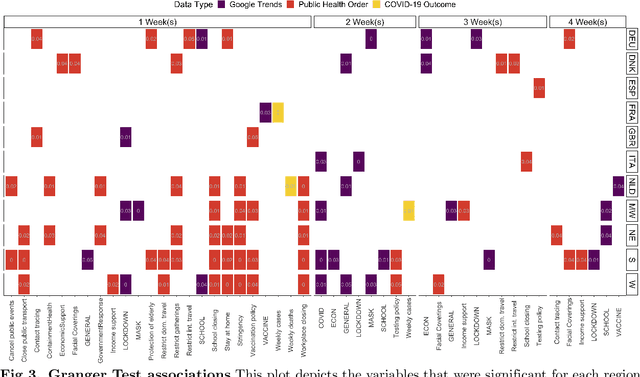
The novel coronavirus disease (COVID-19) pandemic has impacted every corner of earth, disrupting governments and leading to socioeconomic instability. This crisis has prompted questions surrounding how different sectors of society interact and influence each other during times of change and stress. Given the unprecedented economic and societal impacts of this pandemic, many new data sources have become available, allowing us to quantitatively explore these associations. Understanding these relationships can help us better prepare for future disasters and mitigate the impacts. Here, we focus on the interplay between social unrest (protests), health outcomes, public health orders, and misinformation in eight countries of Western Europe and four regions of the United States. We created 1-3 week forecasts of both a binary protest metric for identifying times of high protest activity and the overall protest counts over time. We found that for all regions, except Belgium, at least one feature from our various data streams was predictive of protests. However, the accuracy of the protest forecasts varied by country, that is, for roughly half of the countries analyzed, our forecasts outperform a na\"ive model. These mixed results demonstrate the potential of diverse data streams to predict a topic as volatile as protests as well as the difficulties of predicting a situation that is as rapidly evolving as a pandemic.
Machine Learning-Powered Mitigation Policy Optimization in Epidemiological Models
Oct 16, 2020
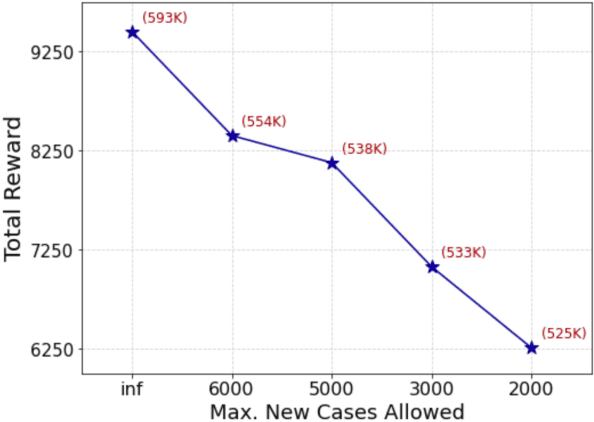

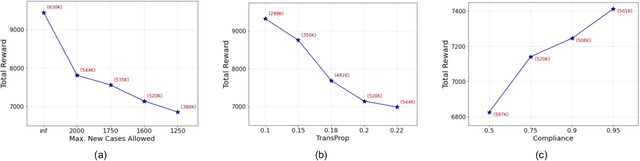
A crucial aspect of managing a public health crisis is to effectively balance prevention and mitigation strategies, while taking their socio-economic impact into account. In particular, determining the influence of different non-pharmaceutical interventions (NPIs) on the effective use of public resources is an important problem, given the uncertainties on when a vaccine will be made available. In this paper, we propose a new approach for obtaining optimal policy recommendations based on epidemiological models, which can characterize the disease progression under different interventions, and a look-ahead reward optimization strategy to choose the suitable NPI at different stages of an epidemic. Given the time delay inherent in any epidemiological model and the exponential nature especially of an unmanaged epidemic, we find that such a look-ahead strategy infers non-trivial policies that adhere well to the constraints specified. Using two different epidemiological models, namely SEIR and EpiCast, we evaluate the proposed algorithm to determine the optimal NPI policy, under a constraint on the number of daily new cases and the primary reward being the absence of restrictions.
Accurate Calibration of Agent-based Epidemiological Models with Neural Network Surrogates
Oct 13, 2020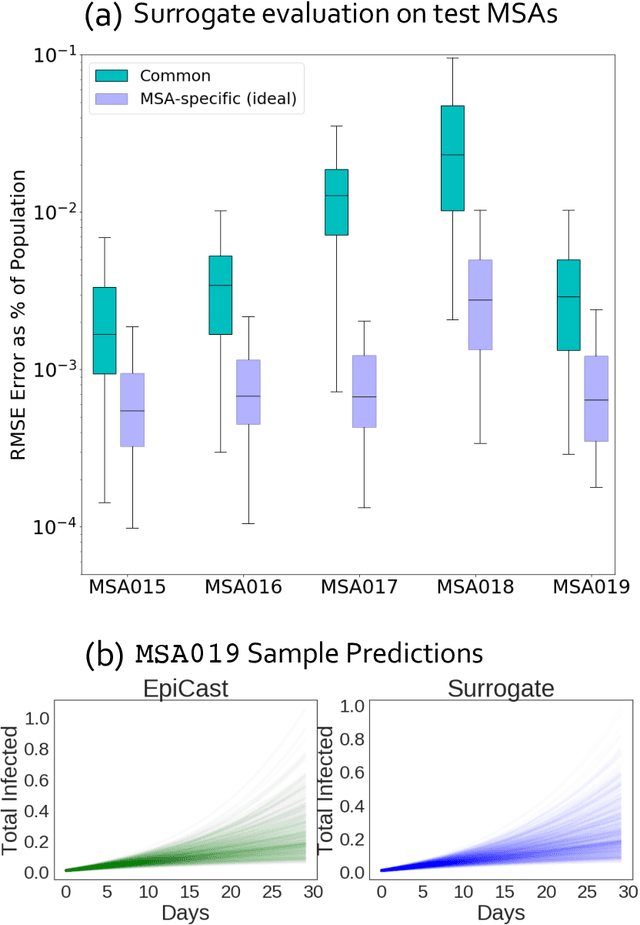

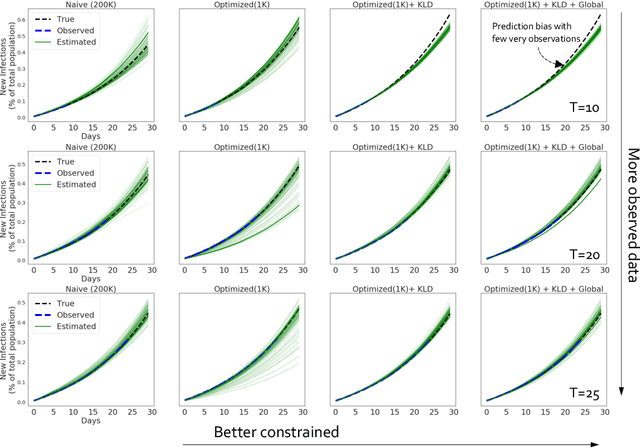

Calibrating complex epidemiological models to observed data is a crucial step to provide both insights into the current disease dynamics, i.e.\ by estimating a reproductive number, as well as to provide reliable forecasts and scenario explorations. Here we present a new approach to calibrate an agent-based model -- EpiCast -- using a large set of simulation ensembles for different major metropolitan areas of the United States. In particular, we propose: a new neural network based surrogate model able to simultaneously emulate all different locations; and a novel posterior estimation that provides not only more accurate posterior estimates of all parameters but enables the joint fitting of global parameters across regions.
Eliciting Disease Data from Wikipedia Articles
Aug 24, 2015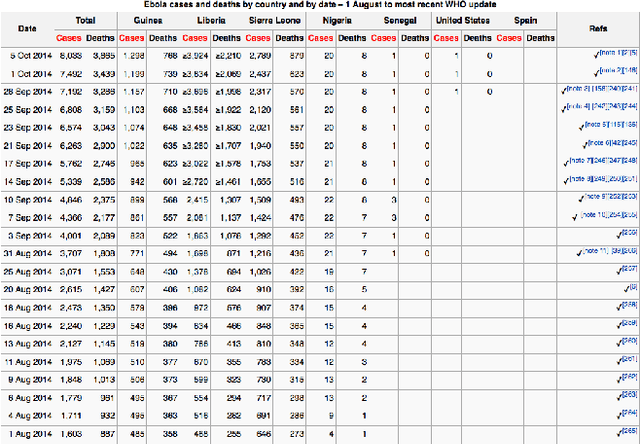

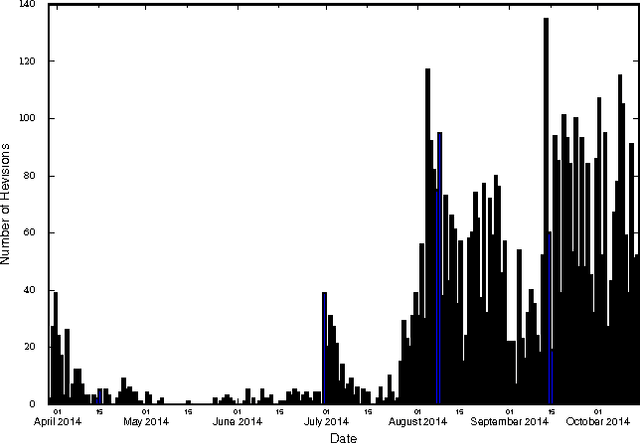
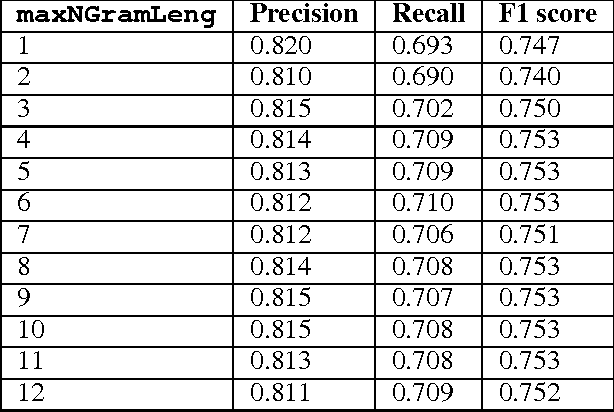
Traditional disease surveillance systems suffer from several disadvantages, including reporting lags and antiquated technology, that have caused a movement towards internet-based disease surveillance systems. Internet systems are particularly attractive for disease outbreaks because they can provide data in near real-time and can be verified by individuals around the globe. However, most existing systems have focused on disease monitoring and do not provide a data repository for policy makers or researchers. In order to fill this gap, we analyzed Wikipedia article content. We demonstrate how a named-entity recognizer can be trained to tag case counts, death counts, and hospitalization counts in the article narrative that achieves an F1 score of 0.753. We also show, using the 2014 West African Ebola virus disease epidemic article as a case study, that there are detailed time series data that are consistently updated that closely align with ground truth data. We argue that Wikipedia can be used to create the first community-driven open-source emerging disease detection, monitoring, and repository system.
Quantifying Uncertainty in Stochastic Models with Parametric Variability
Mar 04, 2015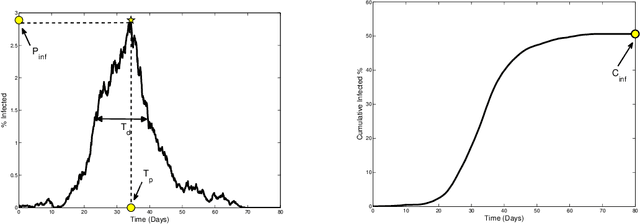
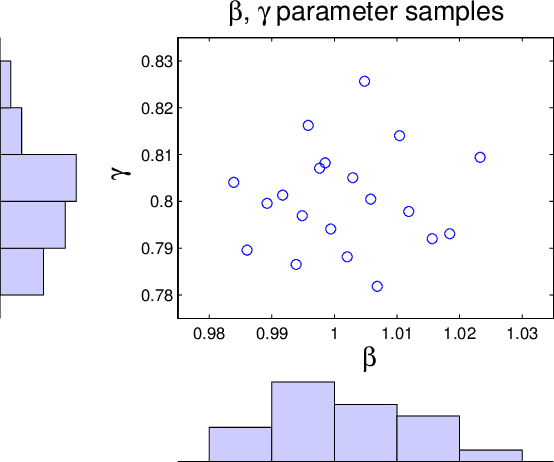
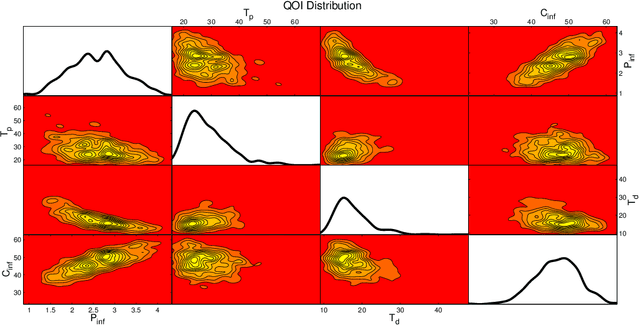
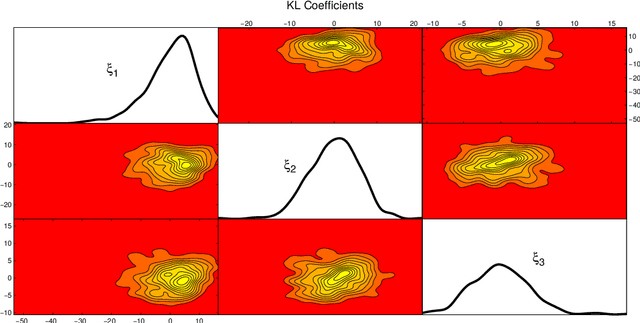
We present a method to quantify uncertainty in the predictions made by simulations of mathematical models that can be applied to a broad class of stochastic, discrete, and differential equation models. Quantifying uncertainty is crucial for determining how accurate the model predictions are and identifying which input parameters affect the outputs of interest. Most of the existing methods for uncertainty quantification require many samples to generate accurate results, are unable to differentiate where the uncertainty is coming from (e.g., parameters or model assumptions), or require a lot of computational resources. Our approach addresses these challenges and opportunities by allowing different types of uncertainty, that is, uncertainty in input parameters as well as uncertainty created through stochastic model components. This is done by combining the Karhunen-Loeve decomposition, polynomial chaos expansion, and Bayesian Gaussian process regression to create a statistical surrogate for the stochastic model. The surrogate separates the analysis of variation arising through stochastic simulation and variation arising through uncertainty in the model parameterization. We illustrate our approach by quantifying the uncertainty in a stochastic ordinary differential equation epidemic model. Specifically, we estimate four quantities of interest for the epidemic model and show agreement between the surrogate and the actual model results.
Global disease monitoring and forecasting with Wikipedia
Jul 15, 2014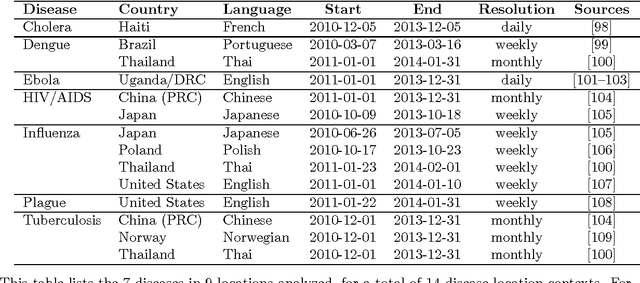
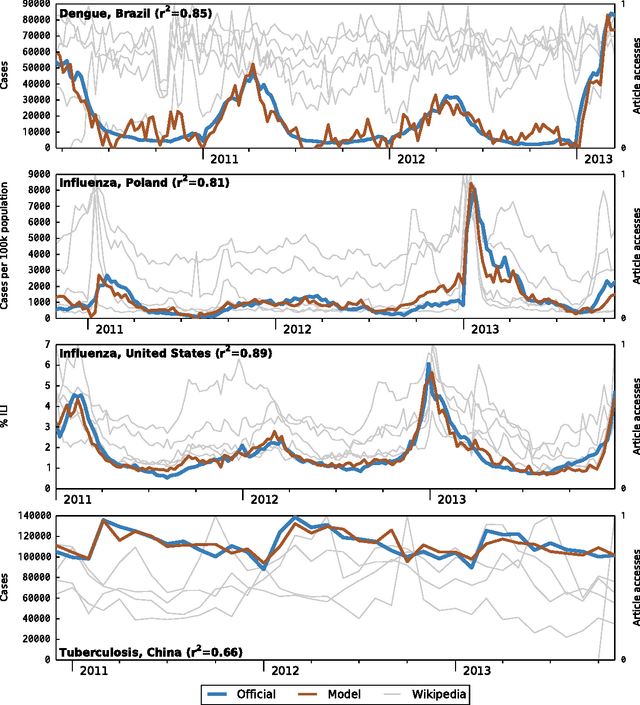

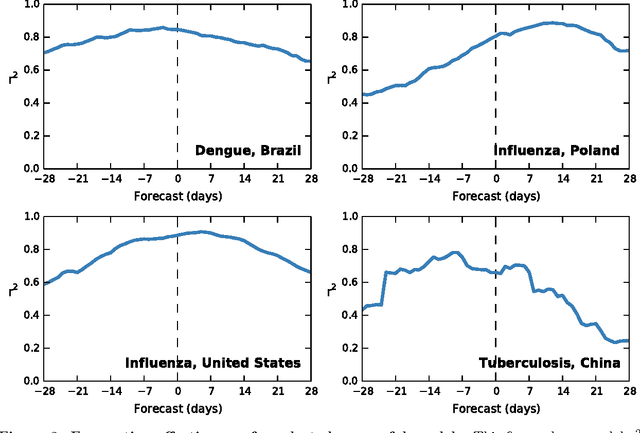
Infectious disease is a leading threat to public health, economic stability, and other key social structures. Efforts to mitigate these impacts depend on accurate and timely monitoring to measure the risk and progress of disease. Traditional, biologically-focused monitoring techniques are accurate but costly and slow; in response, new techniques based on social internet data such as social media and search queries are emerging. These efforts are promising, but important challenges in the areas of scientific peer review, breadth of diseases and countries, and forecasting hamper their operational usefulness. We examine a freely available, open data source for this use: access logs from the online encyclopedia Wikipedia. Using linear models, language as a proxy for location, and a systematic yet simple article selection procedure, we tested 14 location-disease combinations and demonstrate that these data feasibly support an approach that overcomes these challenges. Specifically, our proof-of-concept yields models with $r^2$ up to 0.92, forecasting value up to the 28 days tested, and several pairs of models similar enough to suggest that transferring models from one location to another without re-training is feasible. Based on these preliminary results, we close with a research agenda designed to overcome these challenges and produce a disease monitoring and forecasting system that is significantly more effective, robust, and globally comprehensive than the current state of the art.
* 27 pages; 4 figures; 4 tables. Version 2: Cite McIver & Brownstein and adjust novelty claims accordingly; revise title; various revisions for clarity
Inferring the Origin Locations of Tweets with Quantitative Confidence
Nov 16, 2013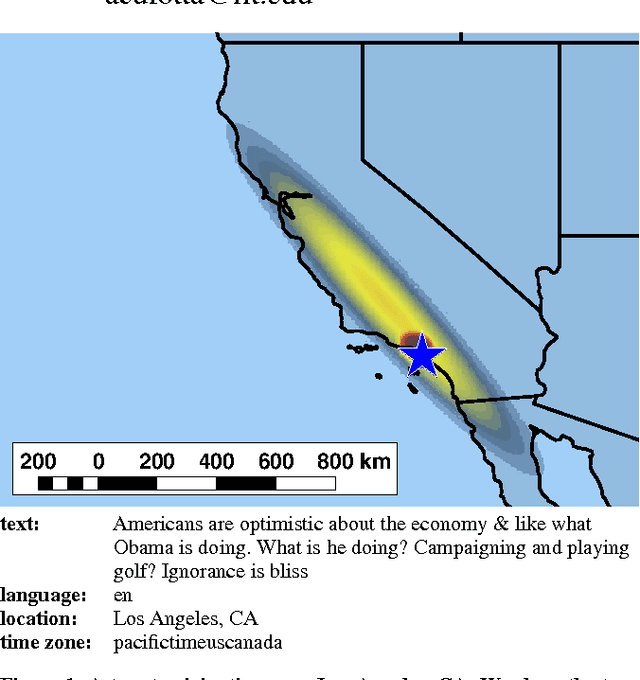
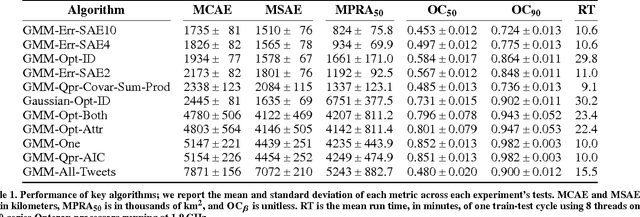
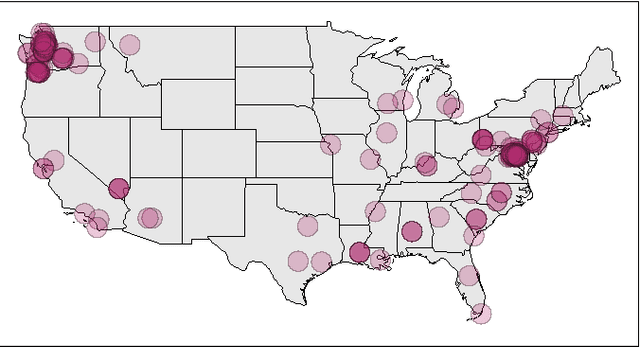
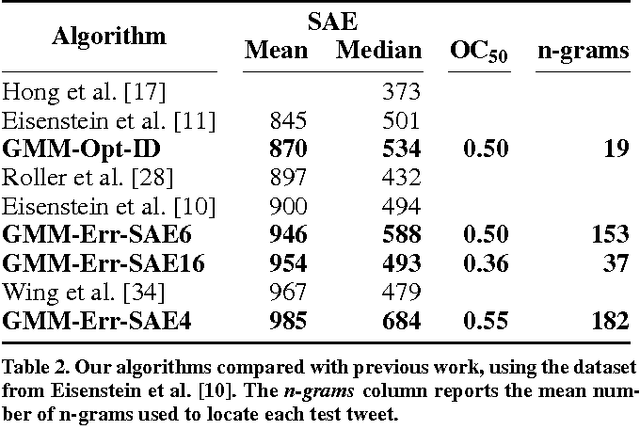
Social Internet content plays an increasingly critical role in many domains, including public health, disaster management, and politics. However, its utility is limited by missing geographic information; for example, fewer than 1.6% of Twitter messages (tweets) contain a geotag. We propose a scalable, content-based approach to estimate the location of tweets using a novel yet simple variant of gaussian mixture models. Further, because real-world applications depend on quantified uncertainty for such estimates, we propose novel metrics of accuracy, precision, and calibration, and we evaluate our approach accordingly. Experiments on 13 million global, comprehensively multi-lingual tweets show that our approach yields reliable, well-calibrated results competitive with previous computationally intensive methods. We also show that a relatively small number of training data are required for good estimates (roughly 30,000 tweets) and models are quite time-invariant (effective on tweets many weeks newer than the training set). Finally, we show that toponyms and languages with small geographic footprint provide the most useful location signals.