 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Reasoning Flaws in Planning-Based RL Using Tree Explanations
Sep 28, 2021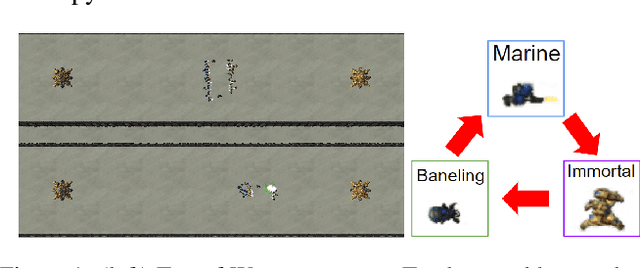

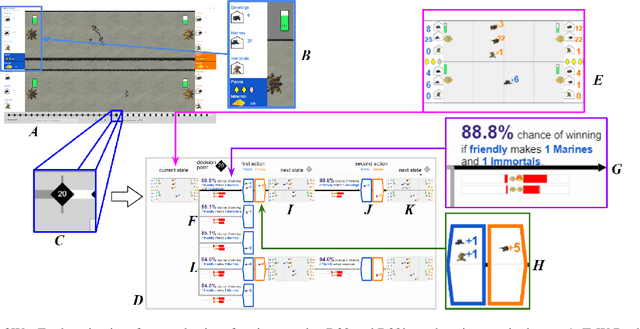
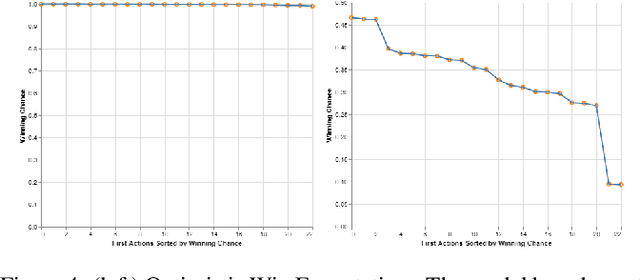
Enabling humans to identify potential flaws in an agent's decision making is an important Explainable AI application. We consider identifying such flaws in a planning-based deep reinforcement learning (RL) agent for a complex real-time strategy game. In particular, the agent makes decisions via tree search using a learned model and evaluation function over interpretable states and actions. This gives the potential for humans to identify flaws at the level of reasoning steps in the tree, even if the entire reasoning process is too complex to understand. However, it is unclear whether humans will be able to identify such flaws due to the size and complexity of trees. We describe a user interface and case study, where a small group of AI experts and developers attempt to identify reasoning flaws due to inaccurate agent learning. Overall, the interface allowed the group to identify a number of significant flaws of varying types, demonstrating the promise of this approach.
Counterfactual State Explanations for Reinforcement Learning Agents via Generative Deep Learning
Jan 29, 2021



Counterfactual explanations, which deal with "why not?" scenarios, can provide insightful explanations to an AI agent's behavior. In this work, we focus on generating counterfactual explanations for deep reinforcement learning (RL) agents which operate in visual input environments like Atari. We introduce counterfactual state explanations, a novel example-based approach to counterfactual explanations based on generative deep learning. Specifically, a counterfactual state illustrates what minimal change is needed to an Atari game image such that the agent chooses a different action. We also evaluate the effectiveness of counterfactual states on human participants who are not machine learning experts. Our first user study investigates if humans can discern if the counterfactual state explanations are produced by the actual game or produced by a generative deep learning approach. Our second user study investigates if counterfactual state explanations can help non-expert participants identify a flawed agent; we compare against a baseline approach based on a nearest neighbor explanation which uses images from the actual game. Our results indicate that counterfactual state explanations have sufficient fidelity to the actual game images to enable non-experts to more effectively identify a flawed RL agent compared to the nearest neighbor baseline and to having no explanation at all.
* Full source code available at https://github.com/mattolson93/counterfactual-state-explanations