 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Anchoring for Training Vision Models
Jun 01, 2024



Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol.
`Eyes of a Hawk and Ears of a Fox': Part Prototype Network for Generalized Zero-Shot Learning
Apr 12, 2024



Current approaches in Generalized Zero-Shot Learning (GZSL) are built upon base models which consider only a single class attribute vector representation over the entire image. This is an oversimplification of the process of novel category recognition, where different regions of the image may have properties from different seen classes and thus have different predominant attributes. With this in mind, we take a fundamentally different approach: a pre-trained Vision-Language detector (VINVL) sensitive to attribute information is employed to efficiently obtain region features. A learned function maps the region features to region-specific attribute attention used to construct class part prototypes. We conduct experiments on a popular GZSL benchmark consisting of the CUB, SUN, and AWA2 datasets where our proposed Part Prototype Network (PPN) achieves promising results when compared with other popular base models. Corresponding ablation studies and analysis show that our approach is highly practical and has a distinct advantage over global attribute attention when localized proposals are available.
Accurate and Scalable Estimation of Epistemic Uncertainty for Graph Neural Networks
Jan 07, 2024



While graph neural networks (GNNs) are widely used for node and graph representation learning tasks, the reliability of GNN uncertainty estimates under distribution shifts remains relatively under-explored. Indeed, while post-hoc calibration strategies can be used to improve in-distribution calibration, they need not also improve calibration under distribution shift. However, techniques which produce GNNs with better intrinsic uncertainty estimates are particularly valuable, as they can always be combined with post-hoc strategies later. Therefore, in this work, we propose G-$\Delta$UQ, a novel training framework designed to improve intrinsic GNN uncertainty estimates. Our framework adapts the principle of stochastic data centering to graph data through novel graph anchoring strategies, and is able to support partially stochastic GNNs. While, the prevalent wisdom is that fully stochastic networks are necessary to obtain reliable estimates, we find that the functional diversity induced by our anchoring strategies when sampling hypotheses renders this unnecessary and allows us to support G-$\Delta$UQ on pretrained models. Indeed, through extensive evaluation under covariate, concept and graph size shifts, we show that G-$\Delta$UQ leads to better calibrated GNNs for node and graph classification. Further, it also improves performance on the uncertainty-based tasks of out-of-distribution detection and generalization gap estimation. Overall, our work provides insights into uncertainty estimation for GNNs, and demonstrates the utility of G-$\Delta$UQ in obtaining reliable estimates.
Transformer-Powered Surrogates Close the ICF Simulation-Experiment Gap with Extremely Limited Data
Dec 06, 2023Recent advances in machine learning, specifically transformer architecture, have led to significant advancements in commercial domains. These powerful models have demonstrated superior capability to learn complex relationships and often generalize better to new data and problems. This paper presents a novel transformer-powered approach for enhancing prediction accuracy in multi-modal output scenarios, where sparse experimental data is supplemented with simulation data. The proposed approach integrates transformer-based architecture with a novel graph-based hyper-parameter optimization technique. The resulting system not only effectively reduces simulation bias, but also achieves superior prediction accuracy compared to the prior method. We demonstrate the efficacy of our approach on inertial confinement fusion experiments, where only 10 shots of real-world data are available, as well as synthetic versions of these experiments.
PAGER: A Framework for Failure Analysis of Deep Regression Models
Sep 20, 2023



Safe deployment of AI models requires proactive detection of potential prediction failures to prevent costly errors. While failure detection in classification problems has received significant attention, characterizing failure modes in regression tasks is more complicated and less explored. Existing approaches rely on epistemic uncertainties or feature inconsistency with the training distribution to characterize model risk. However, we show that uncertainties are necessary but insufficient to accurately characterize failure, owing to the various sources of error. In this paper, we propose PAGER (Principled Analysis of Generalization Errors in Regressors), a framework to systematically detect and characterize failures in deep regression models. Built upon the recently proposed idea of anchoring in deep models, PAGER unifies both epistemic uncertainties and novel, complementary non-conformity scores to organize samples into different risk regimes, thereby providing a comprehensive analysis of model errors. Additionally, we introduce novel metrics for evaluating failure detectors in regression tasks. We demonstrate the effectiveness of PAGER on synthetic and real-world benchmarks. Our results highlight the capability of PAGER to identify regions of accurate generalization and detect failure cases in out-of-distribution and out-of-support scenarios.
CREPE: Learnable Prompting With CLIP Improves Visual Relationship Prediction
Jul 19, 2023In this paper, we explore the potential of Vision-Language Models (VLMs), specifically CLIP, in predicting visual object relationships, which involves interpreting visual features from images into language-based relations. Current state-of-the-art methods use complex graphical models that utilize language cues and visual features to address this challenge. We hypothesize that the strong language priors in CLIP embeddings can simplify these graphical models paving for a simpler approach. We adopt the UVTransE relation prediction framework, which learns the relation as a translational embedding with subject, object, and union box embeddings from a scene. We systematically explore the design of CLIP-based subject, object, and union-box representations within the UVTransE framework and propose CREPE (CLIP Representation Enhanced Predicate Estimation). CREPE utilizes text-based representations for all three bounding boxes and introduces a novel contrastive training strategy to automatically infer the text prompt for union-box. Our approach achieves state-of-the-art performance in predicate estimation, mR@5 27.79, and mR@20 31.95 on the Visual Genome benchmark, achieving a 15.3\% gain in performance over recent state-of-the-art at mR@20. This work demonstrates CLIP's effectiveness in object relation prediction and encourages further research on VLMs in this challenging domain.
Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
Mar 19, 2023



Generative Adversarial Networks (GANs) are notoriously difficult to train especially for complex distributions and with limited data. This has driven the need for tools to audit trained networks in human intelligible format, for example, to identify biases or ensure fairness. Existing GAN audit tools are restricted to coarse-grained, model-data comparisons based on summary statistics such as FID or recall. In this paper, we propose an alternative approach that compares a newly developed GAN against a prior baseline. To this end, we introduce Cross-GAN Auditing (xGA) that, given an established "reference" GAN and a newly proposed "client" GAN, jointly identifies intelligible attributes that are either common across both GANs, novel to the client GAN, or missing from the client GAN. This provides both users and model developers an intuitive assessment of similarity and differences between GANs. We introduce novel metrics to evaluate attribute-based GAN auditing approaches and use these metrics to demonstrate quantitatively that xGA outperforms baseline approaches. We also include qualitative results that illustrate the common, novel and missing attributes identified by xGA from GANs trained on a variety of image datasets.
DOLCE: A Model-Based Probabilistic Diffusion Framework for Limited-Angle CT Reconstruction
Nov 22, 2022Limited-Angle Computed Tomography (LACT) is a non-destructive evaluation technique used in a variety of applications ranging from security to medicine. The limited angle coverage in LACT is often a dominant source of severe artifacts in the reconstructed images, making it a challenging inverse problem. We present DOLCE, a new deep model-based framework for LACT that uses a conditional diffusion model as an image prior. Diffusion models are a recent class of deep generative models that are relatively easy to train due to their implementation as image denoisers. DOLCE can form high-quality images from severely under-sampled data by integrating data-consistency updates with the sampling updates of a diffusion model, which is conditioned on the transformed limited-angle data. We show through extensive experimentation on several challenging real LACT datasets that, the same pre-trained DOLCE model achieves the SOTA performance on drastically different types of images. Additionally, we show that, unlike standard LACT reconstruction methods, DOLCE naturally enables the quantification of the reconstruction uncertainty by generating multiple samples consistent with the measured data.
On-the-fly Object Detection using StyleGAN with CLIP Guidance
Oct 30, 2022We present a fully automated framework for building object detectors on satellite imagery without requiring any human annotation or intervention. We achieve this by leveraging the combined power of modern generative models (e.g., StyleGAN) and recent advances in multi-modal learning (e.g., CLIP). While deep generative models effectively encode the key semantics pertinent to a data distribution, this information is not immediately accessible for downstream tasks, such as object detection. In this work, we exploit CLIP's ability to associate image features with text descriptions to identify neurons in the generator network, which are subsequently used to build detectors on-the-fly.
Contrastive Knowledge-Augmented Meta-Learning for Few-Shot Classification
Jul 25, 2022
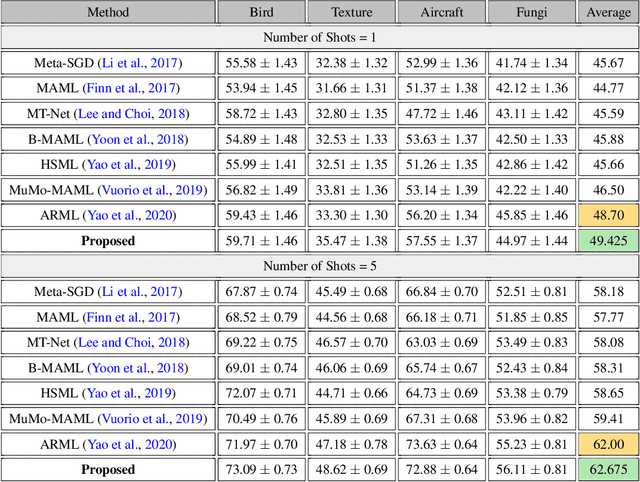
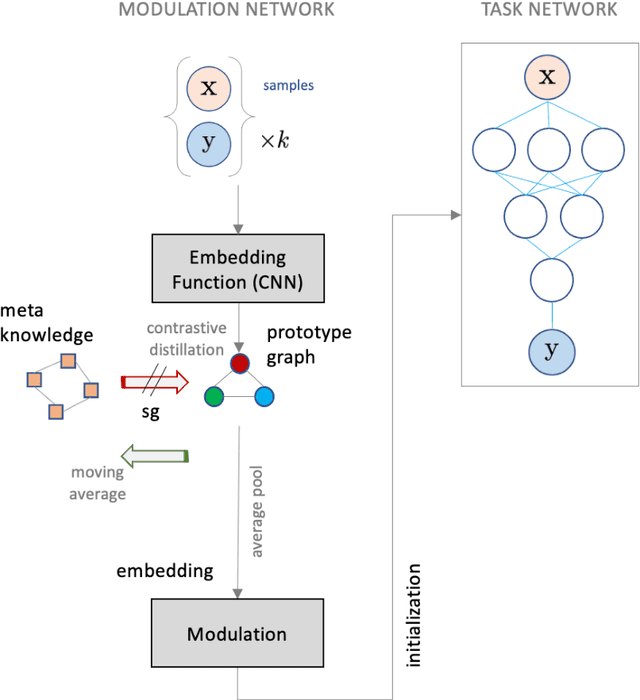
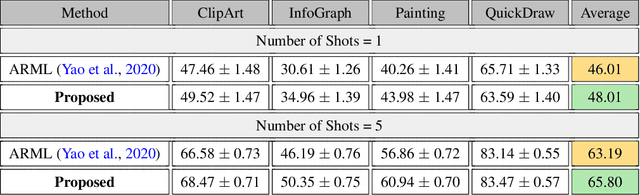
Model agnostic meta-learning algorithms aim to infer priors from several observed tasks that can then be used to adapt to a new task with few examples. Given the inherent diversity of tasks arising in existing benchmarks, recent methods use separate, learnable structure, such as hierarchies or graphs, for enabling task-specific adaptation of the prior. While these approaches have produced significantly better meta learners, our goal is to improve their performance when the heterogeneous task distribution contains challenging distribution shifts and semantic disparities. To this end, we introduce CAML (Contrastive Knowledge-Augmented Meta Learning), a novel approach for knowledge-enhanced few-shot learning that evolves a knowledge graph to effectively encode historical experience, and employs a contrastive distillation strategy to leverage the encoded knowledge for task-aware modulation of the base learner. Using standard benchmarks, we evaluate the performance of CAML in different few-shot learning scenarios. In addition to the standard few-shot task adaptation, we also consider the more challenging multi-domain task adaptation and few-shot dataset generalization settings in our empirical studies. Our results shows that CAML consistently outperforms best known approaches and achieves improved generalization.