 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Value: CHECKLIST for Testing Inferences in Planning-Based RL
Jun 07, 2022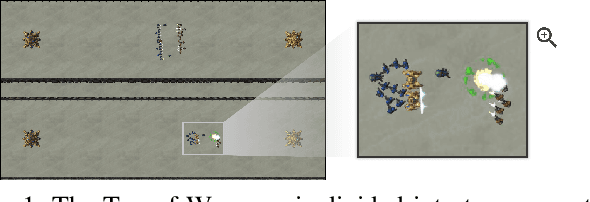
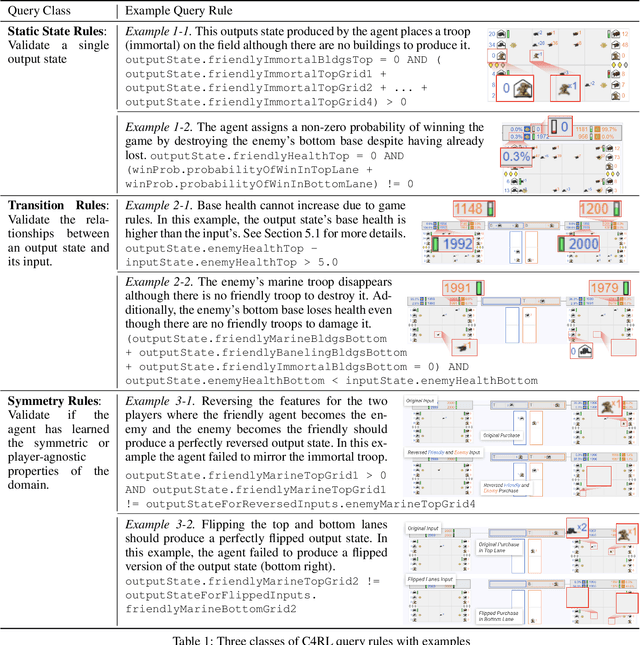
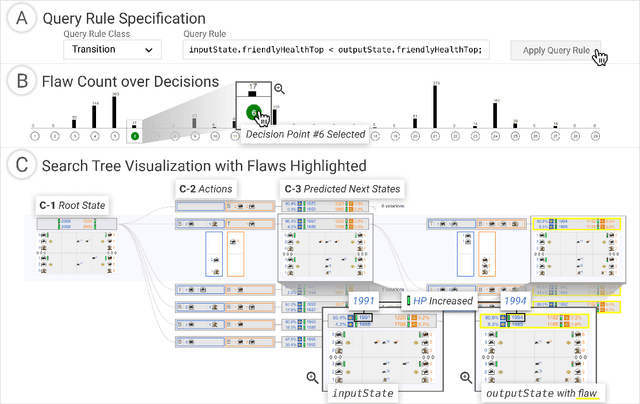
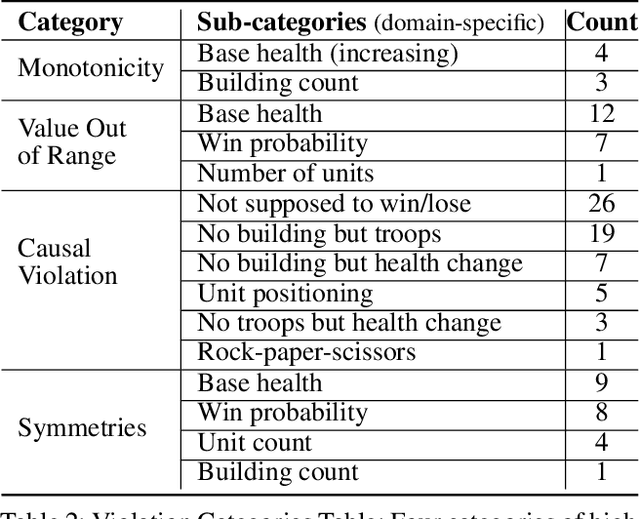
Reinforcement learning (RL) agents are commonly evaluated via their expected value over a distribution of test scenarios. Unfortunately, this evaluation approach provides limited evidence for post-deployment generalization beyond the test distribution. In this paper, we address this limitation by extending the recent CheckList testing methodology from natural language processing to planning-based RL. Specifically, we consider testing RL agents that make decisions via online tree search using a learned transition model and value function. The key idea is to improve the assessment of future performance via a CheckList approach for exploring and assessing the agent's inferences during tree search. The approach provides the user with an interface and general query-rule mechanism for identifying potential inference flaws and validating expected inference invariances. We present a user study involving knowledgeable AI researchers using the approach to evaluate an agent trained to play a complex real-time strategy game. The results show the approach is effective in allowing users to identify previously-unknown flaws in the agent's reasoning. In addition, our analysis provides insight into how AI experts use this type of testing approach, which may help improve future instantiations.
Identifying Reasoning Flaws in Planning-Based RL Using Tree Explanations
Sep 28, 2021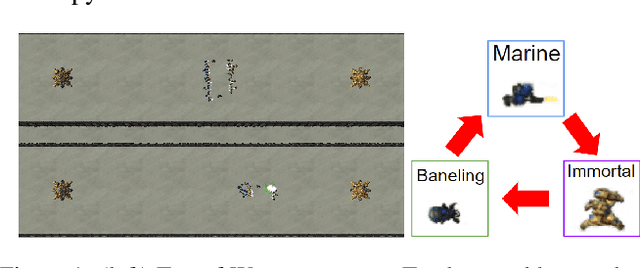

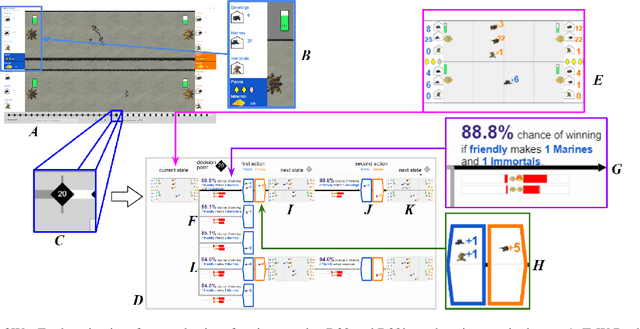
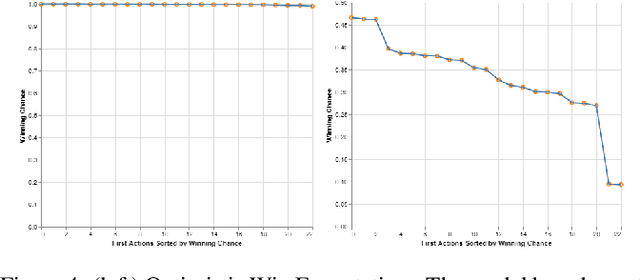
Enabling humans to identify potential flaws in an agent's decision making is an important Explainable AI application. We consider identifying such flaws in a planning-based deep reinforcement learning (RL) agent for a complex real-time strategy game. In particular, the agent makes decisions via tree search using a learned model and evaluation function over interpretable states and actions. This gives the potential for humans to identify flaws at the level of reasoning steps in the tree, even if the entire reasoning process is too complex to understand. However, it is unclear whether humans will be able to identify such flaws due to the size and complexity of trees. We describe a user interface and case study, where a small group of AI experts and developers attempt to identify reasoning flaws due to inaccurate agent learning. Overall, the interface allowed the group to identify a number of significant flaws of varying types, demonstrating the promise of this approach.
Explaining Reinforcement Learning to Mere Mortals: An Empirical Study
Mar 22, 2019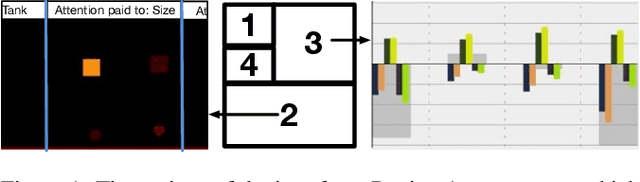
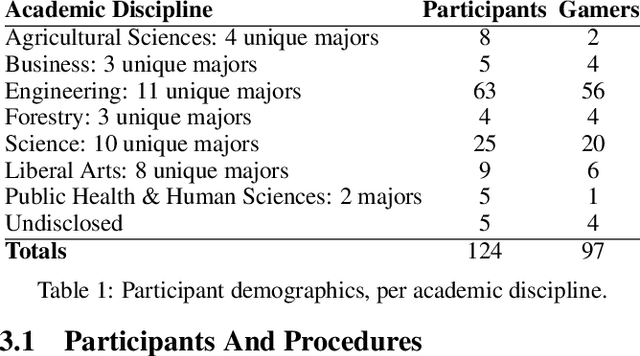
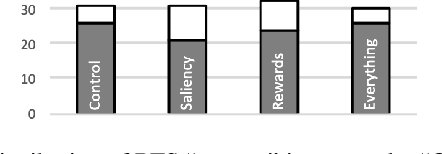
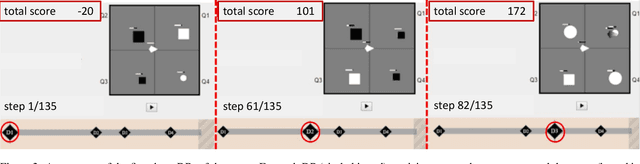
We present a user study to investigate the impact of explanations on non-experts' understanding of reinforcement learning (RL) agents. We investigate both a common RL visualization, saliency maps (the focus of attention), and a more recent explanation type, reward-decomposition bars (predictions of future types of rewards). We designed a 124 participant, four-treatment experiment to compare participants' mental models of an RL agent in a simple Real-Time Strategy (RTS) game. Our results show that the combination of both saliency and reward bars were needed to achieve a statistically significant improvement in mental model score over the control. In addition, our qualitative analysis of the data reveals a number of effects for further study.
Multi-Label Classifier Chains for Bird Sound
May 29, 2013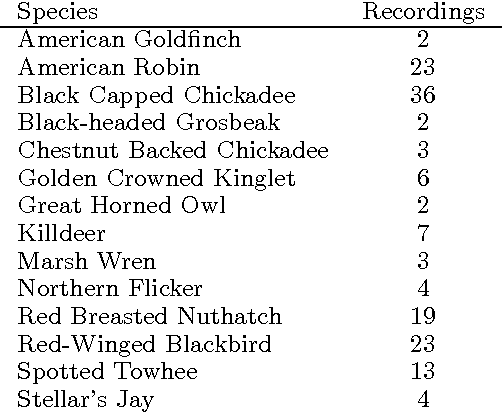


Bird sound data collected with unattended microphones for automatic surveys, or mobile devices for citizen science, typically contain multiple simultaneously vocalizing birds of different species. However, few works have considered the multi-label structure in birdsong. We propose to use an ensemble of classifier chains combined with a histogram-of-segments representation for multi-label classification of birdsong. The proposed method is compared with binary relevance and three multi-instance multi-label learning (MIML) algorithms from prior work (which focus more on structure in the sound, and less on structure in the label sets). Experiments are conducted on two real-world birdsong datasets, and show that the proposed method usually outperforms binary relevance (using the same features and base-classifier), and is better in some cases and worse in others compared to the MIML algorithms.