 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLM-Compress-Bench: Benchmarking the Broader Impact of Large Vision-Language Model Compression
Mar 06, 2025Despite recent efforts in understanding the compression impact on large language models (LLMs) in terms of their downstream task performance and trustworthiness on relatively simpler uni-modal benchmarks (for example, question answering, common sense reasoning), their detailed study on multi-modal Large Vision-Language Models (LVLMs) is yet to be unveiled. Towards mitigating this gap, we present LVLM-Compress-Bench, a framework to first thoroughly study the broad impact of compression on the generative performance of LVLMs with multi-modal input driven tasks. In specific, we consider two major classes of compression for autoregressive models, namely KV cache and weight compression, for the dynamically growing intermediate cache and static weights, respectively. We use four LVLM variants of the popular LLaVA framework to present our analysis via integrating various state-of-the-art KV and weight compression methods including uniform, outlier-reduced, and group quantization for the KV cache and weights. With this framework we demonstrate on ten different multi-modal datasets with different capabilities including recognition, knowledge, language generation, spatial awareness, visual reasoning, hallucination and visual illusion identification, toxicity, stereotypes and bias. In specific, our framework demonstrates the compression impact on both general and ethically critical metrics leveraging a combination of real world and synthetic datasets to encompass diverse societal intersectional attributes. Extensive experimental evaluations yield diverse and intriguing observations on the behavior of LVLMs at different quantization budget of KV and weights, in both maintaining and losing performance as compared to the baseline model with FP16 data format. Code will be open-sourced at https://github.com/opengear-project/LVLM-compress-bench.
LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
Mar 29, 2024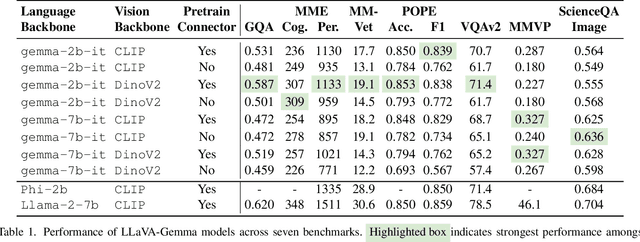
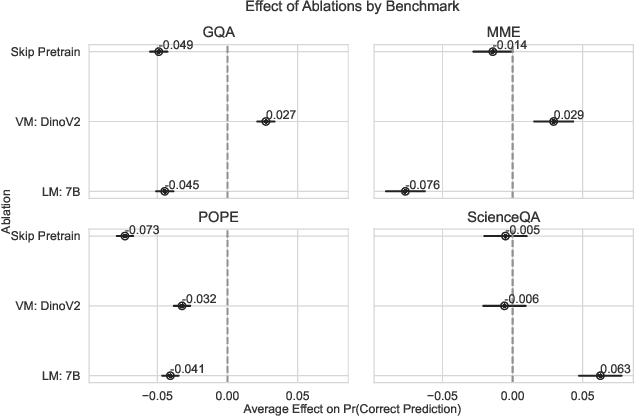

We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs. In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations, but fail to improve past the current comparably sized SOTA models. Closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code and weights for our models for the LLaVA-Gemma models.