 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward AI VIS Co-Scientists: A General and End-to-End Agent Harness for Solving Complex Data Visualization Tasks
May 20, 2026The ability to inspect, interpret, and communicate complex data is crucial for virtually any scientific endeavor, but often requires significant expertise outside the core domain ranging from data management and analysis to visualization design and implementation. We present an end-to-end agentic harness that, based on only the data and a high level description of the tasks, independently designs custom visual analysis applications (VIS apps). This represents an important step towards a general AI co-scientist envisioned by many as an autonomous system that can autonomously execute long horizon tasks based on high-level directions. Our proposed VIS co-scientist is an essential component of this broader AI co-scientist vision: a harness that can autonomously analyze data and design visualization solutions using a collection of agents and specialized skills that coordinate exploratory analysis, plan, configure the environment, implement, validate the interface, and most importantly evaluate the overall task completion. Each stage produces document and instruction artifacts that guide downstream work and enable iterative refinement. We validate this approach on IEEE SciVis Contests spanning multiple science and engineering fields. These contests serve as ideal proving grounds because they encode real-world complexity: ambiguous requirements, diverse data modalities, design trade-offs, and task-driven validation. Given only the data and target tasks, our system autonomously produces functional single-page VIS Apps with verified linked-view behavior, highly customized to domain experts' specified tasks and needs.
Machine Learning-driven Multiscale MD Workflows: The Mini-MuMMI Experience
Jul 10, 2025Computational models have become one of the prevalent methods to model complex phenomena. To accurately model complex interactions, such as detailed biomolecular interactions, scientists often rely on multiscale models comprised of several internal models operating at difference scales, ranging from microscopic to macroscopic length and time scales. Bridging the gap between different time and length scales has historically been challenging but the advent of newer machine learning (ML) approaches has shown promise for tackling that task. Multiscale models require massive amounts of computational power and a powerful workflow management system. Orchestrating ML-driven multiscale studies on parallel systems with thousands of nodes is challenging, the workflow must schedule, allocate and control thousands of simulations operating at different scales. Here, we discuss the massively parallel Multiscale Machine-Learned Modeling Infrastructure (MuMMI), a multiscale workflow management infrastructure, that can orchestrate thousands of molecular dynamics (MD) simulations operating at different timescales, spanning from millisecond to nanosecond. More specifically, we introduce a novel version of MuMMI called "mini-MuMMI". Mini-MuMMI is a curated version of MuMMI designed to run on modest HPC systems or even laptops whereas MuMMI requires larger HPC systems. We demonstrate mini-MuMMI utility by exploring RAS-RAF membrane interactions and discuss the different challenges behind the generalization of multiscale workflows and how mini-MuMMI can be leveraged to target a broader range of applications outside of MD and RAS-RAF interactions.
ParaView-MCP: An Autonomous Visualization Agent with Direct Tool Use
May 11, 2025While powerful and well-established, tools like ParaView present a steep learning curve that discourages many potential users. This work introduces ParaView-MCP, an autonomous agent that integrates modern multimodal large language models (MLLMs) with ParaView to not only lower the barrier to entry but also augment ParaView with intelligent decision support. By leveraging the state-of-the-art reasoning, command execution, and vision capabilities of MLLMs, ParaView-MCP enables users to interact with ParaView through natural language and visual inputs. Specifically, our system adopted the Model Context Protocol (MCP) - a standardized interface for model-application communication - that facilitates direct interaction between MLLMs with ParaView's Python API to allow seamless information exchange between the user, the language model, and the visualization tool itself. Furthermore, by implementing a visual feedback mechanism that allows the agent to observe the viewport, we unlock a range of new capabilities, including recreating visualizations from examples, closed-loop visualization parameter updates based on user-defined goals, and even cross-application collaboration involving multiple tools. Broadly, we believe such an agent-driven visualization paradigm can profoundly change the way we interact with visualization tools. We expect a significant uptake in the development of such visualization tools, in both visualization research and industry.
AVA: Towards Autonomous Visualization Agents through Visual Perception-Driven Decision-Making
Dec 07, 2023With recent advances in multi-modal foundation models, the previously text-only large language models (LLM) have evolved to incorporate visual input, opening up unprecedented opportunities for various applications in visualization. Our work explores the utilization of the visual perception ability of multi-modal LLMs to develop Autonomous Visualization Agents (AVAs) that can interpret and accomplish user-defined visualization objectives through natural language. We propose the first framework for the design of AVAs and present several usage scenarios intended to demonstrate the general applicability of the proposed paradigm. The addition of visual perception allows AVAs to act as the virtual visualization assistant for domain experts who may lack the knowledge or expertise in fine-tuning visualization outputs. Our preliminary exploration and proof-of-concept agents suggest that this approach can be widely applicable whenever the choices of appropriate visualization parameters require the interpretation of previous visual output. Feedback from unstructured interviews with experts in AI research, medical visualization, and radiology has been incorporated, highlighting the practicality and potential of AVAs. Our study indicates that AVAs represent a general paradigm for designing intelligent visualization systems that can achieve high-level visualization goals, which pave the way for developing expert-level visualization agents in the future.
Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
Mar 19, 2023



Generative Adversarial Networks (GANs) are notoriously difficult to train especially for complex distributions and with limited data. This has driven the need for tools to audit trained networks in human intelligible format, for example, to identify biases or ensure fairness. Existing GAN audit tools are restricted to coarse-grained, model-data comparisons based on summary statistics such as FID or recall. In this paper, we propose an alternative approach that compares a newly developed GAN against a prior baseline. To this end, we introduce Cross-GAN Auditing (xGA) that, given an established "reference" GAN and a newly proposed "client" GAN, jointly identifies intelligible attributes that are either common across both GANs, novel to the client GAN, or missing from the client GAN. This provides both users and model developers an intuitive assessment of similarity and differences between GANs. We introduce novel metrics to evaluate attribute-based GAN auditing approaches and use these metrics to demonstrate quantitatively that xGA outperforms baseline approaches. We also include qualitative results that illustrate the common, novel and missing attributes identified by xGA from GANs trained on a variety of image datasets.
Single Model Uncertainty Estimation via Stochastic Data Centering
Jul 14, 2022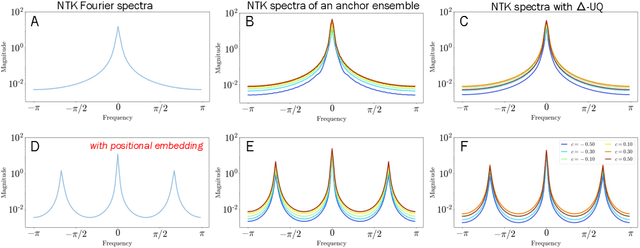
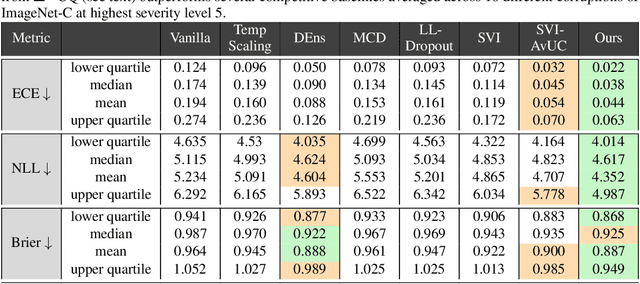

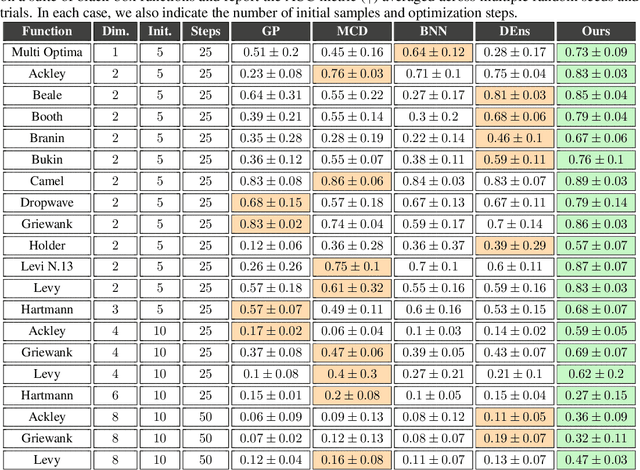
We are interested in estimating the uncertainties of deep neural networks, which play an important role in many scientific and engineering problems. In this paper, we present a striking new finding that an ensemble of neural networks with the same weight initialization, trained on datasets that are shifted by a constant bias gives rise to slightly inconsistent trained models, where the differences in predictions are a strong indicator of epistemic uncertainties. Using the neural tangent kernel (NTK), we demonstrate that this phenomena occurs in part because the NTK is not shift-invariant. Since this is achieved via a trivial input transformation, we show that it can therefore be approximated using just a single neural network -- using a technique that we call $\Delta-$UQ -- that estimates uncertainty around prediction by marginalizing out the effect of the biases. We show that $\Delta-$UQ's uncertainty estimates are superior to many of the current methods on a variety of benchmarks -- outlier rejection, calibration under distribution shift, and sequential design optimization of black box functions.
Identifying Orientation-specific Lipid-protein Fingerprints using Deep Learning
Jul 14, 2022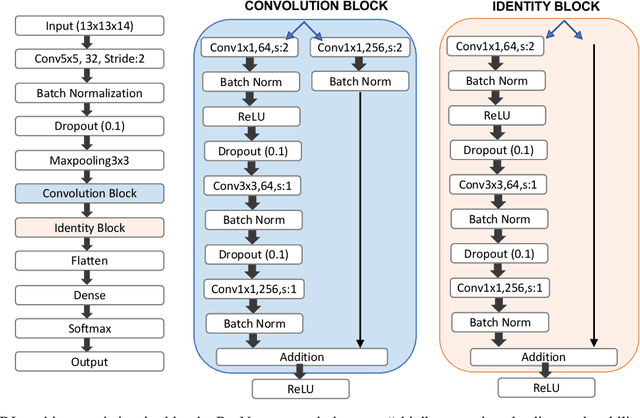
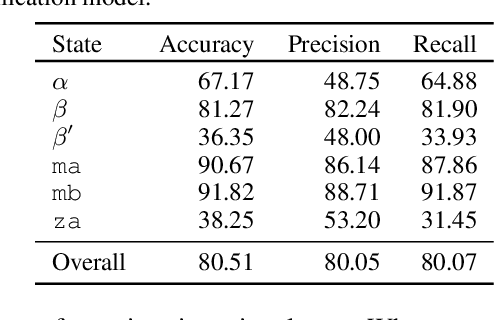
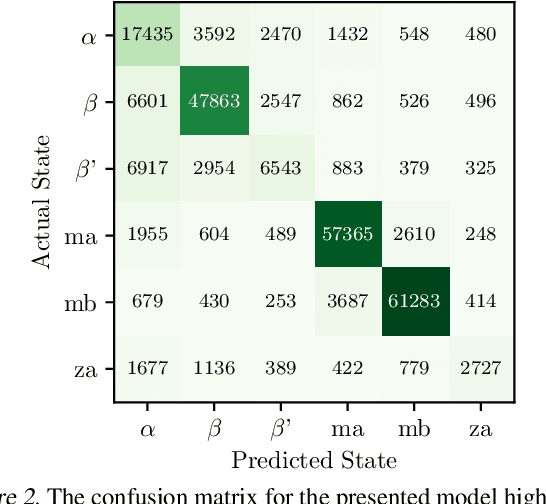
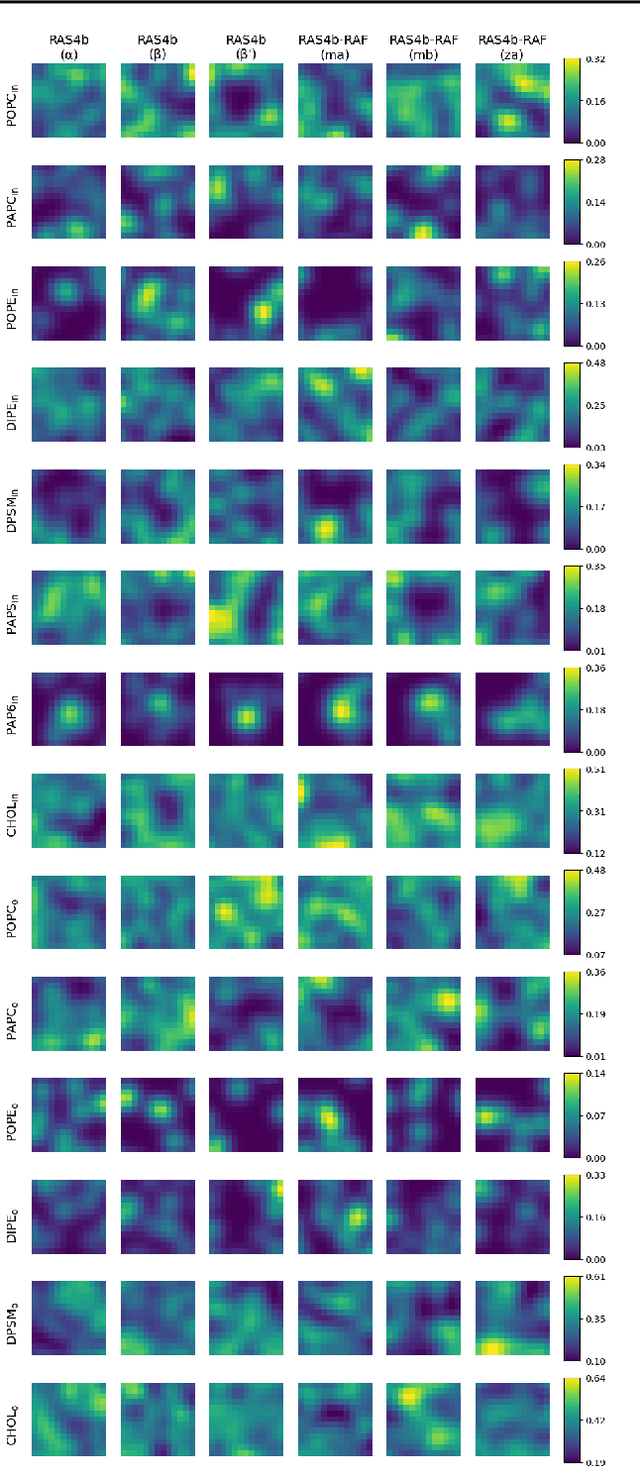
Improved understanding of the relation between the behavior of RAS and RAF proteins and the local lipid environment in the cell membrane is critical for getting insights into the mechanisms underlying cancer formation. In this work, we employ deep learning (DL) to learn this relationship by predicting protein orientational states of RAS and RAS-RAF protein complexes with respect to the lipid membrane based on the lipid densities around the protein domains from coarse-grained (CG) molecular dynamics (MD) simulations. Our DL model can predict six protein states with an overall accuracy of over 80%. The findings of this work offer new insights into how the proteins modulate the lipid environment, which in turn may assist designing novel therapies to regulate such interactions in the mechanisms associated with cancer development.
Emerging Patterns in the Continuum Representation of Protein-Lipid Fingerprints
Jul 09, 2022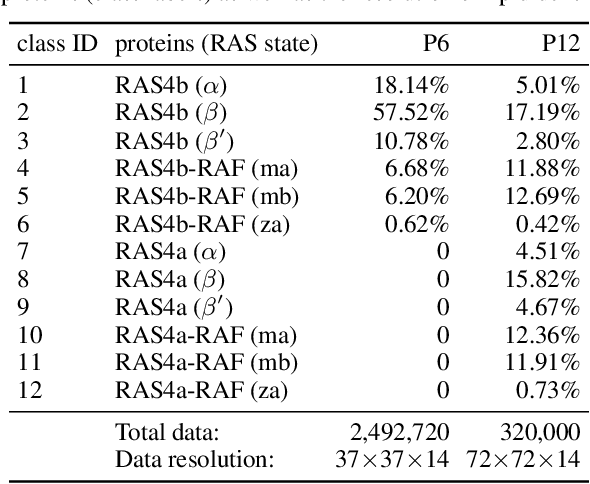
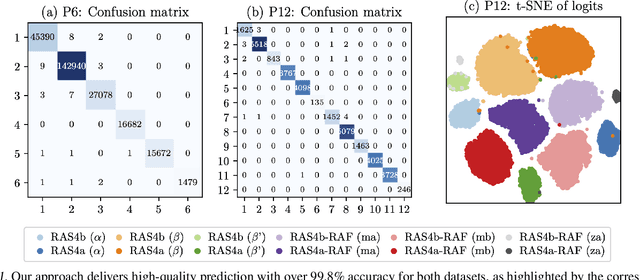
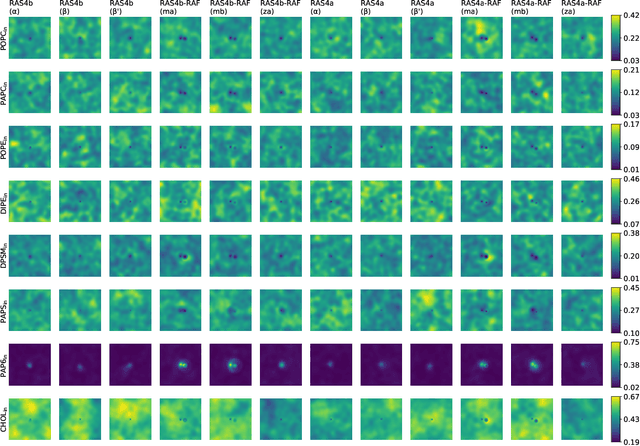
Capturing intricate biological phenomena often requires multiscale modeling where coarse and inexpensive models are developed using limited components of expensive and high-fidelity models. Here, we consider such a multiscale framework in the context of cancer biology and address the challenge of evaluating the descriptive capabilities of a continuum model developed using 1-dimensional statistics from a molecular dynamics model. Using deep learning, we develop a highly predictive classification model that identifies complex and emergent behavior from the continuum model. With over 99.9% accuracy demonstrated for two simulations, our approach confirms the existence of protein-specific "lipid fingerprints", i.e. spatial rearrangements of lipids in response to proteins of interest. Through this demonstration, our model also provides external validation of the continuum model, affirms the value of such multiscale modeling, and can foster new insights through further analysis of these fingerprints.
Models Out of Line: A Fourier Lens on Distribution Shift Robustness
Jul 08, 2022
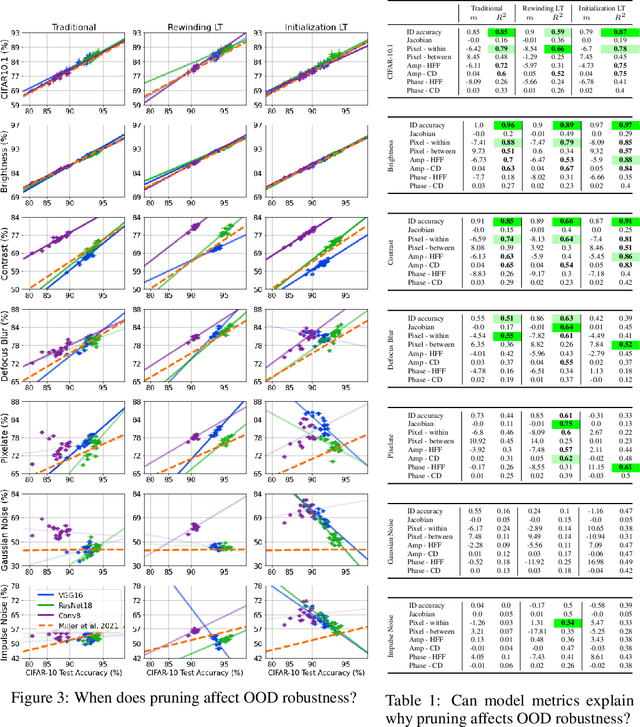

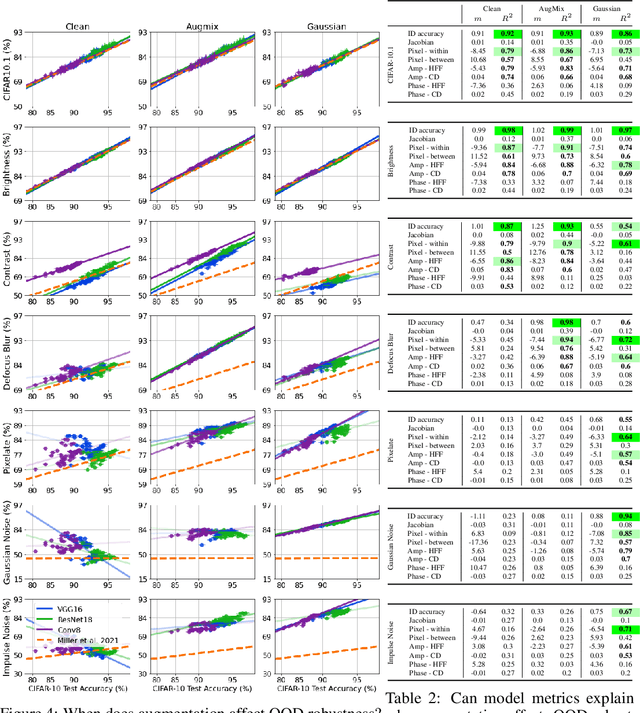
Improving the accuracy of deep neural networks (DNNs) on out-of-distribution (OOD) data is critical to an acceptance of deep learning (DL) in real world applications. It has been observed that accuracies on in-distribution (ID) versus OOD data follow a linear trend and models that outperform this baseline are exceptionally rare (and referred to as "effectively robust"). Recently, some promising approaches have been developed to improve OOD robustness: model pruning, data augmentation, and ensembling or zero-shot evaluating large pretrained models. However, there still is no clear understanding of the conditions on OOD data and model properties that are required to observe effective robustness. We approach this issue by conducting a comprehensive empirical study of diverse approaches that are known to impact OOD robustness on a broad range of natural and synthetic distribution shifts of CIFAR-10 and ImageNet. In particular, we view the "effective robustness puzzle" through a Fourier lens and ask how spectral properties of both models and OOD data influence the corresponding effective robustness. We find this Fourier lens offers some insight into why certain robust models, particularly those from the CLIP family, achieve OOD robustness. However, our analysis also makes clear that no known metric is consistently the best explanation (or even a strong explanation) of OOD robustness. Thus, to aid future research into the OOD puzzle, we address the gap in publicly-available models with effective robustness by introducing a set of pretrained models--RobustNets--with varying levels of OOD robustness.
"Understanding Robustness Lottery": A Comparative Visual Analysis of Neural Network Pruning Approaches
Jun 16, 2022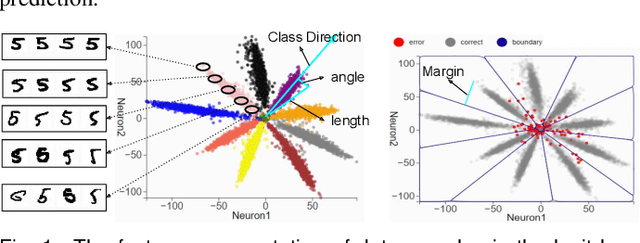

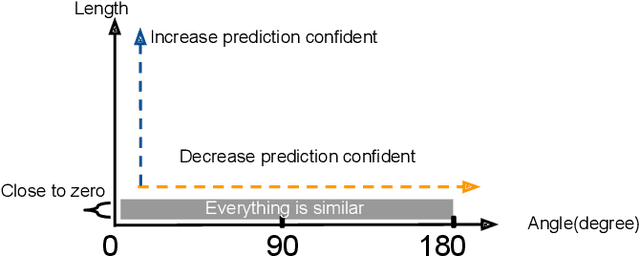
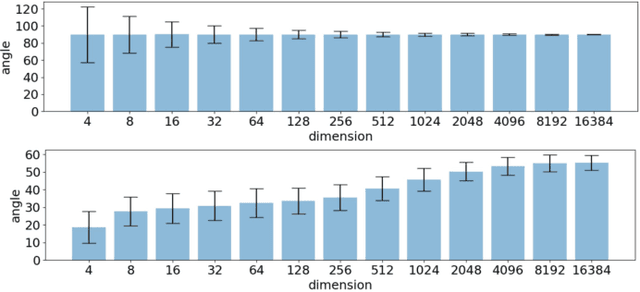
Deep learning approaches have provided state-of-the-art performance in many applications by relying on extremely large and heavily overparameterized neural networks. However, such networks have been shown to be very brittle, not generalize well to new uses cases, and are often difficult if not impossible to deploy on resources limited platforms. Model pruning, i.e., reducing the size of the network, is a widely adopted strategy that can lead to more robust and generalizable network -- usually orders of magnitude smaller with the same or even improved performance. While there exist many heuristics for model pruning, our understanding of the pruning process remains limited. Empirical studies show that some heuristics improve performance while others can make models more brittle or have other side effects. This work aims to shed light on how different pruning methods alter the network's internal feature representation, and the corresponding impact on model performance. To provide a meaningful comparison and characterization of model feature space, we use three geometric metrics that are decomposed from the common adopted classification loss. With these metrics, we design a visualization system to highlight the impact of pruning on model prediction as well as the latent feature embedding. The proposed tool provides an environment for exploring and studying differences among pruning methods and between pruned and original model. By leveraging our visualization, the ML researchers can not only identify samples that are fragile to model pruning and data corruption but also obtain insights and explanations on how some pruned models achieve superior robustness performance.