 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
Mar 29, 2024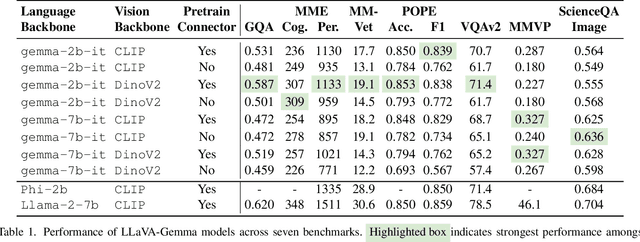
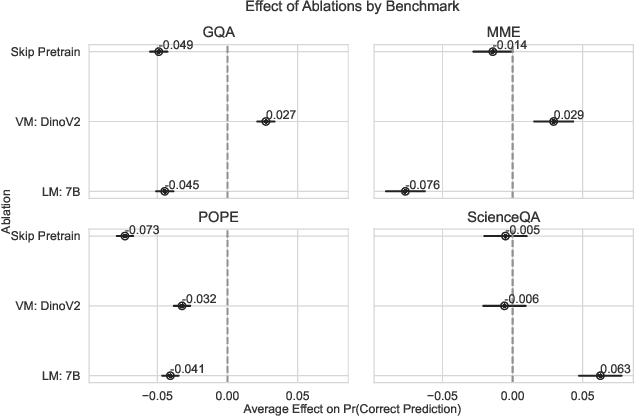

We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs. In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations, but fail to improve past the current comparably sized SOTA models. Closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code and weights for our models for the LLaVA-Gemma models.
Transformer-Powered Surrogates Close the ICF Simulation-Experiment Gap with Extremely Limited Data
Dec 06, 2023Recent advances in machine learning, specifically transformer architecture, have led to significant advancements in commercial domains. These powerful models have demonstrated superior capability to learn complex relationships and often generalize better to new data and problems. This paper presents a novel transformer-powered approach for enhancing prediction accuracy in multi-modal output scenarios, where sparse experimental data is supplemented with simulation data. The proposed approach integrates transformer-based architecture with a novel graph-based hyper-parameter optimization technique. The resulting system not only effectively reduces simulation bias, but also achieves superior prediction accuracy compared to the prior method. We demonstrate the efficacy of our approach on inertial confinement fusion experiments, where only 10 shots of real-world data are available, as well as synthetic versions of these experiments.
Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
Mar 19, 2023



Generative Adversarial Networks (GANs) are notoriously difficult to train especially for complex distributions and with limited data. This has driven the need for tools to audit trained networks in human intelligible format, for example, to identify biases or ensure fairness. Existing GAN audit tools are restricted to coarse-grained, model-data comparisons based on summary statistics such as FID or recall. In this paper, we propose an alternative approach that compares a newly developed GAN against a prior baseline. To this end, we introduce Cross-GAN Auditing (xGA) that, given an established "reference" GAN and a newly proposed "client" GAN, jointly identifies intelligible attributes that are either common across both GANs, novel to the client GAN, or missing from the client GAN. This provides both users and model developers an intuitive assessment of similarity and differences between GANs. We introduce novel metrics to evaluate attribute-based GAN auditing approaches and use these metrics to demonstrate quantitatively that xGA outperforms baseline approaches. We also include qualitative results that illustrate the common, novel and missing attributes identified by xGA from GANs trained on a variety of image datasets.
GANterfactual-RL: Understanding Reinforcement Learning Agents' Strategies through Visual Counterfactual Explanations
Feb 24, 2023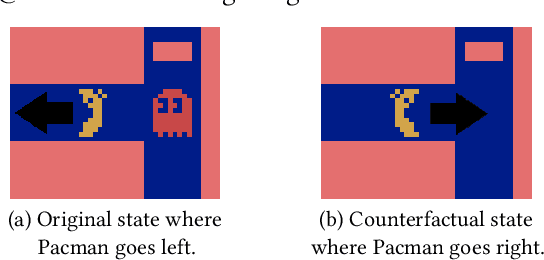

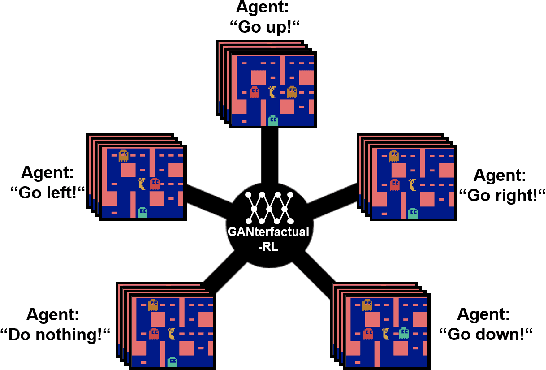

Counterfactual explanations are a common tool to explain artificial intelligence models. For Reinforcement Learning (RL) agents, they answer "Why not?" or "What if?" questions by illustrating what minimal change to a state is needed such that an agent chooses a different action. Generating counterfactual explanations for RL agents with visual input is especially challenging because of their large state spaces and because their decisions are part of an overarching policy, which includes long-term decision-making. However, research focusing on counterfactual explanations, specifically for RL agents with visual input, is scarce and does not go beyond identifying defective agents. It is unclear whether counterfactual explanations are still helpful for more complex tasks like analyzing the learned strategies of different agents or choosing a fitting agent for a specific task. We propose a novel but simple method to generate counterfactual explanations for RL agents by formulating the problem as a domain transfer problem which allows the use of adversarial learning techniques like StarGAN. Our method is fully model-agnostic and we demonstrate that it outperforms the only previous method in several computational metrics. Furthermore, we show in a user study that our method performs best when analyzing which strategies different agents pursue.
Deep Generative Multimedia Children's Literature
Sep 27, 2022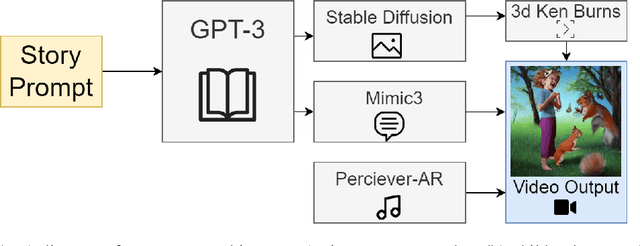
The popularity in Deep Learning (DL) based creative endeavours continues to grow without any signs of slowing down. Unpredictable to many a decade ago, the achievements of DL models in a variety of creative domains are spectacular in their own right. In this work, I combine multiple publicly available DL models to create a fully automated system in the generation of multimedia entertainment. The framework I propose is general enough for any genre of entertainment, but I focus on the task of children's video literature production.
Contrastive Identification of Covariate Shift in Image Data
Aug 19, 2021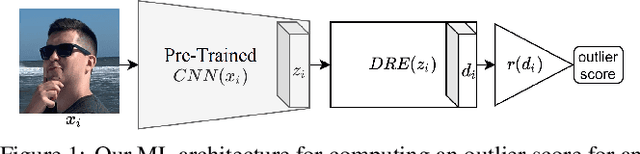

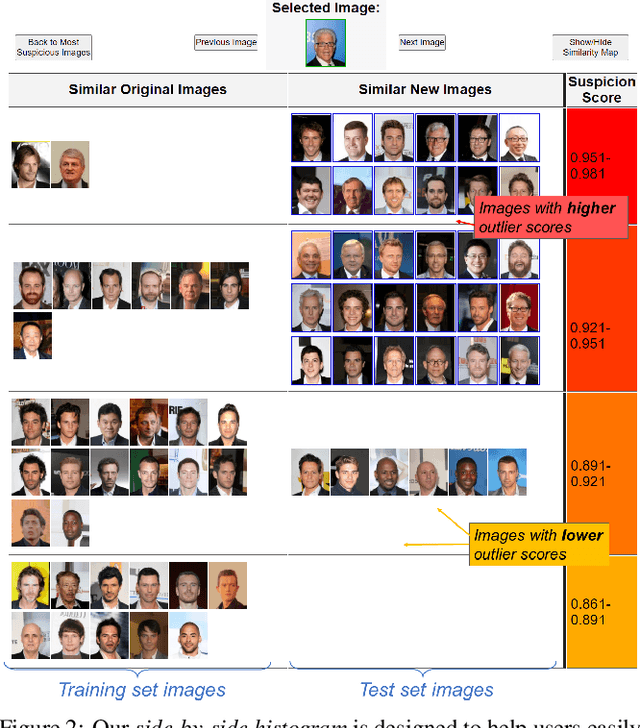
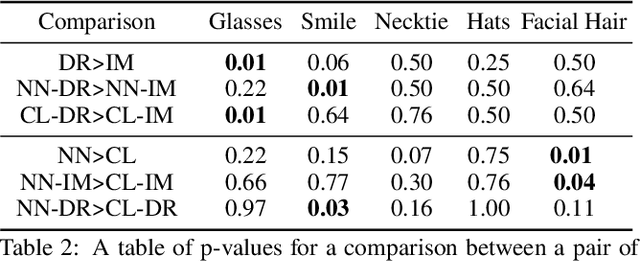
Identifying covariate shift is crucial for making machine learning systems robust in the real world and for detecting training data biases that are not reflected in test data. However, detecting covariate shift is challenging, especially when the data consists of high-dimensional images, and when multiple types of localized covariate shift affect different subspaces of the data. Although automated techniques can be used to detect the existence of covariate shift, our goal is to help human users characterize the extent of covariate shift in large image datasets with interfaces that seamlessly integrate information obtained from the detection algorithms. In this paper, we design and evaluate a new visual interface that facilitates the comparison of the local distributions of training and test data. We conduct a quantitative user study on multi-attribute facial data to compare two different learned low-dimensional latent representations (pretrained ImageNet CNN vs. density ratio) and two user analytic workflows (nearest-neighbor vs. cluster-to-cluster). Our results indicate that the latent representation of our density ratio model, combined with a nearest-neighbor comparison, is the most effective at helping humans identify covariate shift.
Counterfactual State Explanations for Reinforcement Learning Agents via Generative Deep Learning
Jan 29, 2021



Counterfactual explanations, which deal with "why not?" scenarios, can provide insightful explanations to an AI agent's behavior. In this work, we focus on generating counterfactual explanations for deep reinforcement learning (RL) agents which operate in visual input environments like Atari. We introduce counterfactual state explanations, a novel example-based approach to counterfactual explanations based on generative deep learning. Specifically, a counterfactual state illustrates what minimal change is needed to an Atari game image such that the agent chooses a different action. We also evaluate the effectiveness of counterfactual states on human participants who are not machine learning experts. Our first user study investigates if humans can discern if the counterfactual state explanations are produced by the actual game or produced by a generative deep learning approach. Our second user study investigates if counterfactual state explanations can help non-expert participants identify a flawed agent; we compare against a baseline approach based on a nearest neighbor explanation which uses images from the actual game. Our results indicate that counterfactual state explanations have sufficient fidelity to the actual game images to enable non-experts to more effectively identify a flawed RL agent compared to the nearest neighbor baseline and to having no explanation at all.
* Full source code available at https://github.com/mattolson93/counterfactual-state-explanations
Counterfactual States for Atari Agents via Generative Deep Learning
Sep 27, 2019
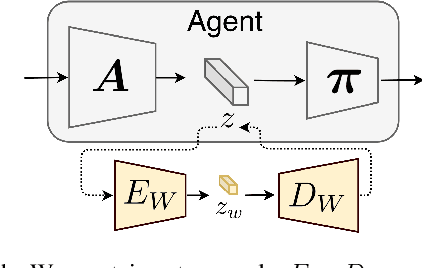
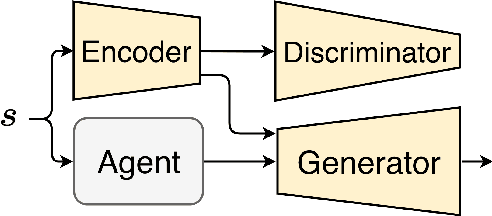

Although deep reinforcement learning agents have produced impressive results in many domains, their decision making is difficult to explain to humans. To address this problem, past work has mainly focused on explaining why an action was chosen in a given state. A different type of explanation that is useful is a counterfactual, which deals with "what if?" scenarios. In this work, we introduce the concept of a counterfactual state to help humans gain a better understanding of what would need to change (minimally) in an Atari game image for the agent to choose a different action. We introduce a novel method to create counterfactual states from a generative deep learning architecture. In addition, we evaluate the effectiveness of counterfactual states on human participants who are not machine learning experts. Our user study results suggest that our generated counterfactual states are useful in helping non-expert participants gain a better understanding of an agent's decision making process.